вибір читачів





Популярні статті
Яндекс.Діск - один з небагатьох сервісів Яндекса, частиною якого є програмне забезпечення для робочого столу. І одна з найважливіших його складових - алгоритм синхронізації локальних файлів з їх копією в хмарі. Нещодавно нам довелося його повністю поміняти. Якщо стара версія насилу переварювала навіть кілька десятків тисяч файлів і до того ж не досить швидко реагувала на деякі «складні» дії користувача, то нова, використовуючи ті ж ресурси, справляється з сотнями тисяч файлів.
У цьому пості я розповім, чому так вийшло: чого ми не змогли передбачити, коли придумували першу версію ПО Яндекс.Діск, і як створювали нову.
Перш за все, про самій задачі синхронізації. Технічно кажучи, вона полягає в тому, щоб в папці Яндекс.Діск на комп'ютері користувача і в хмарі був один і той же набір файлів. Тобто такі дії користувача, як перейменування, видалення, копіювання, додавання і зміна файлів, повинні синхронізуватися з хмарою автоматично.
Ситуація може стати ще складніше, якщо з одним аккаунтом одночасно працюють кілька користувачів або у них є загальна папка. А це трапляється досить часто в організаціях, що використовують Яндекс.Діск. Уявіть собі, що в попередньому прикладі в той момент, коли ми отримали від бекенда підтвердження першого перейменування, інший користувач бере і перейменовує цю папку ще раз. В цьому випадку знову не можна відразу виконати дії, які вже зробив перший користувач у себе на комп'ютері. Папка, в якій він працював локально, на бекенде в цей час вже називається по-іншому.
Бувають випадки, коли файл на комп'ютері користувача не можна назвати так само, як він називається в хмарі. Це може статися, якщо в імені є символ, який не може використовуватися локальної файлової системою, або в тому випадку, коли користувача запрошують в загальну папку, а у нього є своя папка з таким ім'ям. У таких випадках нам доводиться використовувати локальні псевдоніми і відстежувати їх зв'язок з об'єктами в хмарі.
У цій версії алгоритму ми використовували три основних дерева: локальне (Local Index), хмарне (Remote Index) і останнім синхронізоване (Stable Index). Крім цього, щоб запобігти повторну генерацію вже поставлених в чергу операцій синхронізації, використовувалися ще два допоміжних дерева: локальне очікуване і хмарне очікуване (Expected Remote Index і Expected Local Index). У цих допоміжних деревах зберігалося очікуване стан локальної файлової системи і хмари, після виконання всіх операцій синхронізації, які вже поставлені в чергу.
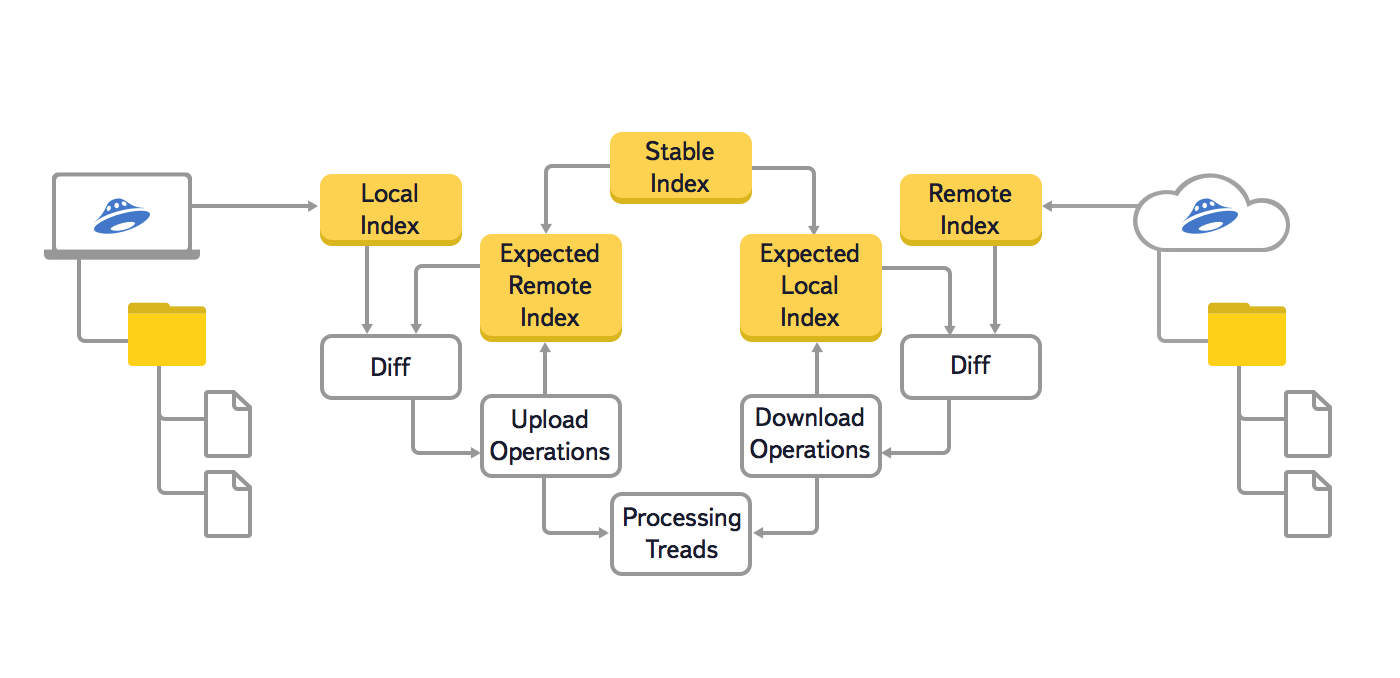
Також ми хотіли збільшити максимальну кількість файлів, з яким без проблем може працювати користувач. Кілька десятків і навіть сотень тисяч файлів може виявитися, наприклад, у фотографа, який зберігає в Яндекс.Діск результати фотосесій. Це завдання стало особливо актуальним, коли у людей з'явилася можливість купити додаткове місце на Яндекс.Діск.
У розробці теж хотілося дещо поміняти. Налагодження старої версії викликала труднощі, так як дані про стани одного елемента знаходилися в різних деревах.
До цього часу на бекенде з'явилися id об'єктів, за допомогою яких можна було більш ефективно вирішити задачу виявлення переміщень - раніше ми використовували шляху.
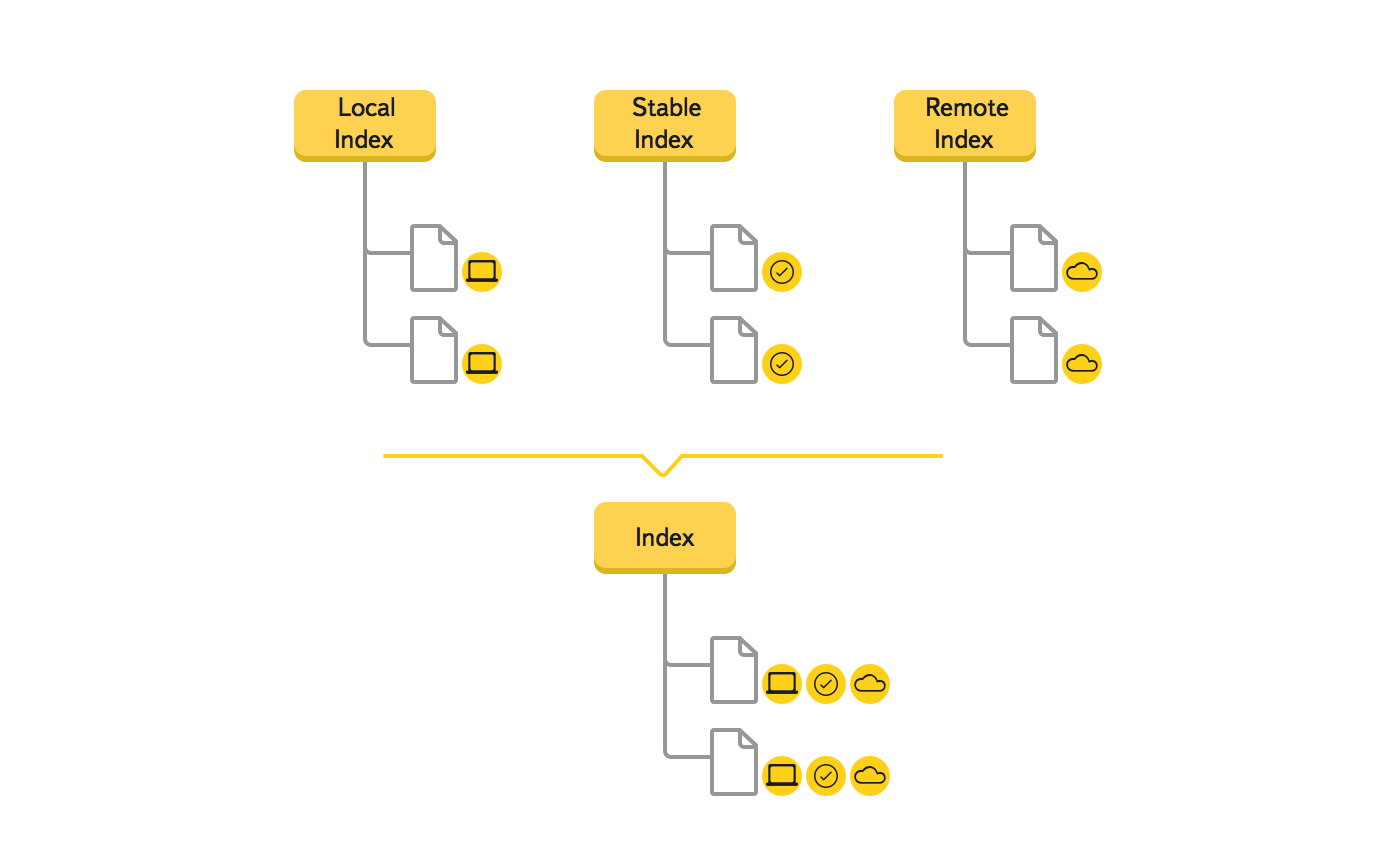
Так як ми розуміли, що це серйозна зміна, то створили прототип, який підтвердив ефективність нового рішення. Розглянемо на прикладі, як змінюються дані в дереві під час синхронізації нового файлу.

Яндекс.Діск використовує дайджести sha256 і MD5 для перевірки цілісності файлів, виявлення змінених фрагментів і дедуплікаціі файлів на бекенде. Так як ця задача сильно навантажує CPU, в новій версії реалізація розрахунків дайджесту була істотно оптимізовано. Швидкість отримання дайджесту файлу збільшена приблизно в два рази.
В результаті виконаних змін істотно збільшилася кількість файлів, з яким без проблем справляється програма. У версії для Windows - 300 000, а на Mac OS X - 900 000 файлів.
Ні для кого не секрет, для чого потрібно проводити резервне копіювання. Наприклад, веб-розробнику буде зручно робити резервні копії, якщо в процесі розробки він непомітно для самого себе зробить помилку, а через кілька годин помилка "спливе" на поверхню і на пошуки і усунення помилки часу зовсім не залишилося. Звичайно, у Vscale є система резервного копіювання, але вона передбачає тільки копіювання даних за все сервера цілком. Та й можливість відновлення з резервної копії доступна тільки на тому сервері, з якого і була зроблена копія. Така можливість не зовсім задовольняє потреби умовного веб-розробника. Однак, зараз в світі добре розвинулася "хмарна" тенденція: хмарні хостинг, хмарна VPS, хмарне зберігання даних і так далі. У цьому керівництві ми розповімо, як налаштувати хмарне зберігання резервних копій. Допоможе нам у цьому Яндекс.Діск.
Приступимо до встановлення ключового компонента - клієнта для Я.Діска. Оскільки в стандартному списку репозиторіїв відсутня пакет з клієнтом Я.Діска, доведеться додати репозиторій вручну, після чого оновити індекс пакетів і тільки потім встановити пакет з клієнтом. На сайті Я.Діска представлений список потрібних команд в одному рядку:
echo "Deb http://repo.yandex.ru/yandex-disk/deb/ stable main"| sudo tee -a /etc/apt/sources.list .d / yandex.list> / dev / null && wget http: //repo.yandex.ru/yandex-disk/YANDEX-DISK-KEY.GPG -O- | sudo apt-key add - && sudo apt-get update && sudo apt-get install -y yandex-diskЯндекс-клієнт успішно встановлений, і можна приступати до налаштування. В Яндексі подбали про те, щоб клієнт працював з файлами по мінімуму і додали можливість налаштувати все однією командою:
Yandex-disk setup
Порядок роботи представленої вище команди:
Автозапуск Я.Діска включите обов'язково, а інші пункти можете налаштовувати на свій розсуд. На цьому настройку можна вважати завершеною.
Для того, щоб створити резервну копію, потрібно використовувати безліч команд. Допомогти в цьому може python або perl, але зручніше за все це робити за допомогою bash. Він простий і зручний у використанні і безпосередньо взаємодіє з консоллю. Створіть bash-скрипт:
Nano /var/backup.sh
Вставте в нього наступний код:
SERVER_PATH = "/ var / www / html"
cur_date = `date +% Y-% m-% d`
filename = "backup -" $ cur_date ".tar.bz2"
tar -cjf $ filename $ SERVER_PATH
if [-f $ filename]; then
mv $ filename /root/Yandex.Disk/backup/
yandex-disk sync
fi
Збережіть файл, натисніть сполучення клавіш Ctrl + O, Підтвердіть дію клавішею Enterі закрийте файл, натисніть сполучення клавіш Ctrl + X. Обов'язково призначте права доступу до файлу, щоб у нього був доступ до системних командам (створення і переміщення папок, доступ до каталогів):
Cd / var
chmod -R 755 * backup.sh
Коротко про те, що робить скрипт:
Перевірити, чи працює скрипт, можна за допомогою наступної команди:
Cd / var && ./backup.sh
В результаті виконання команди архів буде завантажений в хмарне сховище.
Наступним і завершальним кроком буде додавання скрипта в планувальник завдань. Допоможе нам у цьому crontab. Відкрийте список запланованих завдань:
Crontab -e
У самий кінець додайте рядок:
0 0 * * * /var/backup.sh
Тепер Crontab буде запускати скрипт кожен день опівночі. На цьому настройка автоматичного створення резервної копії завершена.
Ви успішно налаштували автоматичне створення резервної копії для директорії з вашим веб-сайтом. Це дуже корисний алгоритм, що дозволяє уникнути втрату резервної копії в тому випадку, якщо б вона зберігалася на самому сервері. За таким же принципом можна робити і резервні копії конфігураційних файлів. В цілому хмарні технології хороші тим, що забезпечують високу доступність і безпеку зберігання особистих даних. Вибір на користь хмари - це хороший вибір.
Викладати бекапи проектів (сайтів) на Яндекс.Діск може знадобитися з кількох причин, наприклад, через брак місця на сервері (хостингу, VDS, VPS) або для підвищення безпеки зберігання бекапів (на випадок, якщо сервер без рейду і він вийде з ладу).
У зв'язку з цим я написав для себе і вирішив викласти для інших невеликої bash-скрипт для бекапу на Яндекс.Діск. Функції скрипта:
- Створення на сервері бекапу проектів (файлів + баз даних MySQL);
- Авторизація на Яндекс.Діск як додаток (по токені, більш безпечний спосіб, ніж використання логіна і пароля);
- Відправлення бекапів з сервера на Яндекс.Діск;
- Видалення старих бекапів з Яндекс.Діск для економії місця (налаштовується максимальну кількість збережених бекапів);
- Запис і відправка балки на e-mail (налаштовується).
Для того, щоб скористатися скриптом, необхідно спочатку отримати токен від Яндекс.Діск. Приступимо.
1. логін на Яндексі під аккаунтом, на диск якого будемо робити бекап, заходимо на oauth.yandex.ru і натискаємо «Зареєструвати новий додаток».
2. Заповнюємо назву програми (наприклад, «backup») і видаємо потрібні права в розділі «Яндекс.Діск REST API», а саме: «Доступ до інформації про Диску» і «Доступ до теки програми на Диску».
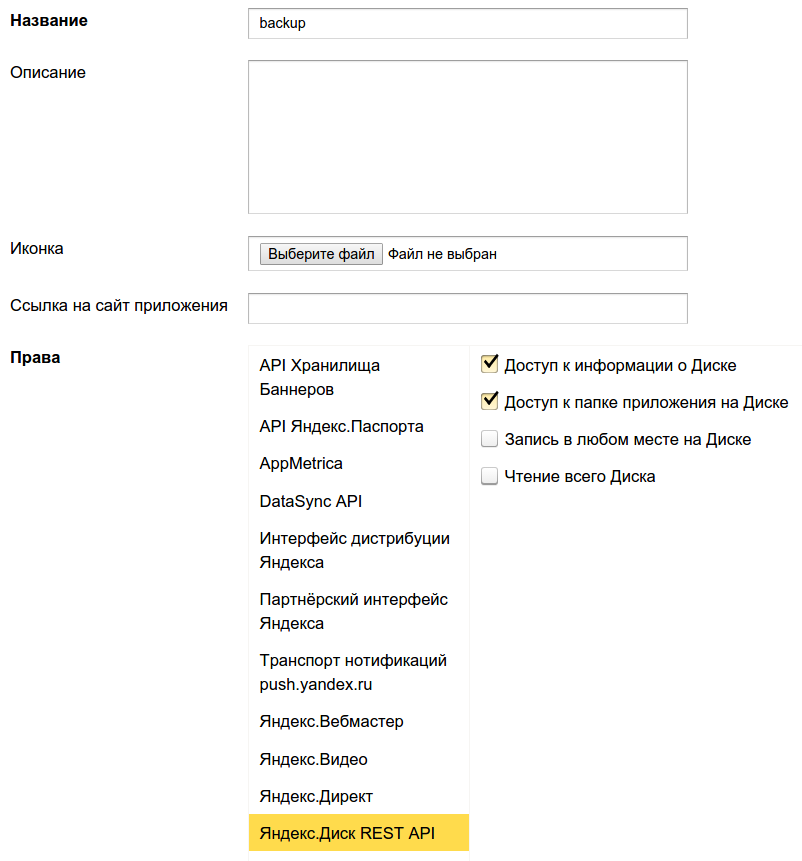
Нижче на тій же сторінці під полем «Callback URL» натискаємо «підставити URL для розробки» і натискаємо «Зберегти»:

3. Після збереження параметрів програми нас перенаправляють на сторінку з даними про програму:
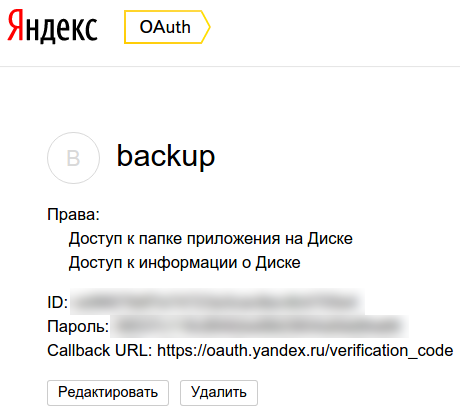
4. Тепер отримаємо сам токен (якщо хочете, можете почитати докладніше про це в мануалі Яндекса), для цього копіюємо ID, підставляємо в кінець URL https://oauth.yandex.ru/authorize?response_type=token&client_id=, переходимо з що вийшло адресою і підтверджуємо видачу дозволів з додатком:
![]()
У підсумку на сторінці буде відображений токен, який видається не менше, ніж на 1 рік, тому якщо скрипт бекапа раптом перестане працювати, ми зможемо отримати новий токет і підставити його в скрипт. Протестувати можливості роботи з Яндекс.Діск, використовуючи отриманий токен, можна на спеціальному полігоні.
А тепер сам bash-скрипт для бекапу на Яндекс.Діск:
#! / Bin / bash # # Yandex.Disk backup script v1.0 by Sergey Lukonin (neblog.info) # # # # # # # # # # # НАЛАШТУВАННЯ бекап MYSQL # # # # # # # # # # # Сервер БД MYSQL_SERVER = mysql.some-server.ru # Юзер, під яким будемо робити бекап доступних баз, руту mysql зазвичай доступні всі БД, окремому користувачеві зазвичай доступна БД конкретного проекту MYSQL_USER = some-user # Пароль користувача бази даних (Пароль від рута сервера і від рута mysql різні не плутайте) MYSQL_PASSWORD = some-password # # # # # # # # # # ЗАГАЛЬНІ НАЛАШТУВАННЯ # # # # # # # # # # # Директорія для тимчасового зберігання бекапів, які видаляються після відправки на Яндекс .. диску бекапів (0 - зберігати все бекапи): MAX_BACKUPS = "14" # Дата, використовується в іменах архівів DATE = `date" +% Y-% m-% d "` # Директорії для архівації (вказуються через пробіл), які будуть поміщені в єдиний архів і відправлені на Яндекс.Діск DIRS = "/ home / www / projects / neblog" # Yandex.Disk токен (як отримати - см. на neblog.info) TOKEN = "" # Ім'я лог-файлу, зберігається в дир Ектор, зазначеної в $ BACKUP_DIR LOGFILE = "backup.log" # E-mail для відправки результату виконання скрипта. Залиште порожнім, якщо відправляти результати не потрібно. sendLog = " [Email protected] "# Відправляти тільки помилки (true). Вкажіть false, якщо потрібно відправляти логи при будь-якому результаті виконання скрипта. SendLogErrorsOnly =" false "# # # # # # # # # # КІНЕЦЬ НАСТРОЕК # # # # # # # # # # # # # # # # # # # # # ДАЛІ НІЧОГО НЕ МІНЯЄМО! # # # # # # # # # # function mailing () (if [! $ sendLog = ""]; then if [ "$ sendLogErrorsOnly" == true ]; then if echo "$ 1" | grep -q "error" then echo "$ 2" | mail -s "$ 1" $ sendLog> / dev / null fi else echo "$ 2" | mail -s "$ 1" $ sendLog> / dev / null fi fi) function logger () (echo "[" `date" +% Y-% m-% d% H:% M:% S "` "] File $ BACKUP_DIR: $ 1" >> $ BACKUP_DIR / $ LOGFILE) function parseJson () (local output regex = "(\" $ 1 \ ": [\"]?) ([^ \ ", \)] +) ([\"]?) "[[$ 2 = ~ $ regex]] && output = $ (BASH_REMATCH) echo $ output) function checkError () (echo $ (parseJson "error" "$ 1")) function getUploadUrl () (json_out = `curl -s -H" Authorization: OAuth $ TOKEN "https: //cloud-api.yandex.net: 443 / v1 / disk / resources / upload /? path = app: / $ backupName & overwrite = true` json _error = $ (checkError "$ json_out") if [[$ json_error! = ""]]; then logger "$ PROJECT - Yandex.Disk error: $ json_error" mailing "$ PROJECT - Yandex.Disk backup error" "ERROR copy file $ FILENAME. Yandex.Disk error: $ json_error" echo "" else output = $ (parseJson " href "$ json_out) echo $ output fi) function uploadFile (local json_out local uploadUrl local json_error uploadUrl = $ (getUploadUrl) if [[$ uploadUrl! =" "]]; then echo $ UploadUrl json_out =` curl -s -T $ 1 -H "Authorization: OAuth $ TOKEN" $ uploadUrl` json_error = $ (checkError "$ json_out") if [[$ json_error! = ""]]; then logger "$ PROJECT - Yandex.Disk error: $ json_error" mailing " $ PROJECT - Yandex.Disk backup error "" ERROR copy file $ FILENAME. Yandex.Disk error: $ json_error "else logger" $ PROJECT - Copying file to Yandex.Disk success "mailing" $ PROJECT - Yandex.Disk backup success "" SUCCESS copy file $ FILENAME "fi else echo" Some errors occured. Check log file for detail "fi) function backups_list () (# Шукаємо в директорії додатку всі файли бекапів і виводимо їх назви : Curl -s -H "Authorization: OAuth $ TOKEN" "https://cloud-api.yandex.net:443/v1/disk/resources?path=app:/&sort=created&limit=100" | tr "()," "\ n" | grep "name [[: graph:]] *. tar.gz" | cut -d: -f 2 | tr -d "" ") function backups_count () (local bkps = $ (backups_list | wc -l) # Якщо ми бекап і файли, і БД, то на 1 бекап у нас припадає 2 файли. Тому кількість бекапів = кількість файлів / 2: expr $ bkps / 2) function remove_old_backups () (bkps = $ (backups_count) old_bkps = $ ((bkps - MAX_BACKUPS)) if [ "$ old_bkps" -gt "0"]; then logger "Видаляємо старі бекапи з Яндекс . Диска "# Цикл видалення старих бекапів: # Виконуємо видалення першого в списку файлу 2 * old_bkps раз for i in` eval echo (1 .. $ ((old_bkps * 2))) `; do curl -X DELETE -s -H" Authorization: OAuth $ TOKEN "" https://cloud-api.yandex.net:443/v1/disk/resources?path=app:/$(backups_list | awk "(NR == 1)") & permanently = true " done fi) logger "--- $ PROJECT START BACKUP $ DATE ---" logger "Вивантажуємо дампи баз" mkdir $ BACKUP_DIR / $ DATE for i in `mysql -h $ MYSQL_SERVER -u $ MYSQL_USER -p $ MYSQL_PASSWORD -e" show databases; "| grep -v information_schema | grep -v Database`; do mysqldump -h $ MYSQL_SERVER -u $ MYSQL_USER -p $ MYSQL_PASSWORD $ i> $ BACKUP_DIR / $ DATE / $ i.sql; done logger" Створюємо архів mysql $ BACKUP_DIR / $ DATE-mysql- $ PROJECT.tar.gz "tar -czf $ BACKUP_DIR / $ DATE-mysql- $ PROJECT.tar.gz $ BACKUP_DIR / $ DATE rm -rf $ BACKUP_DIR / $ DATE logger" Створюємо архів каталогів $ BACKUP_DIR / $ DATE-files- $ PROJECT.tar.gz "tar -czf $ BACKUP_DIR / $ DATE-files- $ PROJECT.tar.gz $ DIRS FILENAME = $ DATE-mysql- $ PROJECT.tar.gz logger" вигр вантажують на Яндекс.Діск архів mysql $ BACKUP_DIR / $ DATE-mysql- $ PROJECT.tar.gz "backupName = $ DATE-mysql- $ PROJECT.tar.gz uploadFile $ BACKUP_DIR / $ DATE-mysql- $ PROJECT.tar.gz FILENAME = $ DATE-files- $ PROJECT.tar.gz logger "Вивантажуємо на Яндекс.Діск архів з файлами $ BACKUP_DIR / $ DATE-files- $ PROJECT.tar.gz" backupName = $ DATE-files- $ PROJECT.tar. gz uploadFile $ BACKUP_DIR / $ DATE-files- $ PROJECT.tar.gz logger "Видаляємо архіви з диска" find $ BACKUP_DIR -type f -name "* .gz" -exec rm "()" \; # Видаляємо старі бекапи з Яндекс.Діск (якщо MAX_BACKUPS> 0) if [$ MAX_BACKUPS -gt 0]; then remove_old_backups; fi logger "Завершення скрипта бекапу"
Також ви можете скачати готовий. Скрипт слід розташувати на сервері, замінити в ньому параметри на свої, дати права на запуск (chmod + x) і поставити на щоденне виконання в cron. Якщо ви плануєте виконувати кілька таких завдань, задайте час між їх запуском (5-10 хвилин).
У сучасному світі все більшу цінність отримує інформацію, втрата якої може обернутися серйозними фінансовими витратами. Сайт є цінною інформацією, резервну копію якого, або просто бекап, ми зробимо в цій статті на прикладі wordpress і розмістимо на яндекс диску. Я розгляну варіант автоматизації процесу, який придумав для своїх потреб і використовую досить давно і успішно.
Рухатися будемо поетапно. Спочатку просто розглянемо варіант бекапа безпосередньо файлів сайту і бази даних. А потім повністю відповімо на питання про те як зробити регулярну резервну копію сайту на wordpress.
Тут я не винаходив велосипеда, а скористався стандартним способом архівування файлів - архиватором tar. Всі коментарі і пояснення напишу відразу в скрипті:
#! / Bin / sh # Задаємо змінні # Поточна дата у форматі 2015-09-29_04-10 date_time = `date +"% Y-% m-% d_% H-% M "` # Куди розміщуємо backup bk_dir = "/ mnt / backup / site1.ru "# Директорія на рівень вище тієї, де лежать файли inf_dir =" / web / sites / site1.ru / "# Назва безпосередньо директорії з файлами dir_to_bk =" www "# Створення архіву / usr / bin / tar -czvf $ bk_dir / www_ $ date_time.tar.gz -C $ inf_dir $ dir_to_bk
На виході після роботи скрипта маємо папку з ім'ям www_2015-09-29_04-10.tar.gz, всередині якої буде лежати папка www з усім вмістом. Спочатку, ця папка розташовувалася за адресою /web/sites/site1.ru/www. Тут я застосував tar з параметром -Здля того, щоб в архіві не було точного шляху /web/sites/site1.ru, а була тільки папка www. Мені просто так зручніше.
Можна користуватися окремо цим скриптом для створення архівів файлів, не обов'язково сайту. Кладемо його в cronі отримуємо регулярну архівацію.
Тепер зробимо скрипт для резервної копії бази даних. Тут теж нічого особливого, використовую стандартний засіб mysqldamp:
#! / Bin / sh # Задаємо змінні # Поточна дата у форматі 2015-09-29_04-10 date_time = `date +"% Y-% m-% d_% H-% M "` # Куди розміщуємо backup bk_dir = "/ mnt / backup / site1.ru "# Користувач бази даних user =" user1 "# Пароль користувача password =" pass1 "# Ім'я бази для бекапа bd_name =" bd1 "# Вивантажуємо базу / usr / bin / mysqldump --opt -v - -databases $ bd_name -u $ user -p $ password | / Usr / bin / gzip -c> $ bk_dir / mysql_ $ date_time.sql.gz
На виході маємо файл з дампом бази mysql_2015-09-29_04-10.sql.gz. Дамп зберігається в текстовому форматі, можна відкривати і редагувати будь-яким редактором.
Існує досить зручний і безкоштовний сервіс Я ндекс.Діск, який може використовувати будь-який бажаючий. Безкоштовно дається не так багато місця, але для бекапа сайту на wordpress вистачить. До слова, у мене за допомогою всіляких акцій безкоштовно доступно 368 ГБ:
Я ндекс.Діск можна підключити за допомогою webdav. У мене в якості сервера виступає CentOS 7, я розповім як подмонтировать в ній. Насамперед підключаємо. Потім встановлюємо пакет davfs2:
# Yum -y install davfs2
Тепер пробуємо подмонтировать диск:
# Mkdir / mnt / yadisk # mount -t davfs https://webdav.yandex.ru / mnt / yadisk / Please enter the username to authenticate with server https://webdav.yandex.ru or hit enter for none. Username: Please enter the password to authenticate user [Email protected] with server https://webdav.yandex.ru or hit enter for none. Password: /sbin/mount.davfs: Warning: can "t write entry into mtab, but will mount the file system anyway
Я ндекс.Діск змонтований в папку / mnt / yadisk.
Щоб автоматизувати процес архівації і не вводити кожен раз ім'я користувача і пароль, відредагуємо файл / etc / davfs2 / secrets, додавши в кінець новий рядок з ім'ям користувача і паролем:
# Mcedit / etc / davfs2 / secrets / mnt / yadisk / [Email protected] password
Тепер при монтуванні диска ніяких питань задаватися не буде. Можна додати підключення яндекс диска в fstab, Щоб він монтувався автоматично при завантаженні, але я вважаю це зайвим. Я підключаю і відключаю диск в скрипті бекапа. Якщо ж ви хочете його монтувати автоматично, додайте в fstab:
Https://webdav.yandex.ru / mnt / yadisk davfs rw, user, _netdev 0 0
Окремо розібрали всі елементи створення резервної копії сайту, тепер прийшла черга зібрати все це в одному місці. Я використовую наступну схему бекапа сайту:
З такою схемою ми завжди маємо під рукою 7 останніх архівів, тижневі архіви поточного місяця і архів за кожен місяць на всякий випадок. Пару раз мене така схема виручала, коли потрібно було щось дістати з резервної копії тижневої давності, наприклад.
Наводжу 3 повних скрипта по створенню резервної копії сайту wordpress, саме цей движок я найчастіше використовую, але реально можна бекапіть будь-який сайт - joomla, drupal, modx і ін. Принципового значення cms або фреймворк не має.
Скрипт щоденного бекапа сайту backup-day.sh:
day"# Директорія для архіву inf_dir =" / web / sites / site1.ru / "# Назва безпосередньо директорії з файлами dir_to_bk =" www "# Користувач бази даних user =" user1 "# Пароль користувача password =" pass1 "# Ім'я бази для бекапа bd_name = "bd1" # Монтуємо Яндекс.Діск mount -t davfs https://webdav.yandex.ru / mnt / yadisk / # Створення архіву початкових кодів / usr / bin / tar -czvf $ bk_dir / www_ $ date_time.tar. gz -C $ inf_dir $ dir_to_bk # Вивантажуємо базу даних / usr / bin / mysqldump --opt -v --databases $ bd_name -u $ user -p $ password | / usr / bin / gzip -c> $ bk_dir / mysql_ $ date_time.sql.gz # Видаляємо архіви старше 7-ми днів / usr / bin / find $ bk_dir -type f - mtime +7
Скрипт щотижневого бекапа сайту backup-week.sh:
#! / Bin / sh # Задаємо змінні # Поточна дата у форматі 2015-09-29_04-10 date_time = `date +"% Y-% m-% d_% H-% M "` # Куди розміщуємо backup bk_dir = "/ mnt / yadisk / site1.ru / weeek"# Директорія для архіву inf_dir =" / web / sites / site1.ru / "# Назва безпосередньо директорії з файлами dir_to_bk =" www "# Користувач бази даних user =" user1 "# Пароль користувача password =" pass1 "# Ім'я бази для бекапа bd_name = "bd1" # Монтуємо Яндекс.Діск mount -t davfs https://webdav.yandex.ru / mnt / yadisk / # Створення архіву початкових кодів / usr / bin / tar -czvf $ bk_dir / www_ $ date_time.tar. gz -C $ inf_dir $ dir_to_bk # Вивантажуємо базу даних / usr / bin / mysqldump --opt -v --databases $ bd_name -u $ user -p $ password | / usr / bin / gzip -c> $ bk_dir / mysql_ $ date_time.sql.gz # Видаляємо архіви старше 30-ти днів / usr / bin / find $ bk_dir -type f -mtime +30-exec rm () \; # Відключаємо Яндекс.Діск umount / mnt / yadisk
Скрипт щомісячного бекапа сайту backup-month.sh:
#! / Bin / sh # Задаємо змінні # Поточна дата у форматі 2015-09-29_04-10 date_time = `date +"% Y-% m-% d_% H-% M "` # Куди розміщуємо backup bk_dir = "/ mnt / yadisk / site1.ru / month"# Директорія для архіву inf_dir =" / web / sites / site1.ru / "# Назва безпосередньо директорії з файлами dir_to_bk =" www "# Користувач бази даних user =" user1 "# Пароль користувача password =" pass1 "# Ім'я бази для бекапа bd_name = "bd1" # Монтуємо Яндекс.Діск mount -t davfs https://webdav.yandex.ru / mnt / yadisk / # Створення архіву початкових кодів / usr / bin / tar -czvf $ bk_dir / www_ $ date_time.tar. gz -C $ inf_dir $ dir_to_bk # Вивантажуємо базу даних / usr / bin / mysqldump --opt -v --databases $ bd_name -u $ user -p $ password | / usr / bin / gzip -c> $ bk_dir / mysql_ $ date_time.sql.gz # Відключаємо Яндекс.Діск umount / mnt / yadisk
Не забудьте створити директорію /mnt/yadisk/site1.ru на яндекс диску, а в ній ще 3 папки: day, week, month:# Cd /mnt/yadisk/site1.ru && mkdir day week month
Тепер для автоматизації додаємо ці 3 файлу в cron:
# Mcedit / etc / crontab # site backup to yandex.disk # щодня о 4:10 10 4 * * * root /root/bin/backup-day.sh> / dev / null 2> & 1 # щотижня о 4:20 в неділю 20 4 * * 0 root /root/bin/backup-week.sh> / dev / null 2> & 1 # щомісяця о 4:30 1-го числа місяця 30 4 1 * * root / root / bin / backup-month .sh> / dev / null 2> & 1
Все, наш wordpress надійно забекаплен. За ідеєю, сюди потрібно прикрутити оповіщення на пошту, але у мене всю руки не доходять це зробити. Та й за кілька місяців використання у мене не було жодного збою.
Тепер розглянемо варіант, коли вам необхідно відновити сайт з резервної копії. Для цього нам знадобляться обидва архіву: вихідні коди і база даних. Розархівувати в принципі можна де завгодно. У windows архіви відкриваються безкоштовним архіватором 7zip. Дамп бази даних в звичайному текстовому форматі, його можна відкрити блокнотом, скопіювати і вставити в phpmyadmin.

Так що варіантів відновлення може бути багато, цим мені і подобається такий підхід. Всі файли у відкритому вигляді, з ними можна працювати будь-якими підручними засобами.
Ось приклад того, як витягти файли з архіву в консолі сервера. Разархівіруем каталог www з резервної копії:
# Tar -xzvf www_2015-10-01_04-10.tar.gz
Файли витягнуті в папку www. Тепер їх можна скопіювати в папку з сайтом.
Для відновлення бази даних чинимо так. Спочатку розпакуємо архів:
# Gunzip mysql_2015-10-01_04-10.sql.gz
Тепер заллємо дамп в базу даних:
# Mysql --host = localhost --user = user1 --password = pass1 bd1; MariaDB [(none)]> source mysql_2015-10-01_04-10.sql;
Все, база даних відновлена.
Необхідно врахувати, що база буде відновлена в базу з оригінальним ім'ям і замінить її вміст, якщо така на сервері є. Щоб відновити базу в іншу, необхідно відредагувати початок дампа і замінити там назву бази на нове. Якщо відновлення відбувається на іншому сервері, то це не має значення.
Отже, ми розглянули варіанти створення резервних копій сайту і бази даних на прикладі движка wordpress. При цьому використовували тільки стандартні засоби сервера. Як приклад ми використовували приймач для зберігання копій Я ндекс.Діск, але ніщо не заважає адаптувати його під будь-який інший. Це може бути окремий жорсткий або зовнішній диск, інше хмарне сховище даних, яке можна подмонтировать до сервера.
Схема створення бекапа дозволяє відкотитися практично на необмежений час назад. Глибину архівів ви можете самі задавати, змінюючи параметр mtimeв скрипті. Можна зберігати, наприклад, щоденний архів не 7 днів, як роблю я, а 30, якщо у вас є така потреба. Так що пробуйте, адаптуйте під себе. Якщо є якісь зауваження по роботі, помилки або пропозиції щодо поліпшення функціоналу, діліться своїми думками в коментарях, буду радий їх почути.
Вітаю вас, дорогі читачі мого блогу. Ви, напевно, чули про програму, що дозволяє зберігати файли на сервері Яндекса. Якщо немає, ласкаво просимо на soft.yandex.ru - вона там є.
Так ось. Кілька днів тому, коли я переглядав сайти, забрів на блог, на якому був опублікований скрипт, що дозволяє зберігати резервну копію сайту на Яндекс диск. У цій статті я детально розповім про нього.
Спочатку треба змінити адресу mysql сервера. У більшості випадків це localhost, тому я там його і залишив, якщо ж інший, замінюємо його на свій в рядку
$ Dbhost = "localhost"; // Адреса MySQL сервера.
У рядку нижче, замінюємо "database_user" на своє значення імені користувача бази даних mysql.
"Database_name" - на назву бази даних mysql.
Замість "site_dear_hear" вставляємо свій шлях до сайту від кореня диска.
Після цього, переходимо до налаштування Яндекс диска:
Всі. Зберігаємо файл і завантажуємо на сервер.
Не рекомендую його завантажувати в кореневий каталог сайту, тому що будуть постійно звертатися до нього всякі роботи, через що Яндекс диск буде заповнюватися зайвими копіями бекапів. Краще створити папку, наприклад "a3hd7siq8a7s9xeeewwwerw-0-032-_2", щоб ніхто, крім вас і cran не знав, де він у вас.
Cran - це планувальник завдань: спеціальна програма, за допомогою якої ви можете ставити запуск скриптів за розкладом, але як ним користуватися не знаю, тому тут допомогти не зможу.
Ви, напевно, вже знаєте, що у мене п'ять сайтів. Природно, запускати їх окремо втомишся, але добре, що в тій же статті був розміщений другий скрипт, який запускає по черзі всі інші скрипти.
Якщо у вас менше п'яти сайтів, просто видаліть рядки, які мають вигляд:
Echo ""; $ Response = file_get_contents ( "http://site5.ru/beckup.php"); echo iconv ( "Windows-1251", "utf-8", $ response);
Якщо у вас сайт в зоне.РФ, вам, перед тим, як прописувати адресу, доведеться переводити в Panycode
Сподіваюся, що стаття вам була корисна.
Чекаю коментарів.
| Статті по темі: | |
|
Доповнення Adblock Plus для Mozilla Firefox: блокуємо рекламу
Adblock Plus є найпопулярнішим в світі браузерні додатком .... Доповнення Adblock Plus для Mozilla Firefox: блокуємо рекламу
AdBlock Антібаннер для Firefox- є найпопулярнішим розширенням в ... Що таке частота запиту і як її дізнатися?
Ми випустили нову книгу «Контент-маркетинг в соціальних мережах: Як ... | |




