Вибір читачів




Популярні статті
ER-діаграми
Загальним способом представлення логічної моделі БД є побудова ER-діаграм (Entity-Relationship – сутність-зв'язок). У цій моделі сутність окреслюється дискретний об'єкт, котрій зберігаються елементи даних, а зв'язок описує відношення між двома об'єктами.
У прикладі менеджера турфірми є 5 основних об'єктів:
Туристи
Путівки
Відносини між цими об'єктами можуть бути визначені простими термінами:
Кожен турист може купити одну або кілька путівок.
Кожній путівці відповідає її оплата (оплат може бути кілька, якщо путівка, наприклад, продана в кредит).
Кожен тур може мати кілька сезонів.
Путівка продається на один сезон одного туру.
Ці об'єкти та відносини можуть бути представлені ER-діаграмою, як показано на рис 2.
Мал. 2. ER-діаграма для програми БД менеджера турфірми
Об'єкти, атрибути та ключі
Далі модель розвивається шляхом визначення атрибутів кожного об'єкта. Атрибути об'єкта - це елементи даних, які стосуються певного об'єкта, які мають зберігатися. Аналізуємо складений словник даних, виділяємо у ньому об'єкти та його атрибути, розширюємо словник за необхідності. Атрибути для кожного об'єкта в цьому прикладі представлені в таблиці 2.
Таблиця 2. Об'єкти та атрибути БД
|
Об'єкт |
Туристи |
Путівки |
Тури |
Сезони |
Оплати |
|
Назва |
дата початку |
дата оплати |
|||
|
Дата кінця |
|||||
|
По-батькові |
Інформація |
||||
|
Атрибути |
|||||
Слід звернути увагу на те, що кілька елементів відсутні. Опущено реєстраційну інформацію, згадану у функціональній специфікації. Як її врахувати, ви подумаєте самостійно та доопрацюєте запропонований приклад. Але важливіше те, що поки що відсутні атрибути, необхідні зв'язку об'єктів друг з одним. Ці елементи даних у ER-моделі не надаються, оскільки є, власне, «натуральними» атрибутами об'єктів. Вони обробляються по-іншому та будуть враховані у реляційній моделі даних.
Реляційна модель характеризується використанням ключів та відносин. Існує відмінність у контексті реляційної бази даних термінів relation (ставлення) та relationship (схема даних). Ставлення сприймається як невпорядкована, двомірна таблиця з незв'язаними рядками. Схема даних формується між відносинами (таблицями) через загальні атрибути, що є ключами.
Існує кілька типів ключів, і вони іноді відрізняються лише з погляду їхнього взаємозв'язку з іншими атрибутами та відносинами. Первинний ключ унікально ідентифікує рядок (таблиці), і кожне відношення може мати тільки один первинний ключ, навіть якщо більше ніж один атрибут є унікальним. У деяких випадках потрібно більше одного атрибуту для ідентифікації рядків. Сукупність цих атрибутів називається складовим ключем. В інших випадках первинний ключ має бути спеціально створений (згенерований). Наприклад, стосовно «Туристи» має сенс додати унікальний ідентифікатор туриста (код туриста) як первинного ключа цього відношення для організації зв'язків з іншими відносинами БД.
Інший тип ключа, званий зовнішнім ключем, існує лише термінах схеми даних між двома відносинами. Зовнішній ключ щодо - це атрибут, який є первинним ключем (або частиною первинного ключа) в іншому відношенні. Це - розподілений атрибут, який формує схему даних між двома відносинами БД.
Для проектованої БД розширимо атрибути об'єктів кодовими полями як первинні ключі і використовуємо ці коди у відносинах БД для посилання на об'єкти БД наступним чином (табл. 3).
Побудовану схему БД ще рано вважати закінченою, оскільки потрібна її нормалізація. Процес, відомий як нормалізація реляційної БД, використовується для угруповання атрибутів спеціальними способами, щоб мінімізувати надмірність та функціональну залежність.
Таблиця 3. Об'єкти та атрибути БД з розширеними кодовими полями
|
Об'єкт |
Туристи |
Путівки |
Тури |
Сезони |
Оплати |
|
Атрибути |
Код туриста |
Код путівки |
Код сезону |
Код оплати |
|
|
Код туриста |
Назва |
дата початку |
дата оплати |
||
|
Код сезону |
Дата кінця |
||||
|
По-батькові |
Інформація |
Код путівки |
|||
Нормалізація
Функціональні залежності виявляються, коли значення одного атрибуту може бути визначене значення іншого атрибута. Атрибут, який може бути визначений, називається функціонально залежним від атрибуту, що є детермінантом. Отже, за визначенням, усі неключові (без ключа) атрибути функціонально залежатимуть від первинного ключа у кожному відношенні (оскільки первинний ключ унікально визначає кожен рядок). Коли один атрибут відносини унікально не визначає інший атрибут, але обмежує його набором визначених значень, це називається багатозначною залежністю. Часткова залежність має місце, коли атрибут відношення функціонально залежить від одного атрибута складеного ключа. Транзитивні залежності спостерігаються, коли неключовий атрибут функціонально залежить від одного або кількох інших неключових атрибутів щодо.
Процес нормалізації полягає у покроковому побудові БД у нормальній формі (НФ).
1. Перша нормальна форма (1НФ) дуже проста. Всі таблиці БД повинні задовольняти єдиній вимогі - кожен осередок у таблицях повинен містити атомарне значення, іншими словами, збережене значення в рамках предметної областіДодатки БД не повинні мати внутрішньої структури, елементи якої можуть знадобитися додатку.
2. Друга нормальна форма (2НФ) створюється тоді, коли видалені всі часткові залежності від відносин БД. Якщо у відносинах немає жодних складових ключів, то цей рівень нормалізації легко досягається.
3. Третя нормальна форма (3НФ) БД потребує видалення всіх транзитивних залежностей.
4. Четверта нормальна форма (4НФ) створюється у разі видалення всіх багатозначних залежностей.
БД нашого прикладу знаходиться в 1НФ, тому що всі поля таблиць БД атомарні за своїм змістом. Наша БД також знаходиться і в 2НФ, так як ми штучно ввели в кожну таблицю унікальні коди для кожного об'єкта (Код Туриста, Код Путівки і т. д.), за рахунок чого і досягли 2НФ для кожної з таблиць БД і всієї бази даних загалом. Залишилося розібратися з третьою та четвертою нормальними формами.
Зверніть увагу, що вони існують лише щодо різних видів залежностей атрибутів БД. Є залежності – потрібно коштувати НФ БД, немає залежностей – БД і так знаходиться у НФ. Але останній варіант практично не зустрічається у реальних додатках.
Отже, які ж транзитивні та багатозначні залежності є у нашому прикладі БД менеджера турфірми?
Давайте проаналізуємо ставлення "Туристи". Розглянемо залежності між атрибутами «Код туриста», «Прізвище», «Ім'я», «По батькові» та «Паспорт» (рис. 3). Кожен турист, представлений щодо поєднання « Прізвище ім'я по батькові», має на час поїздки лише один паспорт, при цьому повні тезки повинні мати різні номери паспортів. Тому атрибути «Прізвище-Ім'я-По батькові» та «Паспорт» утворюють щодо туристи складовий ключ.

Мал. 3. Приклад транзитивної залежності
Як видно з малюнка, атрибут "Паспорт" транзитивно залежить від ключа "Код туриста". Тому, щоб виключити цю транзитивну залежність, розіб'ємо складовий ключ відношення і саме ставлення на 2 зв'язки «один-до-одного». По-перше, залишимо йому ім'я «Туристи», включаються атрибути «Код туриста» та «Прізвище», «Ім'я», «По батькові». Друге відношення, назвемо його «Інформація про туристів», утворюють атрибути «Код туриста» і всі атрибути відносини, що залишилися, «Туристи»: «Паспорт», «Телефон», «Місто», «Країна», «Індекс». Ці два нових відносини вже не мають транзитивної залежності та перебувають у 3НФ.
Багатозначних залежностей у нашій спрощеній БД відсутні. Наприклад припустимо, що кожного туриста повинні зберігатися кілька контактних телефонів (домашній, робочий, стільниковий тощо., що дуже характерно практично), а чи не один, як у прикладі. Отримуємо багатозначну залежність ключа – «Код туриста» та атрибутів «Тип телефону» та «Телефон», у цій ситуації ключ перестає бути ключем. Що робити? Проблема вирішується також шляхом розбиття схеми відношення на 2 нові схеми. Одна з них повинна надавати інформацію про телефони (ставлення «Телефони»), а друга про туристів (ставлення «Туристи»), які зв'язуються по полю «Код туриста». «Код туриста» щодо «Туристи» буде первинним ключем, а щодо «Телефони» – зовнішнім.
Логічна модель– графічне уявлення структури бази даних з урахуванням прийнятої моделі даних (ієрархічної, мережевої, реляційної тощо.), незалежне від кінцевої реалізації бази даних та апаратної платформи. Іншими словами, вона показує, ЩО зберігається в базі даних (об'єкти предметної області, їх атрибути та зв'язки між ними), але не відповідає на питання ЯК (рис. 1).
Опис предметної області:
Оптовийзаводськойсклад
На склад поставляються деталі, виконані з певних матеріалів (литі), від заданого кола постачальників (постійних чи випадкових) із різних міст.
Як постачальників можуть виступати юридичні особи та індивідуальні підприємці, причому ці групи описуються своїм набором атрибутів, що характеризують; юридичних осіб – номер і дата держ. реєстрації, найменування, юридична адреса, форма власності; підприємці – ІПН, ПІБ, страховий поліс, номер паспорта, дата народження.
При оформленні поставки враховуються дата, кількість та вартість, вид упаковки та спосіб доставки (автотранспорт, залізничний транспорт, самовивіз), причому одне постачання може містити кілька видів деталей.
Постачальники переходять у розряд постійних, якщо вони здійснили поставок у сумі понад 1 000 000 рублів на рік.
Здійснюється відпуск деталей до цеху заводу з урахуванням дати, кількості та номера цеху. Підтримується актуальна кількість товарів на складі.
Мал. 1. Логічна модель бази даних у нотації IDEF1X
Методологія IDEF1X– один із підходів до моделювання даних, заснований на концепції "сутність – зв'язок" ( Entity – Relationship), запропонованої Пітером Ченом у 1976 р.
|
Таблиця 2.1. Основні елементи нотації IDEF1X |
|
|
Сутність(Entity) |
Графічне зображення |
|
Незалежна сутність |
Найменування Унікальний ідентифікатор Атрибути
|
|
Залежна сутність |
Атрибути |
|
Зв'язок(Relationship) |
Графічне зображення |
|
Неідентифікуючий зв'язок | |
|
Ідентифікуючий зв'язок | |
|
Зв'язок «Багато багатьох» | |
|
Успадкування (узагальнення) Неповне |
Батьківськ. |
Незалежнасутність- Це сутність, унікальний ідентифікатор якої не успадковується з інших сутностей. Зображується у вигляді прямокутника із прямими краями.
Залежна сутність- це сутність, унікальний ідентифікатор якої включає щонайменше один зв'язок з іншою сутністю. Наприклад, рядок документа не може існувати без документа (залежить від нього). Зображується у вигляді прямокутника із закругленими краями.
Методологія IDEF1X орієнтована проектування реляційних моделей баз даних. В основі реляційної моделі лежить поняття нормалізованого відношення (таблиці). При цьому сутності предметної області відображаються в таблиці бази даних (рис. 2), що мають такі властивості:
Мал.  2. Таблиця реляційної бази даних
2. Таблиця реляційної бази даних
Ключ- Стовпець або група стовпців, значення яких однозначно ідентифікують кожен рядок.
В одній таблиці може бути кілька ключів: один первинний, з якого здійснюється зв'язування відносин, інші – альтернативні. Властивості ключа:
унікальність (не може бути рядків з однаковим ключем);
Ненадмірність (видалення будь-якого атрибута з ключа позбавляє його властивості унікальності).
Реляційна база даних− це безліч пов'язаних між собою відносин. Зв'язки задаються з допомогою вторинних ключів (Foreign key – FK), тобто. атрибутів, які у інших відносинах є первинними ключами (Primary key – PK).
Основні обмеження цілісності реляційної моделі:
атрибути з первинного ключа не можуть набувати невизначеного значення (цілісність об'єктів);
вторинні ключі не можуть набувати значення, яких немає серед значень первинних ключів пов'язаної таблиці: якщо відношення R2 має серед своїх атрибутів якийсь зовнішній ключ (FK), який відповідає первинному ключу (PK) відношення R1, то кожне значення FK має дорівнювати одному із значень PK.
|
Щоб створити Логічну модель бази даних у Visio2013, виберіть Категорії шаблонів «Програми та бази даних», а в ній шаблон «Схема моделі бази даних» (рис. 2.3) |
Мал. 2.3. Шаблон "Схема моделі бази даних" |
|
Перш ніж приступити до створення Логічної моделі, зайдіть на вкладку «База даних» та в «Показати параметри» виставте такі налаштування (рис. 2.4-2.6). |
Мал. 2.4.Параметри документа (вкладка «Загальні») |
|
Мал. 2.6.Параметри документа (вкладка «Ставлення») |
Мал. 2.5.Параметри документа (вкладка «Таблиця») |
|
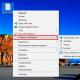
Щоб створити Сутність «Деталь», перетягніть стереотип Сутність із панелі інструментів на екран (мал. 2.7). |
Мал. 2.7.Створення Сутності |
|
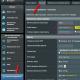
Задайте ім'яновій Сутності у властивостях у нижній частині екрану (рис. 2.8). |
Мал. 2.8.Властивості Сутності («Визначення») |
|
Потім на вкладці Стовпці створіть атрибути Сутності, позначте унікальний ідентифікатор (первинний ключ) галочкою у стовпці PK та натисніть кнопку «ОК» (рис. 2.9). |
Мал. 2.9.Властивості Сутності («Стовпці») |
|
Аналогічно створіть другу сутність, наприклад, «Матеріал». Щоб створити зв'язок між ними, перетягніть стереотип "Ставлення" точкою на зображення класу "Деталь", т.к. із кожного матеріалу виготовляється нуль, одна або кілька деталей. Потім другий кінець зв'язку перетягніть зображення класу «Матеріал» (рис. 2.10). Зовнішній ключ "Код матеріалу (FK)" автоматично з'явиться у складі атрибутів сутності "Деталь". Незафарбований ромб з боку матеріалу означає, що матеріал може бути не вказаний. |
Щоб усунути ромб, відкрийте властивості сутності «Деталь» і поставте цьому атрибуту галочку в стовпці «Обов'язкове». |
Мал. 2.10.Властивості відносини («Визначення») : Завдання
Для представлення математичного знання математичної логіки користуються логічними формалізмами - обчисленням висловлювань і обчисленням предикатів. Ці формалізми мають ясну формальну семантику і розроблені механізми виведення. Тому обчислення предикатів було першою логічною мовою, яку застосовували для формального опису предметних областей, пов'язаних із вирішенням прикладних завдань.
Логічні моделіуявлення знань реалізуються засобами логіки предикатів.
Предикатомназивається функція, що приймає два значення (істина або брехня) і призначена для вираження властивостей об'єктів або зв'язків між ними. Вираз, у якому затверджується чи заперечується наявність будь-яких властивостей у об'єкта, називається висловлюванням. Константислужать для об'єктів предметної області. Логічні речення чи висловлювання утворюють атомарні формули. Інтерпретація предикату- це безліч всіх допустимих зв'язувань змінних із константами. Зв'язування є підстановкою констант замість змінних. Предикат вважається загальнозначущим, якщо він правдивий у всіх можливих інтерпретаціях. Кажуть, що висловлювання логічно випливає із заданих посилок, якщо воно істинно завжди, коли істинні посилки.
Описи предметних областей, виконані в логічних мовах, називаються логічними моделями .
ДАТИ (МИХАЙЛО, ВОЛОДИМИРУ, КНИГУ);
($x) (ЕЛЕМЕНТ (x, ПОДІЯ-ДАТИ) • ДЖЕРЕЛО (x, МИХАЙЛО) • АДРЕСАТОВ (x, ВОЛОДИМИР) ОБ'ЄКТ(x, КНИГА).
Тут описано два способи запису одного факту: «Михайло дав книгу Володимиру».
Логічний висновок здійснюється за допомогою силогізму (якщо з A випливає B, а з B випливає C, то з A випливає C).
Загалом у основі логічних моделей лежить поняття формальної теорії, що задається четвіркою:
S =
де B - лічильна множина базових символів (алфавіт)теорії S;
F - підмножина виразів теорії S, звані формулами теорії(Під виразами розуміються кінцеві послідовності базових символів теорії S);
A - виділена множина формул, звані аксіомами теорії S, тобто безліч апріорних формул;
R - кінцева множина відносин (r 1 , …, r n ) між формулами, звані правилами виведення.
Перевага логічних моделей уявлення знань полягає у можливості безпосередньо запрограмувати механізм виведення синтаксично правильних висловлювань. Прикладом такого механізму є, зокрема, процедура виведення, побудована на основі методу резолюцій.
Покажемо метод резолюцій.
У методі використовується кілька понять та теорем.
Концепція тавтології, логічної формули, значенням якої буде «істина» при будь-яких значеннях атомів, що входять до них. Позначається?, Читається як «загальнозначне» або «завжди істинно».
Теорема 1. А? У тоді і тільки тоді, коли?
Теорема 2. А1, А2, ..., Аn? У тоді і лише тоді, коли? (A1?A2?A3?…?An) Ст.
Символ? читається як «вірно, що» чи «можна вивести».
В основі методу лежить доказ тавтології
? (X? A)?(Y? ? A)?X? Y) .
Теореми 1 і 2 дозволяють записати це правило у такому вигляді:
(X? A), (Y? ? A) ? (X? Y),
що дає підстави стверджувати: з посилок можна вивести .
У процесі логічного висновку із застосуванням правила резолюції виконуються такі кроки.
1. Усуваються операції еквівалентності та імплікації:
2. Операція заперечення просувається всередину формул за допомогою законів де Моргана:
![]()
3. Логічні формули наводяться до диз'юнктивної форми: .
Правило резолюції містить у лівій частині кон'юнкцію диз'юнктів, тому приведення посилок, що використовуються для доказу, до виду, що є кон'юнкцією диз'юнктів, є необхідним етапом практично будь-якого алгоритму, що реалізує логічний висновок на базі методу резолюції. Метод резолюції легко програмується, це одна з найважливіших його переваг.
Припустимо, треба довести, що й справжні співвідношення і , можна вивести формулу . Для цього необхідно виконати такі кроки.
1.Приведення посилок до диз'юнктивної форми:
, , .
2. Побудова заперечення висновку, що виводиться. Отримана кон'юнкція справедлива, коли водночас істинні.
3. Застосування правила резолюції:
(Протиріччя або «порожній диз'юнкт»).
Отже, припустивши помилковість виведеного укладання, отримуємо протиріччя, отже, висновок є істинним, тобто. , Виводимо з вихідних посилок.
Саме правило резолюції стало базою для створення мови логічного програмування PROLOG. По суті, інтерпретатор мови PROLOG самостійно реалізує висновок, подібний до вищеописаного, формуючи відповідь на запитання користувача, звернений до бази знань.
У логіці предикатів застосування правила резолюції належить здійснити більш складну уніфікацію логічних формул з метою їх приведення до системи диз'юнктів. Це пов'язано з наявністю додаткових елементівсинтаксису, в основному кванторів, змінних, предикатів та функцій.
Алгоритм уніфікації предикатних логічних формул включає такі кроки.
Після виконання всіх кроків описаного алгоритму уніфікації можна застосовувати правило резолюції, Зазвичай при цьому здійснюється заперечення висновку, що виводиться, і алгоритм виведення можна коротко описати наступним чином: Якщо задано кілька аксіом (теорія Тh) і належить зробити висновок про те, чи виводиться деяка формула Рз аксіом теорії Тh, будується заперечення Рі додається до Тh, при цьому одержують нову теорію Тh1. Після приведення та аксіом теорії до системи диз'юнктів можна побудувати кон'юнкцію та аксіом теорії Тh. У цьому є можливість виводити з вихідних диз'юнктів диз'юнкти - слідства. Якщо Рвиведено з аксіом теорії Тh, то в процесі виведення можна отримати деякий диз'юнкт Q, що складається з однієї літери, і протилежний диз'юнкт йому . Це протиріччя свідчить у тому, що Рвиводиться з аксіом Тh. Взагалі кажучи, існує безліч стратегій доказу, нами розглянуто лише одну з можливих – низхідну.
Приклад: представимо засобами логіки предикатів наступний текст:
«Якщо студент вміє добре програмувати, то він може стати фахівцем у галузі прикладної інформатики».
«Якщо студент добре склав іспит з інформаційних систем, значить він вміє добре програмувати».
Уявімо цей текст засобами логіки предикатів першого порядку. Введемо позначення: X- Змінна для позначення студента; добре- Константа, що відповідає рівню кваліфікації; Р(Х)- Предикат, що виражає можливість суб'єкта Xстати фахівцем із прикладної інформатики; Q(Х, добре)- предикат, що означає вміння суб'єкта Xпрограмувати з оцінкою добре; R(Х, добре)- предикат, що задає зв'язок студента Xз екзаменаційною оцінкою інформаційних систем.
Тепер побудуємо безліч правильно побудованих формул:
Q(Х, добре).
R(Х, добре)Q(Х, добре).
Доповнимо отриману теорію конкретним фактом
R(Іванів, добре).
Виконаємо логічний висновок із застосуванням правила резолюції, щоб встановити, чи є формула Р(іванів) наслідком наведеної вище теорії. Іншими словами, чи можна вивести з цієї теорії факт, що студент Іванов стане фахівцем у прикладній інформатиці, якщо він добре склав іспит з інформаційних систем.
Доведення
1. Виконаємо перетворення вихідних формул теорії з метою приведення до диз'юнктивної форми:
(Х, добре) Р(Х);
(Х, добре) (Х, добре);
R(іванів, добре).
2. Додамо до наявних аксіом заперечення висновку, що виводиться
(Іванів).
3. Побудуємо кон'юнкцію диз'юнктів
(Х, добре) Р(Х)? ? P(Іванів, добре)? ? Q(Іванів, добре),замінюючи змінну Xна константу іванів.
Результат застосування правила резолюції називають резольвентою. В даному випадку резольвент є (Іванів).
4. Побудуємо кон'юнкцію диз'юнктів з використанням резольвенти, отриманої на кроці 3:
(Х, добре) (Х, добре) (Іванів, добре) (Іванів, добре).
5. Запишемо кон'юнкцію отриманої резольвенти з останнім диз'юнктом теорії:
(Іванів, добре) (Іванів, добре)(Протиріччя).
Отже, факт Р(іванів) виводимо з аксіом цієї теорії.
Для визначення порядку застосування аксіом у процесі виведення існують такі евристичні правила:
Однак за допомогою правил, що задають синтаксис мови, не можна встановити істинність чи хибність того чи іншого висловлювання. Це поширюється всіма мовами. Вислів може бути побудований синтаксично правильно, але виявитися абсолютно безглуздим. Високий ступінь однаковості також тягне за собою ще один недолік логічних моделей- Складність використання при доказі евристик, що відображають специфіку конкретної предметної проблеми. До інших недоліків формальних систем слід віднести їхню монотонність, відсутність засобів для структурування використовуваних елементів і неприпустимість протиріч. Подальший розвиток баз знань пішов шляхи робіт у галузі індуктивних логік, логік здорового глузду, логік віри та інших логічних схем, мало що мають спільного з класичною математичною логікою.
Якість розробленої БД повністю залежить від якості виконання окремих етапів її проектування. Величезне значення має якісна розробка логічної моделі даних, оскільки вона, з одного боку, забезпечує адекватність бази даних предметної області, з другого боку, визначає структуру фізичної БД і, отже, її експлуатаційні характеристики.
Одні й самі дані можуть групуватися в таблиці-отношения у різний спосіб, тобто. можлива організація різних наборів відносин взаємопов'язаних інформаційних об'єктів предметної галузі. Угруповання атрибутів у відносинах має бути раціональним, що гранично скорочує дублювання даних і спрощує процедури їх обробки та оновлення.
Певний набір відносин має найкращі властивості при включенні, модифікації та видаленні даних, якщо він відповідає конкретним вимогам нормалізації відносин.
Нормалізація відносин- Формальний апарат обмежень на їх формування, який дозволяє усунути дублювання даних, забезпечити їх несуперечність та зменшити витрати на підтримку БД.
На практиці найчастіше використовуються поняття першої, другої та третьої нормальних форм.
Ставлення називається нормалізованимабо наведеним до першої нормальної форми(1НФ), якщо всі його атрибути прості або атомарні (далі – неподільні). Відношення, що знаходиться в першій нормальній формі, матиме такі властивості:
■ щодо немає однакових кортежів;
■ кортежі не впорядковані;
■ атрибути не впорядковані та розрізняються за найменуваннями;
■ усі значення атрибутів атомарні.
Як видно з перерахованих властивостей, будь-яке відношення автоматично знаходиться у першій нормальній формі.
Легко показується, що перша нормальна форма допускає зберігання щодо різнорідної інформації, надмірності даних, які призводять до неадекватності логічної моделі даних предметної області. Таким чином, першої нормальної форми недостатньо для правильного моделювання даних.
Щоб розглянути питання приведення стосунків до другої нормальної форми, необхідно дати пояснення поняття функціональної залежності.
Нехай є відношення R.Багато атрибутів У функціонально залежно від безлічі атрибутів X,якщо для будь-якого стану відношення Rдля будь-яких кортежів з того, що слід, що, тобто. у всіх кортежах, що мають однакові значенняатрибутів X,значення атрибутів У також збігаються в будь-якому стані відношення R.
Безліч атрибутів Xназивається детермінантом функціональної залежності, а безліч атрибутів У – залежною частиною.
Насправді ці залежності відбивають взаємозв'язку, виявлені між об'єктами предметної області, і є додатковими обмеженнями, обумовленими предметної областю. Отже, функціональна залежність – семантичне поняття. Вона виникає, коли за значеннями одних даних предметної області можна визначити значення інших даних. Наприклад, знаючи табельний номер співробітника, можна визначити його прізвище. Функціональна залежність визначає додаткові обмеження на дані, які можуть зберігатися у відносинах. Для коректності БД необхідно під час операцій модифікації бази перевіряти всі обмеження, визначені функціональними залежностями.
Функціональна залежність атрибутів відносини нагадує поняття залежності математики. Функціональна залежність у математиці – це трійка об'єктів X, Yі f, де Х безліч, що представляє область визначення функції, Y- безліч значень, а f- правило, згідно з яким кожному елементу ставиться у відповідність один і тільки один елемент На противагу цьому у відносинах значення залежного атрибуту може приймати різні непередбачувані значення в різних станах БД, що відповідають різним станам предметної області. Наприклад, зміна співробітником прізвища при вступі до законного шлюбу призведе до того, що при тому значенні детермінанта, скажімо табельного номера, значення залежного аргументу буде іншим.
Функціональна залежність атрибутів стверджує лише те, що кожного конкретного стану БД за значенням одного атрибута можна однозначно визначити значення іншого атрибута. Конкретні значення залежної частини можуть бути різні в різних станах БД.
Ставлення знаходиться в другий нормальній формі(2НФ), якщо воно знаходиться у першій нормальній формі (1НФ) і немає неключових атрибутів, що залежать від частини складеного ключа.
З визначення 2НФ слід, що й потенційний ключ є простим, то ставлення автоматично перебуває у другій нормальній формі.
Однак відносини, наведені до другої нормальної форми, все-таки містять різнорідну інформацію та вимагають написання додаткового програмного кодуяк тригерів для коректної роботи БД. Наступним кроком щодо покращення якості відносин є приведення їх до третьої нормальної форми.
Ставлення знаходиться в третій нормальній формі(ДНФ), якщо воно знаходиться в 2НФ і всі неключові атрибути є взаємно незалежними.
Реляційна модель даних, що складається з відносин, наведених до 3НФ, є адекватною моделлю предметної області та вимагає наявності тільки тих тригерів, які підтримують посилальну цілісність. Такі тригери є стандартними, та його розробка вимагає великих зусиль.
Таким чином, розробку логічної моделі реляційної БД можна як визначення відносин, що відображають поняття предметної області, і приведення їх до третьої нормальної форми.
Алгоритм розробки включає три етапи.
Етап І. Приведення до 1НФ.Тут необхідно визначити та задати відносини, що відображають поняття предметної галузі. Усі відносини автоматично перебувають у 1НФ.
Етап ІІ. Приведення до 2НФ.Якщо в деяких відносинах виявлено залежність атрибутів від частини складного ключа, то слід провести їх декомпозицію таким чином: атрибути, які залежать від частини складного ключа, виносяться в окреме відношення разом з цією частиною ключа, а у вихідному відношенні залишаються всі ключові атрибути.
![]() . Ключ - складний ключ.
. Ключ - складний ключ.
- Залежність всіх атрибутів від ключа відносини;
- Залежність деяких атрибутів від частини складного ключа.
– частина вихідного відношення, що залишилася;
- Нове ставлення.
Етап ІІІ. Приведення до 3НФ.Якщо в деяких відносинах виявлена залежність одних неключових атрибутів від інших неключових атрибутів, то проводиться декомпозиція цих відносин: неключові атрибути, які залежать від інших неключових атрибутів,
утворюють окреме ставлення. У новому відношенні ключем стає детермінант функціональної залежності.
Нехай, наприклад, вихідне ставлення. До- Ключ.
Тоді функціональні залежності мають такий вигляд:

Після декомпозиції стосунки отримаємо:
Насправді досить рідко розробка логічної моделі БД проводиться у разі наведеному алгоритму. Найчастіше використовують різні варіанти ER-діаграм, які підтримуються відповідними CASE-засобами. Основні поняття ER-діаграм викладаються у стандартах IDEF1 та IDEF1X. Однак наведений алгоритм корисний як ілюстрація проблем, які можуть виникати щодо перших етапах проектування слабо нормалізованих відносин. Розуміння цих проблем особливо важливе при проведенні модифікацій та доопрацювань БД, коли вводяться нові сутності, з'являються нові залежності тощо.
Розробка інформаційних систем(ІВ) – це створення засобів управління інформацією. ІС приймають інформацію, за певними правилами переробляють її та віддають результат споживачам: на друк, на екран, навушники, передають в інші системи.
Тому для того, щоб створити якісну ІВ, не достатньо зрозуміти бізнес-процеси та потреби Замовника. Важливо розуміти, якою саме інформацією система має керувати. А для цього потрібно знати, які об'єкти потрапляють у предметну область проектованої ІВ та які логічні зв'язки між ними існують. Для формування такого розуміння використовуються логічні моделі предметної галузі.
Метою побудови логічної моделі є отримання графічного уявленнялогічної структури досліджуваної предметної галузі
Логічна модель предметної області ілюструє сутності, і навіть їх взаємовідносини між собою.
Сутності описують об'єкти, що є предметом діяльності предметної галузі, та суб'єкти, які здійснюють діяльність у рамках предметної області. Властивості об'єктів та суб'єктів реального світу описуються за допомогою атрибутів.
Взаємини між сутностями ілюструються з допомогою зв'язків. Правила та обмеження взаємовідносин описуються за допомогою властивостей зв'язків. Зазвичай зв'язки визначають або залежність між сутностями, або вплив однієї сутності іншу.
Приклад: Замовлення піци
Клієнт оформляє замовлення на придбання піци. У загальному випадку клієнт може замовити різну кількість піци різних сортів. Тому кожне замовлення включає позиції. Кожна позиція вказує сорт піци, яку клієнт хоче одержати, і навіть її кількість.

1. Логічна модель повинна відображати всі сутності та зв'язки, значущі для тієї мети, заради якої ми її малюємо.
2. Усі об'єкти моделі (і сутності, і зв'язку) мають бути іменовані. Найменування сутностей і зв'язків має виконуватися в термінах предметної області.
3. Для зв'язків має бути зазначена кратність (один – багато).
4. Для кожного зв'язку має бути зазначений напрямок читання.
Приклад: на модель додані найменування зв'язків, їх розмірності та напрямок читання.

5. Для сутностей мають бути вказані як мінімум основні атрибути.
Приклад: для сутностей наведені основні атрибути

<Сущность 1> — <отношение / влияние> — <Сущность 2>.
Читання раніше розглянутого прикладу: Клієнт оформляє замовлення. Замовлення включає позиції, у кожній з яких вказується якого сорту піцу і в якій кількості бажає отримати клієнт.
Клієнт може існувати без замовлення. Однак, замовлення неможливо зареєструвати без вказівки клієнта. Один клієнт може оформити необмежену кількість замовлень
Відповідно до моделі в одному замовленні може бути нескінченна кількість позицій. Потрібно уточнити, наскільки це коректно.
2. Модель має бути структурована, сутності мають бути згруповані за логічним змістом.
3. Вкрай бажано уникати перетину зв'язків.
4. Розташування об'єктів моделі має бути таким, щоб її було зручно читати.
Є одне спостереження - якщо на модель дивитися приємно, то швидше за все вона виконана якісно.
Без відповідей на ці питання розробка моделі втрачає будь-який сенс, оскільки ми робитимемо щось, від чого особливо нічого не очікуємо. Відповідним буде результат.
Відповіді на ці питання дають нам вимоги до моделі, а в ході розробки дозволять приймати рішення щодо її розвитку та судити про її якість.
Як правило, відповідь на це питання випливає з розуміння завдання, що стоїть перед бізнес-аналітиком.
Найчастіше межі моделювання визначаються або досліджуваними бізнес-процесами, або фрагментом інформаційного простору компанії, які під вирішуване завдання.
Розробка логічної моделі – ітеративний процес. Вона повинна послідовно, у міру опрацювання предметної області та поставленого завдання, уточнюватись та деталізуватися.
Логічну модель треба будувати так, щоб сутності називалися іменниками, зв'язки — дієсловами, а читання діаграми народжувало б нехай і кострубаті, але пропозиції, що описують те, що відбувається в предметній області. Якщо цього вдалося досягти, то модель вийшла чудова. Якщо таке не вдалося, то розробнику моделі ще є над чим попрацювати.
Важливо пам'ятати, що логічна модель — це не структура бази даних, це логічна структура предметної галузі твого завдання. Виключаючи її з атрибутів, що розробляються, ти позбавляєш себе ефективного інструменту аналізу та проектування, що дозволяє дуже точно врахувати аспекти бізнесу, що не ілюструються динамічними моделями.
І навпаки — своєчасне та грамотне використання логічної моделі робить її дуже сильним інструментом у руках бізнес-або системного аналітика.
 Сергій Калінов
Сергій Калінов
Провідний бізнес-аналітик
| Статті на тему: | |
|
Xiaomi Mi6: потужна придатність з подвійною камерою
Смартфони Xiaomi все частіше можна побачити в руках звичайних людей, але... Як повністю видалити аваст Утиліта для видалення аваст з комп'ютера
Антивірус легко встановити, але складно видалити, і ця стаття розповість... Простий блок живлення Блок живлення 12в своїми руками схема
Усім нам відомо, що блоки живлення сьогодні є невід'ємною. | |