Choix des lecteurs





Articles populaires
Yandex.Disk est l'un des rares services Yandex dont il fait partie Logiciel pour le bureau. Et l'un de ses composants les plus importants est l'algorithme de synchronisation fichiers locaux avec leur copie dans le cloud. Nous avons récemment dû le changer complètement. Si l'ancienne version pouvait difficilement digérer même plusieurs dizaines de milliers de fichiers et, de plus, ne réagissait pas assez rapidement à certaines actions "complexes" des utilisateurs, la nouvelle, utilisant les mêmes ressources, fait face à des centaines de milliers de fichiers.
Dans cet article, je vais vous expliquer pourquoi cela s'est produit : ce que nous n'aurions pas pu prévoir lorsque nous avons créé la première version du logiciel Yandex.Disk, et comment nous en avons créé une nouvelle.
Tout d'abord, sur la tâche même de synchronisation. Techniquement parlant, cela consiste à conserver le même ensemble de fichiers dans le dossier Yandex.Disk sur l'ordinateur de l'utilisateur et dans le cloud. C'est-à-dire que les actions de l'utilisateur telles que renommer, supprimer, copier, ajouter et modifier des fichiers doivent être automatiquement synchronisées avec le cloud.
La situation peut devenir encore plus compliquée si plusieurs utilisateurs travaillent avec le même compte en même temps ou s'ils ont un dossier partagé. Et cela se produit assez souvent dans les organisations utilisant Yandex.Disk. Imaginez que dans l'exemple précédent, au moment où nous avons reçu la confirmation du backend pour le premier changement de nom, un autre utilisateur prend et renomme à nouveau ce dossier. Dans ce cas, encore une fois, vous ne pouvez pas effectuer immédiatement les actions que le premier utilisateur a déjà effectuées sur son ordinateur. Le dossier dans lequel il travaillait localement était déjà appelé différemment sur le backend à ce moment-là.
Il arrive parfois qu'un fichier sur l'ordinateur d'un utilisateur ne puisse pas être nommé de la même manière qu'il est appelé dans le cloud. Cela peut arriver s'il y a un caractère dans le nom qui ne peut pas être utilisé par le système de fichiers local, ou si l'utilisateur est invité à dossier partagé, et il a son propre dossier avec ce nom. Dans de tels cas, nous devons utiliser des alias locaux et suivre leur relation avec les objets dans le cloud.
Dans cette version de l'algorithme, nous avons utilisé trois arbres principaux : local (Local Index), cloud (Remote Index) et le dernier synchronisé (Stable Index). De plus, pour empêcher la régénération d'opérations de synchronisation déjà en file d'attente, deux autres arborescences auxiliaires ont été utilisées : l'attendu local et le cloud attendu (Index distant attendu et Index local attendu). Ces arbres auxiliaires stockaient l'état attendu du local système de fichiers et le cloud, après avoir terminé toutes les opérations de synchronisation qui sont déjà en file d'attente.
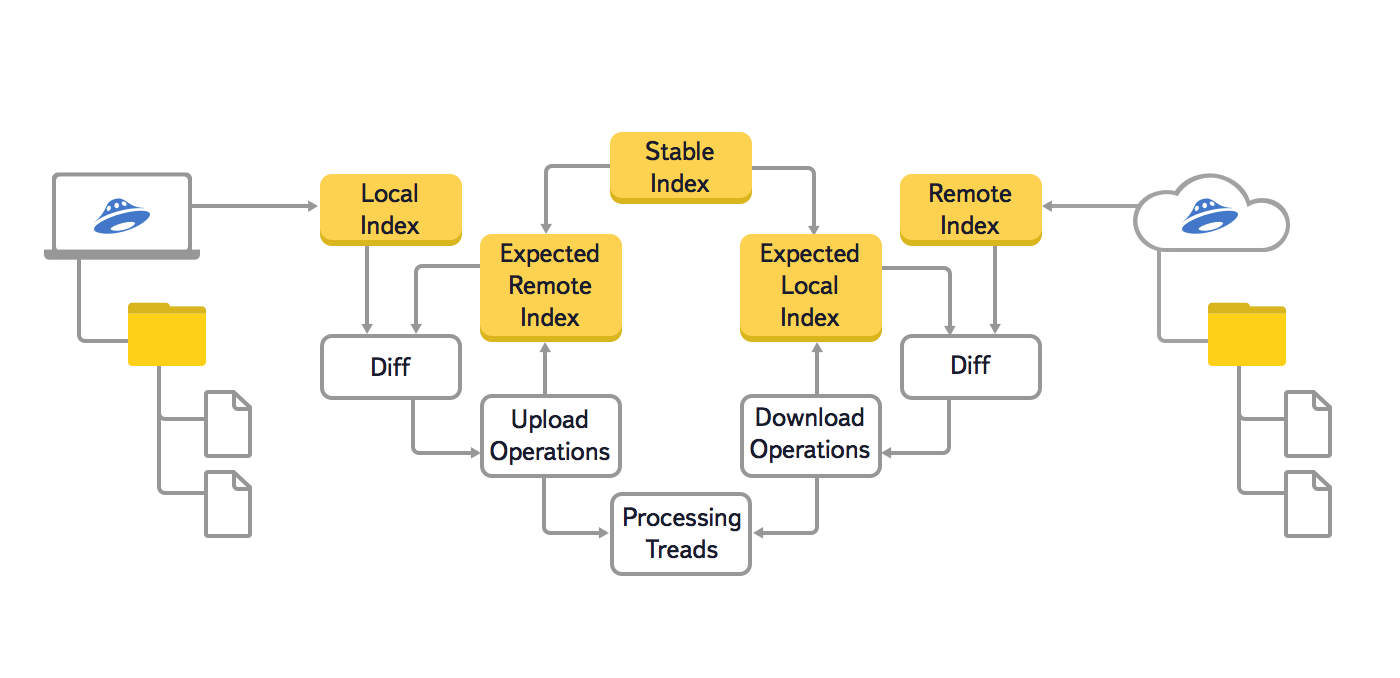
Nous voulions également augmenter quantité maximale fichiers avec lesquels l'utilisateur peut travailler sans problème. Plusieurs dizaines voire centaines de milliers de fichiers peuvent être, par exemple, un photographe qui stocke les résultats de séances photo dans Yandex.Disk. Cette tâche est devenue particulièrement urgente lorsque les utilisateurs ont eu la possibilité d'acheter de l'espace supplémentaire sur Yandex.Disk.
Dans le développement, je voulais aussi changer quelque chose. Débogage ancienne version a causé des difficultés, car les données sur les états d'un élément étaient dans des arbres différents.
À cette époque, l'identification des objets est apparue sur le backend, avec l'aide de laquelle il était possible de résoudre plus efficacement le problème de la détection des mouvements - auparavant, nous utilisions des chemins.
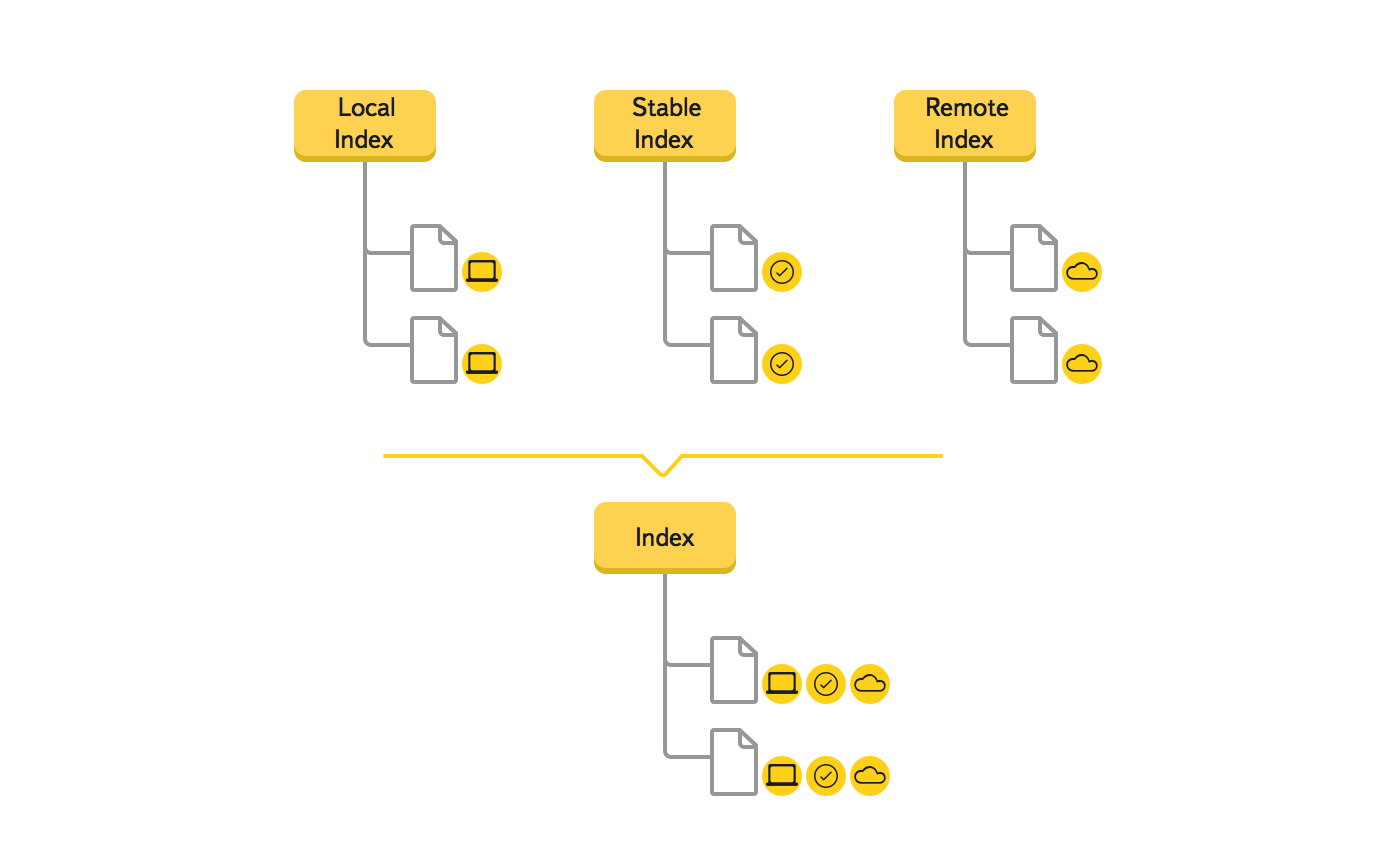
Ayant compris qu'il s'agissait d'un changement majeur, nous avons créé un prototype qui a confirmé l'efficacité de la nouvelle solution. Regardons un exemple de la façon dont les données de l'arborescence changent lors de la synchronisation d'un nouveau fichier.

Yandex.Disk utilise les condensés sha256 et MD5 pour vérifier l'intégrité des fichiers, détecter les fragments modifiés et dédupliquer les fichiers sur le backend. Étant donné que cette tâche charge lourdement le processeur, dans la nouvelle version, la mise en œuvre des calculs de résumé a été considérablement optimisée. La vitesse de réception d'un condensé de fichier a été augmentée d'environ deux fois.
À la suite des modifications apportées, le nombre de fichiers que le programme peut gérer sans aucun problème a considérablement augmenté. La version Windows contient 300 000 fichiers et la version Mac OS X 900 000 fichiers.
Ce n'est un secret pour personne pourquoi vous devez sauvegarder. Par exemple, il sera pratique pour un développeur Web de faire des sauvegardes si, pendant le processus de développement, il fait une erreur inaperçue par lui-même, et après quelques heures, l'erreur "apparaît" à la surface et il ne reste absolument plus de temps. pour trouver et corriger l'erreur. Bien entendu, Vscale dispose d'un système de sauvegarde, mais il ne prévoit que la copie des données de l'ensemble du serveur dans son ensemble. Et la possibilité de restaurer à partir d'une sauvegarde n'est disponible que sur le serveur à partir duquel la copie a été effectuée. Cette capacité ne satisfait pas tout à fait les besoins d'un développeur Web conditionnel. Cependant, le monde a maintenant une tendance "cloud" bien développée: hébergement cloud, cloud VPS, stockage en ligne données et ainsi de suite. Dans ce guide, nous allons vous montrer comment configurer le stockage de sauvegarde dans le cloud. Yandex.Disk nous aidera avec cela.
Commençons par installer le composant clé - le client pour Ya.Disk. Puisqu'il n'y a pas de package avec le client Ya.Disk dans la liste standard des référentiels, vous devrez ajouter le référentiel manuellement, puis mettre à jour l'index du package et ensuite seulement installer le package avec le client. Il y a une liste sur le site Web de Ya.Disk les commandes requises en une ligne :
écho "deb http://repo.yandex.ru/yandex-disk/deb/ stable main"| sudo tee -a /etc/apt/sources.list .d/yandex.list>/dev/null && wget http : //repo.yandex.ru/yandex-disk/YANDEX-DISK-KEY.GPG -O- | sudo apt-key add - && sudo apt-get update && sudo apt-get install -y yandex-diskLe client Yandex a été installé avec succès et vous pouvez commencer à le configurer. Yandex s'est assuré que le client travaillait au minimum avec les fichiers de configuration et a ajouté la possibilité de tout configurer avec une seule commande :
Configuration du disque Yandex
L'ordre de travail de la commande ci-dessus :
Assurez-vous de démarrer automatiquement Ya.Disk et vous pouvez personnaliser le reste des éléments à votre discrétion. À ce stade, le réglage peut être considéré comme terminé.
Pour créer sauvegarde, il existe de nombreuses commandes à utiliser. Python ou perl peuvent vous aider, mais il est plus pratique de le faire en utilisant bash. Il est simple et facile à utiliser et interagit directement avec la console. Créez un script bash :
Nano /var/backup.sh
Collez-y le code suivant :
CHEMIN_SERVEUR = "/var/www/html"
cur_date = `date +% Y-% m-% d`
nom de fichier = "sauvegarde -" $ cur_date ".tar.bz2"
tar -cjf $ nom de fichier $ CHEMIN_SERVEUR
if [-f $ nom de fichier] ; ensuite
mv $ nom de fichier /root/Yandex.Disk/backup/
synchronisation de disque Yandex
Fi
Enregistrez le fichier avec le raccourci clavier Ctrl + O, confirmez l'action avec la touche Entrer et fermez le fichier avec le raccourci clavier Ctrl + X... Assurez-vous d'attribuer des autorisations au fichier afin qu'il ait accès aux commandes système (créer et déplacer des dossiers, accéder aux répertoires) :
Cd/var
chmod -R 755 * backup.sh
En bref sur ce que fait le script :
Vous pouvez vérifier si le script fonctionne avec la commande suivante :
Cd / var && ./backup.sh
À la suite de l'exécution de la commande, l'archive sera chargée dans stockage en ligne.
L'étape suivante et finale consiste à ajouter le script au planificateur de tâches. Nous aidera avec ce crontab. Ouvrez la liste des tâches planifiées :
Crontab -e
À la toute fin, ajoutez la ligne :
0 0 * * * /var/backup.sh
Désormais, Crontab exécutera le script tous les jours à minuit. Ceci termine la configuration de la sauvegarde automatique.
Vous avez configuré avec succès création automatique une sauvegarde pour le répertoire de votre site Web. C'est un algorithme très utile pour éviter de perdre une sauvegarde si elle était stockée sur le serveur lui-même. Par le même principe, vous pouvez faire des copies de sauvegarde des fichiers de configuration. Généralement technologies cloud bon car ils offrent une haute disponibilité et une sécurité de stockage des données personnelles. Choisir le cloud est un bon choix.
Vous devrez peut-être télécharger des sauvegardes de projets (sites) sur Yandex.Disk pour plusieurs raisons, par exemple, en raison d'un manque d'espace sur le serveur (hébergement, VDS, VPS) ou pour augmenter la sécurité du stockage des sauvegardes (au cas où le serveur est sans raid et il quitte le bâtiment).
À cet égard, j'ai écrit pour moi-même et j'ai décidé de publier pour les autres un petit script bash pour la sauvegarde sur Yandex.Disk. Fonctions de script :
- Création de projets de sauvegarde sur le serveur (fichiers + bases de données MySQL) ;
- Autorisation sur Yandex.Disk en tant qu'application (à l'aide d'un jeton, un moyen plus sûr que d'utiliser un nom d'utilisateur et un mot de passe);
- Envoi de sauvegardes du serveur à Yandex.Disk ;
- Suppression des anciennes sauvegardes de Yandex.Disk pour économiser de l'espace (nombre maximal configurable de sauvegardes stockées);
- Enregistrement et envoi d'un journal par e-mail (paramétrable).
Pour utiliser le script, vous devez d'abord obtenir un jeton de Yandex.Disk. Commençons.
1. Connectez-vous à Yandex sous le compte sur lequel nous effectuerons la sauvegarde, accédez à oauth.yandex.ru et cliquez sur « Enregistrer une nouvelle application ».
2. Renseignez le nom de l'application (par exemple, "sauvegarde") et émettez les droits nécessaires dans la section "Yandex.Disk REST API", à savoir : "Accès aux informations sur le Disque" et "Accès au dossier de l'application sur le Disque".
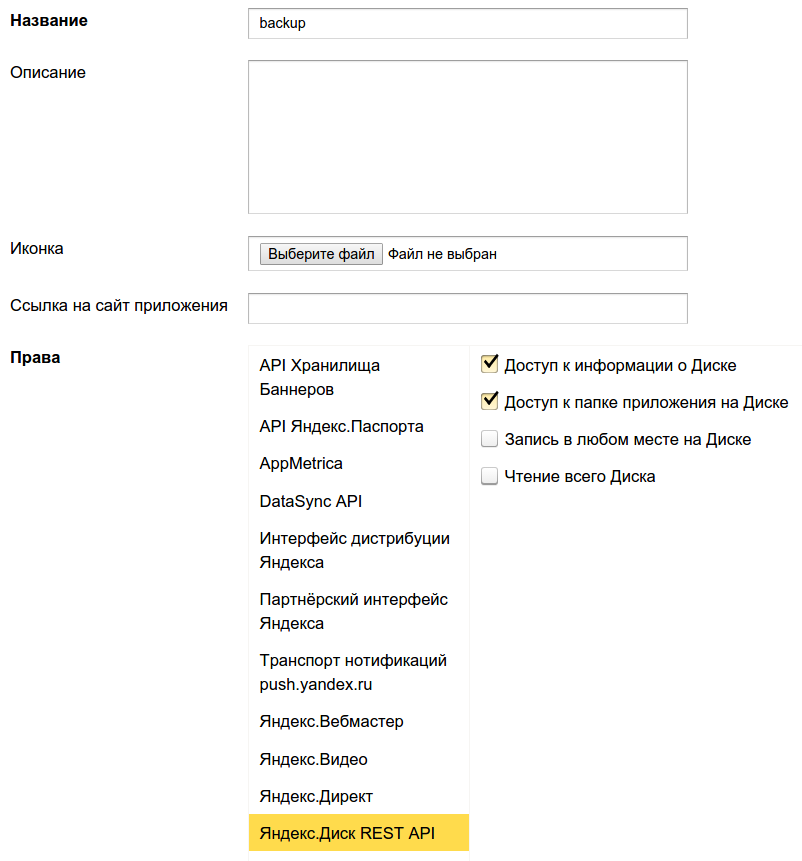
Ci-dessous, sur la même page, sous le champ "URL de rappel", cliquez sur "Soumettre l'URL pour le développement" et cliquez sur "Enregistrer":

3. Après avoir enregistré les paramètres de l'application, nous serons redirigés vers la page contenant les données de l'application :
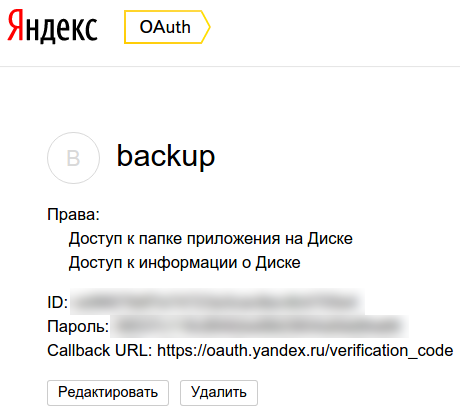
4. Maintenant, nous obtenons le jeton lui-même (si vous le souhaitez, vous pouvez en savoir plus à ce sujet dans le manuel Yandex), pour cela, nous copions l'ID, le substituons à la fin de l'URL https://oauth.yandex.ru/ autorise?response_type=token&client_id=, accédez à l'adresse résultante et confirmez la délivrance des autorisations à l'application :
![]()
En conséquence, un jeton sera affiché sur la page, qui est émis pour au moins 1 an, donc si le script de sauvegarde cesse soudainement de fonctionner, nous pouvons obtenir un nouveau jeton et le remplacer dans le script. Vous pouvez tester les capacités de travail avec Yandex.Disk en utilisant le jeton reçu sur un terrain d'essai spécial.
Et maintenant, le script bash lui-même pour une sauvegarde sur Yandex.Disk :
#! / bin / bash # # Script de sauvegarde Yandex.Disk v1.0 par Sergey Lukonin (neblog.info) # # # # # # # # # # # PARAMÈTRES DE SAUVEGARDE MYSQL # # # # # # # # # # # # Serveur DB MYSQL_SERVER = mysql.some-server.ru # L'utilisateur sous lequel nous allons sauvegarder les bases de données disponibles, la racine mysql est généralement accessible à toutes les bases de données, l'utilisateur individuel a généralement accès à la base de données d'un projet spécifique MYSQL_USER = some-user # Mot de passe de l'utilisateur de la base de données (Mot de passe de la racine du serveur et ne pas confondre les différents de la racine de mysql) MYSQL_PASSWORD = un mot de passe # # # # # # # # # # REGLAGES GENERALES # # # # # # # # # # # # pour le stockage temporaire des sauvegardes, qui sont supprimées après l'envoi à Yandex .. Sauvegarde de disque (0 - conserver toutes les sauvegardes): MAX_BACKUPS = "14" # Date utilisée dans les noms d'archive DATE = `date" +% Y-% m-% d "` # Répertoires d'archivage (séparés par un espace), qui seront placés dans une seule archive et envoyés à Yandex.Disk DIRS = "/ home / www / projects / neblog" # Jeton Yandex.Disk (voir neblog.info pour comment l'obtenir) TOKEN = "" # Le nom du fichier journal, stocké dans deer le répertoire spécifié dans $ BACKUP_DIR LOGFILE = "backup.log" # E-mail pour envoyer le résultat de l'exécution du script. Laissez vide si vous ne souhaitez pas soumettre de résultats. sendLog = " [email protégé] "# Envoyer uniquement les erreurs (true). Spécifiez false si vous souhaitez envoyer des journaux pour tout résultat de l'exécution du script. SendLogErrorsOnly =" false "# # # # # # # # # # FIN DES PARAMÈTRES # # # # # # # # # # # # # # # # # # # # # # NE CHANGER RIEN RIEN ! # # # # # # # # # # # Fonction mailing () (if [! $ SendLog = ""]; then if ["$ sendLogErrorsOnly " == true ]; then if echo "$ 1" | grep -q "error" then echo "$ 2" | mail -s "$ 1" $ sendLog> / dev / null fi else echo "$ 2" | mail -s "$ 1" $ sendLog> / dev / null fi fi) fonction logger () (echo "[" `date" +% Y-% m-% d% H:% M:% S "` "] Fichier $ BACKUP_DIR: $ 1" >> $ BACKUP_DIR / $ LOGFILE) fonction parseJson () (local output regex = "(\" $ 1 \ ": [\"]?) ([^ \ ", \)] +) ( [\"]?) "[[$ 2 = ~ $ regex]] && output = $ (BASH_REMATCH) echo $ output) fonction checkError () (echo $ (parseJson "error" "$ 1")) fonction getUploadUrl () (json_out = `curl -s -H" Autorisation: OAuth $ TOKEN "https: //cloud-api.yandex.net: 443 / v1 / disk / resources / upload /? Path = app: / $ backupName & overwrite = true ` json _error = $ (checkError "$ json_out") if [[$ json_error! = ""]]; puis logger "$ PROJECT - Yandex.Disk error: $ json_error" mailing "$ PROJECT - Yandex.Disk backup error" "ERROR copy file $ FILENAME. Yandex.Disk error: $ json_error" echo "" else output = $ (parseJson " href "$ json_out) echo $ output fi) fonction uploadFile (local json_out local uploadUrl local json_error uploadUrl = $ (getUploadUrl) if [[$ uploadUrl! =" "]]; then echo $ UploadUrl json_out =` curl -s -T $ 1 -H "Authorization: OAuth $ TOKEN" $ uploadUrl` json_error = $ (checkError "$ json_out") if [[$ json_error! = ""]]; Then logger "$ PROJECT - Yandex.Disk error: $ json_error" mailing " $ PROJECT - Yandex.Disk backup error "" ERREUR copier le fichier $ FILENAME. Yandex.Disk error: $ json_error "else logger" $ PROJECT - Copier le fichier sur Yandex.Disk avec succès "mailing" $ PROJECT - Yandex.Disk backup success " " SUCCESS copy file $ FILENAME "fi else echo" Des erreurs se sont produites. Vérifiez le fichier journal pour plus de détails "fi) function backups_list () (# Recherchez tous les fichiers de sauvegarde dans le répertoire de l'application et affichez leurs noms : curl -s -H "Autorisation : OAuth $ TOKEN" "https://cloud-api.yandex.net:443/v1/disk/resources?path=app:/&sort=created&limit=100" | tr "()," "\ n" | grep "nom [[: graphe:]] *. tar.gz" | couper -d: -f 2 | tr -d "" ") function backups_count () (local bkps = $ (backups_list | wc -l) # Si nous sauvegardons à la fois les fichiers et la base de données, alors nous avons 2 fichiers pour 1 sauvegarde. Par conséquent, le nombre de sauvegardes = le nombre de fichiers / 2: expr $ bkps / 2) fonction remove_old_backups () (bkps = $ (backups_count) old_bkps = $ ((bkps - MAX_BACKUPS)) if ["$ old_bkps" -gt "0"]; then logger " Supprimer les anciennes sauvegardes de Yandex ... Disque "# Cycle de suppression des anciennes sauvegardes : # Suppression du premier fichier de la liste 2 * old_bkps fois pour i in` eval echo (1 .. $ ((old_bkps * 2))) `; do curl -X DELETE -s - H" Autorisation : OAuth $ TOKEN "" https://cloud-api.yandex.net:443/v1/disk/resources?path=app:/$(backups_list | awk "(NR == 1)") & en permanence = true " done fi) logger " --- $ PROJECT START BACKUP $ DATE --- " logger " Dumping database dumps " mkdir $ BACKUP_DIR / $ DATE for i in `mysql -h $ MYSQL_SERVER -u $ MYSQL_USER -p $ MYSQL_PASSWORD -e" show databases; "| grep -v information_schema | grep -v Database`; do mysqldump -h $ MYSQL_SERVER -u $ MYSQL_USER -p $ MYSQL_PASSWORD $ i> $ BACKUP_DIR / $ DATE / $ i.sql; done logger" Créez une archive mysql $ BACKUP_DIR / $ DATE-mysql- $ PROJECT.tar.gz "tar -czf $ BACKUP_DIR / $ DATE-mysql- $ PROJECT.tar.gz $ BACKUP_DIR / $ DATE rm -rf $ BACKUP_DIR / $ DATE logger " Créer une archive de répertoire $ BACKUP_DIR / $ DATE-files- $ PROJECT.tar.gz " tar -czf $ BACKUP_DIR / $ DATE-files- $ PROJECT.tar.gz $ DIRS FILENAME = $ DATE-mysql- $ PROJECT.tar enregistreur .gz" cliquez sur Yandex.Disk archive mysql $ BACKUP_DIR / $ DATE-mysql- $ PROJECT.tar.gz "backupName = $ DATE-mysql- $ PROJECT.tar.gz uploadFile $ BACKUP_DIR / $ DATE-mysql- $ PROJECT.tar.gz FILENAME = $ DATE-files- $ PROJECT.tar.gz logger "Télécharger sur Yandex.Disk l'archive avec $ BACKUP_DIR / $ DATE-files- $ PROJECT.tar.gz" backupName = $ DATE-files- $ PROJECT.tar. gz uploadFile $ BACKUP_DIR / $ DATE-files- $ PROJECT.tar.gz logger "Supprimer les archives du disque" find $ BACKUP_DIR -type f -name "* .gz" -exec rm "()" \; # Supprimez les anciennes sauvegardes de Yandex.Disk (si MAX_BACKUPS> 0) si [$ MAX_BACKUPS -gt 0] ; then remove_old_backups ; fi logger "Fin du script de sauvegarde"
Vous pouvez également en télécharger un prêt à l'emploi. Le script doit être situé sur le serveur, remplacez les paramètres qu'il contient par les vôtres, donnez le droit de s'exécuter (chmod + x) et configurez-le pour qu'il soit exécuté quotidiennement dans cron. Si vous prévoyez d'effectuer plusieurs de ces tâches, définissez le délai entre leur démarrage (5 à 10 minutes).
DANS monde moderne l'information prend de plus en plus de valeur, dont la perte peut entraîner des coûts financiers importants. Le site est une information précieuse, dont nous allons faire une sauvegarde, ou simplement une sauvegarde, dans cet article en utilisant wordpress comme exemple et la placer sur un disque Yandex. J'envisagerai la possibilité d'automatiser le processus, que j'ai imaginé pour mes besoins et que je l'utilise depuis longtemps et avec succès.
Nous avancerons par étapes. Tout d'abord, considérons simplement la possibilité de sauvegarder directement les fichiers du site et de la base de données. Et puis nous répondrons pleinement à la question de savoir comment faire une sauvegarde régulière de votre site sur wordpress.
Ici, je n'ai pas réinventé la roue, mais j'ai profité de d'une manière standard archivage de fichiers - archiveur le goudron... J'écrirai tous les commentaires et explications tout de suite dans le script :
#! / bin / sh # Définir les variables # Date actuelle au format 2015-09-29_04-10 date_time = `date +"% Y-% m-% d_% H-% M "` # Où nous plaçons la sauvegarde bk_dir = "/ mnt / backup / site1.ru "# Répertoire un niveau supérieur à celui où se trouvent les fichiers inf_dir =" / web / sites / site1.ru / "# Le nom du répertoire direct avec les fichiers dir_to_bk = " www " # Créer une archive / usr / bin / tar -czvf $ bk_dir / www_ $ date_time.tar.gz -C $ inf_dir $ dir_to_bk
A la sortie, après l'exécution du script, nous avons un dossier nommé www_2015-09-29_04-10.tar.gz, à l'intérieur duquel il y aura un dossier www avec tout le contenu. Initialement, ce dossier se trouvait à /web/sites/site1.ru/www. Ici, j'ai appliqué tar avec le paramètre -AVEC afin que l'archive n'ait pas le chemin exact /web/sites/site1.ru, mais uniquement le dossier www. C'est juste plus pratique pour moi.
Vous pouvez utiliser ce script séparément pour créer des archives de fichiers, pas nécessairement le site. Nous l'avons mis cron et nous obtenons un archivage régulier.
Créons maintenant un script pour une sauvegarde de la base de données. Rien de spécial ici non plus, j'utilise un outil standard mysqldamp:
#! / bin / sh # Définir les variables # Date actuelle au format 2015-09-29_04-10 date_time = `date +"% Y-% m-% d_% H-% M "` # Où nous plaçons la sauvegarde bk_dir = "/ mnt / backup / site1.ru "# Database user user =" user1 " # User password password =" pass1 " # Database name for backup bd_name =" bd1 " # Décharger la base de données / usr / bin / mysqldump -- opt -v - -databases $ nom_bd -u $ utilisateur -p $ mot de passe | / usr / bin / gzip -c> $ bk_dir / mysql_ $ date_time.sql.gz
En sortie, nous avons un fichier avec un dump de la base de données mysql_2015-09-29_04-10.sql.gz. La décharge est stockée dans format de texte, peut être ouvert et modifié par n'importe quel éditeur.
Il y a un assez pratique et service gratuit Je suis un index, un disque que tout le monde peut utiliser. Peu d'espace est donné gratuitement, mais il y en a assez pour sauvegarder un site sur wordpress. Au fait, j'ai 368 Go disponibles gratuitement avec l'aide de toutes sortes de promotions :
Je suis ndex.Disk peut être connecté à l'aide de webdav. Mon serveur est CentOS 7, je vais vous dire comment le monter dedans. Tout d'abord, nous nous connectons. Ensuite, installez le paquet davfs2:
# miam -y installer davfs2
Essayons maintenant de monter le disque :
# mkdir / mnt / yadisk # mount -t davfs https://webdav.yandex.ru / mnt / yadisk / Veuillez saisir le nom d'utilisateur pour vous authentifier auprès du serveur https://webdav.yandex.ru ou appuyez sur Entrée pour aucun. Nom d'utilisateur : veuillez saisir le mot de passe pour authentifier l'utilisateur [email protégé] avec le serveur https://webdav.yandex.ru ou appuyez sur Entrée pour aucun. Mot de passe : /sbin/mount.davfs : Avertissement : "ne peut pas écrire l'entrée dans mtab, mais montera quand même le système de fichiers
J'ai ndex.Le disque est monté dans le dossier /mnt/yadisk.
Pour automatiser le processus d'archivage et ne pas saisir le nom d'utilisateur et le mot de passe à chaque fois, modifiez le fichier /etc/davfs2/secrets en ajoutant une nouvelle ligne avec le nom d'utilisateur et le mot de passe à la fin :
# mcedit / etc / davfs2 / secrets / mnt / yadisk / [email protégé] le mot de passe
Désormais, aucune question ne sera posée lors du montage du disque. Vous pouvez ajouter une connexion disque Yandex à fstab pour qu'il se monte automatiquement au démarrage, mais je trouve cela redondant. Je connecte et déconnecte le lecteur dans le script de sauvegarde. Si vous souhaitez le monter automatiquement, ajoutez à fstab :
Https://webdav.yandex.ru / mnt / yadisk davfs rw, utilisateur, _netdev 0 0
Nous avons démonté tous les éléments de création d'une copie de sauvegarde du site, il est maintenant temps de rassembler tout cela en un seul endroit. J'utilise le schéma de sauvegarde de site suivant :
Avec un tel schéma, nous avons toujours à portée de main les 7 dernières archives, les archives hebdomadaires du mois en cours et les archives de chaque mois, au cas où. À quelques reprises, ce schéma m'a aidé lorsque j'avais besoin d'obtenir quelque chose à partir d'une sauvegarde il y a une semaine, par exemple.
Voici 3 scripts complets pour créer une copie de sauvegarde d'un site wordpress, c'est le moteur que j'utilise le plus souvent, mais en réalité vous pouvez sauvegarder n'importe quel site - joomla, drupal, modx, etc. Un cms ou un framework n'est pas d'une importance fondamentale .
Script de sauvegarde quotidienne du site Web jour-sauvegarde.sh:
journée"# Répertoire de l'archive inf_dir =" / web / sites / site1.ru / "# Le nom du répertoire direct avec les fichiers dir_to_bk =" www "# Database user user =" user1 " # User password password =" pass1 " # Nom de la base de données pour la sauvegarde bd_name = "bd1" # Mount Yandex.disk mount -t davfs https://webdav.yandex.ru / mnt / yadisk / # Créer une archive source / usr / bin / tar -czvf $ bk_dir / www_ $ date_heure.tar. gz -C $ inf_dir $ dir_to_bk # Dump la base de données / usr / bin / mysqldump --opt -v --databases $ bd_name -u $ user -p $ mot de passe | / usr / bin / gzip -c> $ bk_dir / mysql_ $ date_time.sql.gz # Supprimer les archives de plus de 7 jours / usr / bin / find $ bk_dir -type f - mtemps +7
Script de sauvegarde hebdomadaire du site sauvegarde-semaine.sh:
#! / bin / sh # Définir les variables # Date actuelle au format 2015-09-29_04-10 date_time = `date +"% Y-% m-% d_% H-% M "` # Où nous plaçons la sauvegarde bk_dir = "/ mnt / yadisk / site1.ru / semaine"# Répertoire de l'archive inf_dir =" / web / sites / site1.ru / "# Le nom du répertoire direct avec les fichiers dir_to_bk =" www "# Database user user =" user1 " # User password password =" pass1 " # Nom de la base de données pour la sauvegarde bd_name = "bd1" # Mount Yandex.disk mount -t davfs https://webdav.yandex.ru / mnt / yadisk / # Créer une archive source / usr / bin / tar -czvf $ bk_dir / www_ $ date_heure.tar. gz -C $ inf_dir $ dir_to_bk # Dump la base de données / usr / bin / mysqldump --opt -v --databases $ bd_name -u $ user -p $ mot de passe | / usr / bin / gzip -c> $ bk_dir / mysql_ $ date_time.sql.gz # Supprimer les archives de plus de 30 jours / usr / bin / find $ bk_dir -type f -mtime +30-exec rm() \; # Désactiver Yandex.Disk umount / mnt / yadisk
Script de sauvegarde de site Web mensuel backup-mois.sh:
#! / bin / sh # Définir les variables # Date actuelle au format 2015-09-29_04-10 date_time = `date +"% Y-% m-% d_% H-% M "` # Où nous plaçons la sauvegarde bk_dir = "/ mnt / yadisk / site1.ru / mois"# Répertoire de l'archive inf_dir =" / web / sites / site1.ru / "# Le nom du répertoire direct avec les fichiers dir_to_bk =" www "# Database user user =" user1 " # User password password =" pass1 " # Nom de la base de données pour la sauvegarde bd_name = "bd1" # Mount Yandex.disk mount -t davfs https://webdav.yandex.ru / mnt / yadisk / # Créer une archive source / usr / bin / tar -czvf $ bk_dir / www_ $ date_heure.tar. gz -C $ inf_dir $ dir_to_bk # Dump la base de données / usr / bin / mysqldump --opt -v --databases $ bd_name -u $ user -p $ mot de passe | / usr / bin / gzip -c> $ bk_dir / mysql_ $ date_time.sql.gz # Désactiver Yandex.disk umount / mnt / yadisk
N'oubliez pas de créer un répertoire /mnt/yadisk/site1.ru sur un disque Yandex, et il y a 3 autres dossiers : jour, semaine, mois :# cd /mnt/yadisk/site1.ru && mkdir jour semaine mois
Maintenant, pour l'automatisation, ajoutez ces 3 fichiers à cron:
# mcedit / etc / crontab # sauvegarde du site sur yandex.disk # quotidiennement à 4h10 10 4 * * * root /root/bin/backup-day.sh> / dev/null 2> & 1 # hebdomadaire à 4 : 20h dimanche 20 4 * * 0 root /root/bin/backup-week.sh> / dev / null 2> & 1 # mensuel à 4h30 le 1er du mois 30 4 1 * * root / root / bin / backup-month .sh> / dev / null 2> & 1
Ça y est, notre wordpress est sauvegardé de manière fiable. En théorie, ici, vous devez joindre une alerte au courrier, mais mes mains ne peuvent pas le faire. Et depuis plusieurs mois d'utilisation, je n'ai pas eu une seule panne.
Considérons maintenant l'option lorsque vous devez restaurer un site à partir d'une sauvegarde. Pour cela, nous avons besoin des deux archives : des sources et une base de données. En principe, vous pouvez le décompresser n'importe où. Sous Windows, les archives sont ouvertes avec l'archiveur gratuit 7zip. Dump de base de données au format texte brut, peut être ouvert avec le bloc-notes, copié et collé dans phpmyadmin.

Il peut donc y avoir de nombreuses options de récupération, c'est ce que j'aime cette approche. Tous les fichiers sont sous forme ouverte, vous pouvez travailler avec eux par tous les moyens à portée de main.
Voici un exemple de la façon d'extraire des fichiers d'une archive dans la console du serveur. Décompressez le répertoire www de la sauvegarde :
# tar -xzvf www_2015-10-01_04-10.tar.gz
Les fichiers sont extraits dans le dossier www. Maintenant, ils peuvent être copiés dans le dossier du site.
Pour restaurer la base de données, nous procédons comme suit. Tout d'abord, décompressez l'archive :
# gunzip mysql_2015-10-01_04-10.sql.gz
Maintenant, remplissons le dump dans la base de données :
# mysql --host = localhost --user = user1 --password = pass1 bd1; MariaDB [(aucun)]> source mysql_2015-10-01_04-10.sql;
Ça y est, la base de données a été restaurée.
Veuillez noter que la base de données sera restaurée dans la base de données avec le nom d'origine et remplacera son contenu, s'il y en a un sur le serveur. Pour restaurer une base de données vers une autre, vous devez modifier le début du vidage et remplacer le nom de la base de données par un nouveau. Si la récupération a lieu sur un serveur différent, cela n'a pas d'importance.
Nous avons donc examiné les options de création de sauvegardes de sites et de bases de données en utilisant le moteur wordpress comme exemple. Dans ce cas, seulement moyens standards serveur. A titre d'exemple, nous avons utilisé un récepteur pour stocker des copies de Index.Disk, mais rien ne nous empêche de l'adapter à un autre. Il peut s'agir d'un disque dur ou disque externe, un autre stockage cloud qui peut être monté sur un serveur.
Le schéma de création d'une sauvegarde vous permet de revenir en arrière presque indéfiniment. Vous pouvez définir vous-même la profondeur des archives en modifiant le paramètre mtime dans le scénario. Vous pouvez stocker, par exemple, une archive quotidienne non pas 7 jours, comme je le fais, mais 30, si vous en avez besoin. Alors essayez, adaptez-vous. Si vous avez des commentaires sur le travail, des erreurs ou des suggestions pour améliorer la fonctionnalité, partagez vos réflexions dans les commentaires, je serai ravi de les entendre.
Salutations, chers lecteurs de mon blog. Vous avez probablement entendu parler d'un programme qui vous permet de stocker des fichiers sur le serveur Yandex. Sinon, bienvenue sur soft.yandex.ru - c'est là.
Alors c'est tout. Il y a quelques jours, alors que je parcourais les sites, je me suis promené dans un blog où un script a été publié qui vous permet d'enregistrer une copie de sauvegarde du site sur le disque Yandex. Dans cet article, je vais en parler en détail.
Vous devez d'abord modifier l'adresse du serveur mysql. Dans la plupart des cas, c'est localhost, donc je l'ai laissé là, s'il est différent, nous le remplaçons par le nôtre dans la ligne
$ dbhost = "localhost" ; // Adresse du serveur MySQL.
Dans la ligne ci-dessous, remplacez "database_user" par votre valeur pour le nom d'utilisateur de la base de données mysql.
"nom_base de données" est le nom de la base de données mysql.
Au lieu de "site_dear_hear", nous insérons notre chemin vers le site à partir de la racine du disque.
Après cela, nous procédons à la configuration du disque Yandex :
Tout. Nous sauvegardons le fichier et le téléchargeons sur le serveur.
Je ne recommande pas de le télécharger dans le répertoire racine du site, car toutes sortes de robots le contacteront constamment, ce qui entraînera le remplissage du disque Yandex avec des copies inutiles de sauvegardes. Il est préférable de créer un dossier, par exemple "a3hd7siq8a7s9xeeewwwerw-0-032-_2" afin que personne d'autre que vous et cran ne sache où vous l'avez.
Cran est un planificateur de tâches : programme spécial, avec lequel vous pouvez définir le lancement de scripts sur un calendrier, mais je ne sais pas comment l'utiliser, donc je ne peux pas aider ici.
Vous savez probablement déjà que j'ai cinq sites. Naturellement, on en a marre de les exécuter séparément, mais c'est bien qu'un deuxième script ait été posté dans le même article, ce qui lance à tour de rôle tous les autres scripts.
Si vous avez moins de cinq sites, supprimez simplement les lignes qui ressemblent à :
Écho ""; $ réponse = file_get_contents ("http://site5.ru/beckup.php"); echo iconv ("Windows-1251", "utf-8", réponse $);
Si vous avez un site dans la zone .рф, vous devrez traduire en Panycode avant d'enregistrer l'adresse.
J'espère que cet article vous a été utile.
J'attends tes commentaires avec impatience.
| Articles Liés: | |
|
Comment faire une couverture pour un cahier La couverture pour un cahier est belle
Le temps scolaire bat son plein et l'enfant n'est pas d'humeur à apprendre ? Augmenter ... Comment utiliser une signature électronique à partir d'un lecteur flash
En règle générale, la signature numérique est enregistrée sur une clé USB .... Telegraph - un service de formatage et de publication de textes dans le Telegram Ling intitle toutes les publications des utilisateurs
Obtenir des données privées ne signifie pas toujours pirater - parfois, cela ... | |




