Elección de los lectores




Articulos populares
urgencias-diagramas
Una forma común de representar un modelo de base de datos lógico es construir diagramas ER (Entidad-Relación). En este modelo, una entidad se define como un objeto discreto para el cual se almacenan elementos de datos, y una relación describe la relación entre dos objetos.
En el ejemplo del director de una agencia de viajes, hay 5 objetos principales:
Turistas
Vales
Las relaciones entre estos objetos se pueden definir en términos simples:
Cada turista puede comprar uno o varios (muchos) bonos.
Cada bono corresponde a su pago (puede haber varios pagos si el bono, por ejemplo, se vende a crédito).
Cada recorrido puede tener varias temporadas.
La entrada se vende para una temporada de una gira.
Estos objetos y relaciones se pueden representar mediante un diagrama ER, como se muestra en la Figura 2.
Arroz. 2. Diagrama ER para la aplicación de base de datos del gestor de agencias de viajes
Objetos, atributos y claves.
El modelo se desarrolla aún más definiendo atributos para cada objeto. Los atributos de un objeto son elementos de datos relacionados con un objeto específico que deben conservarse. Analizamos el diccionario de datos compilado, seleccionamos objetos y sus atributos en él y ampliamos el diccionario si es necesario. Los atributos de cada objeto del ejemplo se presentan en la Tabla 2.
Tabla 2. Objetos y atributos de la base de datos
|
Un objeto |
Turistas |
Vales |
Excursiones |
Estaciones |
Pagos |
|
Nombre |
fecha de inicio |
fecha del pago |
|||
|
Fecha final |
|||||
|
Apellido |
Información |
||||
|
Atributos |
|||||
Tenga en cuenta que faltan varios elementos. Se ha omitido la información de registro mencionada en la especificación funcional. Cómo tenerlo en cuenta, pensarás por ti mismo y finalizarás el ejemplo propuesto. Pero lo más importante es que aún faltan los atributos necesarios para conectar objetos entre sí. Estos elementos de datos no están representados en el modelo ER, ya que, de hecho, no son atributos "naturales" de los objetos. Se procesan de forma diferente y se tendrán en cuenta en el modelo de datos relacional.
El modelo relacional se caracteriza por el uso de claves y relaciones. Existe una diferencia en el contexto de una base de datos relacional entre los términos relación y relación. Una relación se trata como una tabla bidimensional desordenada con filas no relacionadas. El esquema de datos se forma entre relaciones (tablas) a través de atributos comunes, que son claves.
Hay varios tipos de claves y, a veces, difieren sólo en términos de su relación con otros atributos y relaciones. Una clave primaria identifica de forma única una fila en una relación (tabla), y cada relación puede tener sólo una clave primaria, incluso si más de un atributo es único. En algunos casos, se requiere más de un atributo para identificar filas en una relación. La colección de estos atributos se denomina clave compuesta. En otros casos, la clave principal debe crearse (generarse) especialmente. Por ejemplo, en la relación "Turistas", tiene sentido agregar un identificador de turista único (código de turista) como clave principal de esta relación para organizar las conexiones con otras relaciones de bases de datos.
Otro tipo de clave, llamada clave externa, existe sólo en términos del esquema de datos entre dos relaciones. Una clave foránea en una relación es un atributo que es la clave primaria (o parte de una clave primaria) en otra relación. Es un atributo distribuido que forma un esquema de datos entre dos relaciones en la base de datos.
Para la base de datos diseñada, ampliaremos los atributos de los objetos con campos de código como claves principales y usaremos estos códigos en las relaciones de la base de datos para hacer referencia a los objetos de la base de datos de la siguiente manera (Tabla 3).
Es demasiado pronto para considerar completo el esquema de la base de datos construida, ya que se requiere su normalización. Se utiliza un proceso conocido como normalización de bases de datos relacionales para agrupar atributos. de maneras especiales para minimizar la redundancia y la dependencia funcional.
Tabla 3. Objetos y atributos de base de datos con campos de código extendido
|
Un objeto |
Turistas |
Vales |
Excursiones |
Estaciones |
Pagos |
|
Atributos |
código turístico |
Código de viaje |
Código de temporada |
código de pago |
|
|
código turístico |
Nombre |
fecha de inicio |
fecha del pago |
||
|
Código de temporada |
Fecha final |
||||
|
Apellido |
Información |
Código de viaje |
|||
Normalización
Las dependencias funcionales ocurren cuando el valor de un atributo se puede determinar a partir del valor de otro atributo. Se dice que un atributo que puede determinarse depende funcionalmente de un atributo que es determinante. Por lo tanto, por definición, todos los atributos que no son clave (sin clave) dependerán funcionalmente de la clave principal en cada relación (ya que la clave principal identifica de forma única cada fila). Cuando un atributo de una relación no define de forma única otro atributo, sino que lo restringe a un conjunto de valores predefinidos, se denomina dependencia multivalor. Una dependencia parcial ocurre cuando un atributo de relación depende funcionalmente de un atributo de la clave compuesta. Las dependencias transitivas se observan cuando un atributo no clave depende funcionalmente de uno o más atributos no clave en una relación.
El proceso de normalización consiste en la construcción paso a paso de una base de datos en forma normal (NF).
1. La primera forma normal (1NF) es muy sencilla. Todas las tablas de bases de datos deben satisfacer un único requisito: cada celda de las tablas debe contener un valor atómico, en otras palabras, un valor almacenado dentro área temática La aplicación de base de datos no debe tener una estructura interna cuyos elementos puedan ser requeridos por la aplicación.
2. La segunda forma normal (2NF) se crea cuando se eliminan todas las dependencias parciales de las relaciones de la base de datos. Si no hay claves compuestas en la relación, entonces este nivel de normalización se logra fácilmente.
3. La tercera forma normal (3NF) de la base de datos requiere la eliminación de todas las dependencias transitivas.
4. La cuarta forma normal (4NF) se crea cuando se eliminan todas las dependencias multivaluadas.
La base de datos de nuestro ejemplo está en 1NF, ya que todos los campos de las tablas de la base de datos tienen contenido atómico. Nuestra base de datos también está en 2NF, ya que introdujimos artificialmente en cada tabla códigos únicos para cada objeto (Código de Turismo, Código de Viaje, etc.), por lo que logramos 2NF para cada una de las tablas de la base de datos y para toda la base de datos en general. Queda por abordar las formas normales tercera y cuarta.
Tenga en cuenta que sólo existen en relación con diferentes tipos de dependencias de atributos de bases de datos. Hay dependencias: es necesario cargar la base de datos NF, no hay dependencias: la base de datos ya está en NF. Pero esta última opción prácticamente nunca se encuentra en aplicaciones reales.
Entonces, ¿qué dependencias transitivas y multivaluadas están presentes en nuestro ejemplo de base de datos de un administrador de agencia de viajes?
Analicemos la actitud de los "Turistas". Consideremos las dependencias entre los atributos “Código de turista”, “Apellido”, “Nombre”, “Patronímico” y “Pasaporte” (Fig. 3). Cada turista, representado en relación por la combinación “ Nombre completo", tiene un solo pasaporte para la duración del viaje, mientras que los homónimos completos deben tener números de pasaporte diferentes. Por tanto, los atributos “Apellido - Nombre - Patronímico” y “Pasaporte” forman una clave compuesta para los turistas.

Arroz. 3. Ejemplo de dependencia transitiva
Como se puede ver en la figura, el atributo “Pasaporte” depende transitivamente de la clave “Código de Turista”. Por lo tanto, para eliminar esta dependencia transitiva, dividimos la clave compuesta de la relación y la relación misma en 2 según relaciones uno a uno. La primera relación, la dejemos con el nombre “Turistas”, incluye los atributos “Código turístico” y “Apellido”, “Nombre”, “Patronímico”. La segunda relación, llamémosla “Información sobre turistas”, está formada por los atributos “Código Turístico” y todos los restantes atributos de la relación “Turistas”: “Pasaporte”, “Teléfono”, “Ciudad”, “País”, "Índice". Estas dos nuevas relaciones ya no tienen dependencia transitiva y están en 3NF.
No hay dependencias multivalor en nuestra base de datos simplificada. Por ejemplo, supongamos que para cada turista se deben almacenar varios números de contacto (casa, trabajo, móvil, etc., lo cual es muy habitual en la práctica), y no solo uno, como en el ejemplo. Obtenemos una dependencia multivaluada de la clave: "Código de turista" y los atributos "Tipo de teléfono" y "Teléfono"; en esta situación, la clave deja de ser una clave; ¿Qué hacer? El problema también se resuelve dividiendo el esquema de relación en 2 esquemas nuevos. Uno de ellos debe representar información sobre teléfonos (la relación “Teléfonos”), y el segundo sobre los turistas (la relación “Turistas”), a quienes se contacta mediante el campo “Código de Turista”. El “Código de turista” en relación a “Turistas” será la clave principal, y en relación a “Teléfonos” será una clave externa.
modelo lógico– una representación gráfica de la estructura de la base de datos, teniendo en cuenta el modelo de datos adoptado (jerárquico, de red, relacional, etc.), independientemente de la implementación final de la base de datos y de la plataforma hardware. En otras palabras, muestra QUÉ está almacenado en la base de datos (objetos del área temática, sus atributos y relaciones entre ellos), pero no responde a la pregunta CÓMO (Fig. 1).
Descripción del área temática:
Venta al por mayorfábricaAyexistencias
Las piezas fabricadas con determinados materiales (fundidas) se suministran al almacén desde una gama determinada de proveedores (permanentes o aleatorios) de diferentes ciudades.
Los proveedores pueden ser personas jurídicas y empresarios individuales, y estos grupos se describen mediante su propio conjunto de atributos característicos; entidades legales: número y fecha de registro estatal. registro, nombre, domicilio legal, forma de propiedad; empresarios: TIN, nombre completo, póliza de seguro, número de pasaporte, fecha de nacimiento.
A la hora de realizar una entrega se tienen en cuenta la fecha, cantidad y coste, tipo de embalaje y método de entrega (transporte por carretera, transporte ferroviario, recogida), pudiendo una misma entrega incluir varios tipos de piezas.
Los proveedores se vuelven permanentes si realizan entregas por valor de más de 1.000.000 de rublos al año.
Las piezas se entregan a los talleres de la planta, teniendo en cuenta la fecha, cantidad y número de taller. Se mantiene la cantidad actual de mercancías en stock.
Arroz. 1. Modelo de base de datos lógico en notación IDEF1X
Metodología IDEF1X– uno de los enfoques para el modelado de datos basado en el concepto de “entidad-relación” ( Relación entre entidades), propuesto por Peter Chen en 1976.
|
Tabla 2.1. Elementos básicos de la notación IDEF1X |
|
|
Esencia(Entidad) |
Imagen gráfica |
|
Entidad Independiente |
Nombre Identificador único Atributos
|
|
Entidad Dependiente |
Atributos |
|
Conexión(Relación) |
Imagen gráfica |
|
Relación no identificable | |
|
Enlace de identificación | |
|
Relación de muchos a muchos | |
|
Herencia (generalización) Incompleto |
De los padres |
Independienteesencia es una entidad cuyo identificador único no se hereda de otras entidades. Representado como un rectángulo con bordes rectos.
Entidad Dependiente es una entidad cuyo identificador único incluye al menos una relación con otra entidad. Por ejemplo, una línea de documento no puede existir sin (dependiendo de) el documento en sí. Representado como un rectángulo con bordes redondeados.
La metodología IDEF1X está enfocada al diseño de modelos de bases de datos relacionales. El modelo relacional se basa en el concepto de relación normalizada (tabla). En este caso, las entidades del área temática se asignan a tablas de bases de datos (Fig. 2), que tienen las siguientes propiedades:
Arroz.  2. Tabla de base de datos relacional
2. Tabla de base de datos relacional
Llave- una columna o grupo de columnas cuyos valores identifican de forma única cada fila.
Una tabla puede tener varias claves: una primario, a través de los cuales se vinculan relaciones, mientras que otras son alternativas. Propiedades clave:
unicidad (no puede haber filas con la misma clave);
no redundancia (eliminar cualquier atributo de una clave la priva de su propiedad de unicidad).
Base de datos relacional− se trata de un conjunto de relaciones interconectadas. Las relaciones se especifican mediante claves secundarias (clave externa - FK), es decir atributos que de otro modo serían claves primarias (PK).
Las principales limitaciones de integridad del modelo relacional son:
los atributos de la clave principal no pueden tomar un valor indefinido (integridad del objeto);
las claves secundarias no pueden tomar valores que no estén entre los valores de las claves primarias de la tabla relacionada: si la relación R2 tiene entre sus atributos alguna clave foránea (FK) que corresponde a la clave primaria (PK) de la relación R1, entonces cada valor FK debe ser igual a uno de los valores PK.
|
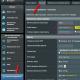
Para crear un modelo de base de datos lógica en Visio2013, seleccione la categoría de plantilla "Programas y bases de datos" y en ella la plantilla "Diagrama de modelo de base de datos" (Fig. 2.3) |
Arroz. 2.3. Plantilla de esquema de modelo de base de datos |
|
Antes de comenzar a crear un modelo lógico, vaya a la pestaña "Base de datos" y en "Mostrar parámetros" establezca las siguientes configuraciones (Fig. 2.4-2.6). |
Arroz. 2.4.Parámetros del documento (pestaña General) |
|
Arroz. 2.6.Parámetros del documento (pestaña Relación) |
Arroz. 2.5.Parámetros del documento (pestaña Tabla) |
|
Para crear una Entidad “Parte”, arrastre el estereotipo de Entidad desde la barra de herramientas a la pantalla (Figura 2.7). |
Arroz. 2.7.Creación de la Entidad |
|
Establezca el nombre de la Entidad en las propiedades en la parte inferior de la pantalla (Fig. 2.8). |
Arroz. 2.8.Propiedades de la Entidad (“Definición”) |
|
Luego, en la pestaña Columnas, cree atributos de entidad, verifique el identificador único (clave principal) en la columna PK y haga clic en Aceptar (Figura 2.9). |
Arroz. 2.9.Propiedades de la entidad (“Columnas”) |
|
De manera similar, cree una segunda entidad, por ejemplo "Material". Para crear una conexión entre ellos, arrastre el estereotipo "Relación" con un punto a la imagen de la clase "Parte", porque De cada material se fabrican cero, una o más piezas. Luego arrastre el segundo extremo de la conexión a la imagen de clase "Material" (Fig. 2.10). La clave externa “Código de material (FK)” aparecerá automáticamente como parte de los atributos de la entidad “Parte”. Un diamante abierto en el lado del Material significa que es posible que el material no esté especificado. Para eliminar el diamante, abra las propiedades de la entidad "Parte" y marque este atributo en la columna "Obligatorio". |
Arroz. 2.10.Propiedades de relación (“Definición”) |
Ejercicio : construya un modelo de base de datos lógico de acuerdo con la descripción del área temática de su opción de tarea.
Para representar el conocimiento matemático en lógica matemática, se utilizan formalismos lógicos: cálculo proposicional y cálculo de predicados. Estos formalismos tienen una semántica formal clara y se han desarrollado mecanismos de inferencia para ellos. Por lo tanto, el cálculo de predicados fue el primer lenguaje lógico que se utilizó para describir formalmente áreas temáticas relacionadas con la resolución de problemas aplicados.
Modelos lógicos Las representaciones del conocimiento se implementan utilizando la lógica de predicados.
Predicado es una función que toma dos valores (verdadero o falso) y está diseñada para expresar las propiedades de los objetos o las relaciones entre ellos. Una expresión que afirma o niega la presencia de cualquier propiedad en un objeto se llama declaración. Constantes sirven para nombrar objetos del área temática. Se forman oraciones o afirmaciones lógicas. fórmulas atómicas. Interpretación de predicados es el conjunto de todas las vinculaciones válidas de variables a constantes. La vinculación es la sustitución de constantes en lugar de variables. Un predicado se considera generalmente válido si es verdadero en todas las interpretaciones posibles. Se dice que un enunciado se sigue lógicamente de unas premisas dadas si es verdadero siempre que las premisas lo sean.
Las descripciones de áreas temáticas realizadas en lenguajes lógicos se denominan modelos lógicos .
DAR (MIKHAIL, VLADIMIR, LIBRO);
($x) (ELEMENTO (x, EVENTO-DAR) ? FUENTE (x, MICHAEL) ? DESTINO? (x, VLADIMIR) OBJETO (x, LIBRO).
Aquí se describen dos formas de registrar un hecho: "Mikhail le dio el libro a Vladimir".
La inferencia lógica se lleva a cabo mediante un silogismo (si B se sigue de A y C se sigue de B, entonces C se sigue de A).
En general, los modelos lógicos se basan en el concepto teoría formal, dado por los cuatro:
S=
donde B es un conjunto contable caracteres básicos (alfabeto) teorías S;
F - subconjunto expresiones de la teoría S, llamado fórmulas teóricas(las expresiones se entienden como secuencias finitas de símbolos básicos de la teoría S);
A es un conjunto seleccionado de fórmulas llamado axiomas de la teoría S, es decir, un conjunto de fórmulas a priori;
R - un conjunto finito de relaciones (r 1, ..., r n) entre fórmulas, llamado reglas de inferencia.
La ventaja de los modelos lógicos de representación del conocimiento es la capacidad de programar directamente el mecanismo para generar declaraciones sintácticamente correctas. Un ejemplo de tal mecanismo es, en particular, el procedimiento de inferencia basado en el método de resolución.
Mostremos el método de resolución.
El método utiliza varios conceptos y teoremas.
Concepto tautologías, una fórmula lógica cuyo valor será “verdadero” para cualquier valor de los átomos incluidos en ellas. ¿Denotado por?, leído como “generalmente válido” o “siempre cierto”.
Teorema 1. A?B si y sólo si?A B.
Teorema 2. A1, A2, ..., An? ¿En si y sólo si cuando? (A1?A2?A3?…?An) V.
¿Símbolo? leerse como “es cierto que” o “puede deducirse”.
El método se basa en la demostración de una tautología.
? (X? A)?(Y? ? A)?(X? Y) .
Los teoremas 1 y 2 nos permiten escribir esta regla de la siguiente forma:
(X? A), (Y? ? A) ? (X? Y),
lo que da fundamento para afirmar: es posible deducirlo de las premisas.
En el proceso de inferencia utilizando la regla de resolución, se realizan los siguientes pasos.
1. Se eliminan las operaciones de equivalencia e implicación:
2. La operación de negación se mueve dentro de las fórmulas utilizando las leyes de De Morgan:
![]()
3. Las fórmulas lógicas se reducen a forma disyuntiva: .
La regla de resolución contiene una conjunción de disyunciones en el lado izquierdo, por lo tanto, llevar las premisas utilizadas para la prueba a una forma que represente una conjunción de disyunciones es un paso necesario en casi cualquier algoritmo que implemente la inferencia lógica basada en el método de resolución. El método de resolución es fácil de programar; esta es una de sus ventajas más importantes.
Supongamos que necesitamos demostrar que si las relaciones y son verdaderas, entonces podemos derivar la fórmula. Para ello es necesario seguir los siguientes pasos.
1. Llevar premisas a forma disyuntiva:
, , .
2.Construcción de la negación de la conclusión deducida. La conjunción resultante es válida cuando y son verdaderas.
3.Aplicación de la regla de resolución:
(contradicción o “disyunción vacía”).
Entonces, asumiendo la falsedad de la conclusión deducida, obtenemos una contradicción, por lo tanto, la conclusión deducida es verdadera, es decir , es deducible de las premisas iniciales.
Fue la regla de resolución la que sirvió de base para la creación del lenguaje. programación lógica PRÓLOGO. De hecho, el intérprete de lenguaje PROLOG implementa de forma independiente un resultado similar al descrito anteriormente, generando una respuesta a la pregunta del usuario dirigida a la base de conocimiento.
En lógica de predicados, para aplicar la regla de resolución es necesario realizar una unificación más compleja de fórmulas lógicas para reducirlas a un sistema de disyunciones. Esto se debe a la presencia elementos adicionales sintaxis, principalmente cuantificadores, variables, predicados y funciones.
El algoritmo para unificar fórmulas lógicas de predicados incluye los siguientes pasos.
Después de completar todos los pasos del algoritmo de unificación descrito, puede aplicar la regla de resolución. Normalmente, esto implica negar la conclusión que se extrae, y el algoritmo de derivación se puede describir brevemente de la siguiente manera: Si se dan varios axiomas (teoría TH) y un. Se debe llegar a una conclusión sobre si una determinada fórmula es derivable. R a partir de los axiomas de la teoría Th, se construye la negación R y se agrega a Th, dando como resultado una nueva teoría Th1. Después de reducir los axiomas de la teoría a un sistema de disyunciones, se puede construir una conjunción y axiomas de la teoría Th. Al mismo tiempo, es posible derivar disyunciones -consecuencias- de las disyunciones iniciales. Si R es deducible de los axiomas de la teoría Th, entonces en el proceso de derivación se puede obtener una determinada cláusula Q, que consta de una letra y la cláusula opuesta. Esta contradicción indica que R deducible de los axiomas Th. En general, existen muchas estrategias de prueba; hemos considerado sólo una de las posibles: la de arriba hacia abajo.
Ejemplo: imaginemos el siguiente texto usando lógica de predicados:
"Si un estudiante sabe programar bien, puede convertirse en un especialista en el campo de la informática aplicada".
"Si un estudiante obtiene buenos resultados en el examen de sistemas de información, entonces sabe programar bien".
Representemos este texto usando lógica de predicados de primer orden. Introduzcamos la siguiente notación: X- variable para designar al estudiante; Bien- constante correspondiente al nivel de calificación; R(X)- un predicado que expresa la posibilidad del sujeto X convertirse en un especialista en informática aplicada; q(X, está bien)- un predicado que denota la habilidad del sujeto X programa con evaluación Bien; R(X, está bien)- predicado que especifica la conexión del estudiante X con nota de examen en sistemas de información.
Ahora construyamos un conjunto de fórmulas construidas correctamente:
Q(X, bien).
R(X, bien)q(X, bien).
Complementemos la teoría resultante con un hecho específico.
R(Ivanov, bien).
Realicemos una inferencia usando la regla de resolución para determinar si la fórmula es R(Ivánov) una consecuencia de la teoría anterior. En otras palabras, ¿se puede deducir de esta teoría que el estudiante Ivanov se convertirá en un especialista en informática aplicada si aprueba bien el examen de sistemas de información?
Prueba
1. Transformemos las fórmulas originales de la teoría para llevarlas a forma disyuntiva:
(X, bueno) P(X);
(X, bueno) (X, bueno);
R(Ivánov, Bien).
2. Añadir a los axiomas existentes la negación de la conclusión que se extrae.
(Ivánov).
3. Construyamos una conjunción de disyunciones.
(X, bueno) R(X)? ? PAG(Ivanov, bien)? ? q(Ivanov, bien), reemplazando una variable X a una constante Ivánov.
El resultado de aplicar la regla de resolución se llama disolvente. En este caso, el resolutivo es (Ivánov).
4. Construya una conjunción de cláusulas utilizando el resolutivo obtenido en el paso 3:
(X, bien) (X, bien) (Ivanov, bien) (Ivanov, bien).
5. Escribamos la conjunción del resolutivo resultante con la última disyuntiva de la teoría:
(Ivanov, bien) (Ivanov, bien)(contradicción).
Por lo tanto, el hecho R(Ivánov) deducido de los axiomas de esta teoría.
Para determinar el orden de aplicación de los axiomas en el proceso de inferencia existen las siguientes reglas heurísticas:
Sin embargo, utilizando las reglas que definen la sintaxis de una lengua, es imposible establecer la verdad o falsedad de una determinada afirmación. Esto se aplica a todos los idiomas. Una declaración puede construirse sintácticamente correctamente, pero resultar completamente carente de significado. Un alto grado de uniformidad también conlleva otra desventaja. modelos lógicos- la dificultad de utilizar heurísticas que reflejen las características específicas de un problema temático en particular al realizar la prueba. Otras desventajas de los sistemas formales incluyen su monotonía, la falta de medios para estructurar los elementos utilizados y la inadmisibilidad de las contradicciones. Un mayor desarrollo de las bases de conocimiento siguió el camino del trabajo en el campo de la lógica inductiva, la lógica del "sentido común", la lógica de la fe y otros esquemas lógicos que tienen poco en común con la lógica matemática clásica.
La calidad de la base de datos desarrollada depende enteramente de la calidad de las etapas individuales de su diseño. El desarrollo de alta calidad de un modelo de datos lógico es de gran importancia ya que, por un lado, garantiza la idoneidad de la base de datos del área temática y, por otro lado, determina la estructura de la base de datos física y, en consecuencia, sus características operativas.
Los mismos datos se pueden agrupar en tablas de relaciones. diferentes caminos, es decir. es posible organizar varios conjuntos de relaciones entre objetos de información interconectados del área temática. La agrupación de atributos en las relaciones debe ser racional, minimizando la duplicación de datos y simplificando los procedimientos para su procesamiento y actualización.
Un conjunto particular de relaciones tiene mejores propiedades para la inclusión, modificación y eliminación de datos si cumple con requisitos específicos de normalización de relaciones.
Normalización de las relaciones– un aparato formal de restricciones a su formación, que permite eliminar la duplicación de datos, garantizar su coherencia y reducir el coste de mantenimiento de la base de datos.
En la práctica, los conceptos de primera, segunda y tercera forma normal se utilizan con mayor frecuencia.
La relación se llama normalizado o reducido a la primera forma normal(1NF), si todos sus atributos son simples o atómicos (en adelante indivisibles). Una relación en primera forma normal tendrá las siguientes propiedades:
■ no hay tuplas idénticas en la relación;
■ las tuplas no están ordenadas;
■ los atributos no están ordenados y difieren por nombre;
■ todos los valores de los atributos son atómicos.
Como puede verse en las propiedades enumeradas, cualquier relación se encuentra automáticamente en la primera forma normal.
Se muestra fácilmente que la primera forma normal permite el almacenamiento en una relación de información heterogénea, la redundancia de datos, lo que conduce a la insuficiencia del modelo lógico de datos del área temática. Por tanto, la primera forma normal no es suficiente para un modelado de datos adecuado.
Para considerar la cuestión de reducir las relaciones a la segunda forma normal, es necesario explicar el concepto de dependencia funcional.
Que haya una relación r. El conjunto de atributos Y depende funcionalmente del conjunto de atributos X, si por cualquier estado de relación R para cualquier tupla de lo que sigue, es decir en todas las tuplas que tienen mismos valores atributos X, los valores de los atributos Y también coinciden en cualquier estado de la relación r.
Muchos atributos X llamado determinante de la dependencia funcional, y el conjunto de atributos U – parte dependiente.
En la práctica, estas dependencias reflejan las relaciones encontradas entre los objetos del dominio y son restricciones adicionales definidas por el dominio. Por tanto, la dependencia funcional es un concepto semántico. Ocurre cuando los valores de algunos datos en el área temática se pueden utilizar para determinar los valores de otros datos. Por ejemplo, al conocer el número de personal de un empleado, puede determinar su apellido. Una dependencia funcional impone restricciones adicionales a los datos que se pueden almacenar en una relación. Para que la base de datos sea correcta, es necesario verificar todas las restricciones definidas por las dependencias funcionales al realizar operaciones de modificación de la base de datos.
La dependencia funcional de los atributos de relación recuerda el concepto de dependencia en matemáticas. La dependencia funcional en matemáticas es un triple de los objetos X, Y Y F, donde X es un conjunto que representa el dominio de definición de la función, Y– un conjunto de valores, y F– una regla según la cual cada elemento está asociado con un solo elemento. Por el contrario, en las relaciones, el valor de un atributo dependiente puede tomar diferentes valores impredecibles en diferentes estados de la base de datos, correspondientes a diferentes estados de la base de datos. área temática. Por ejemplo, un empleado que cambia su apellido al contraer matrimonio legal conducirá al hecho de que con el mismo valor del determinante, digamos un número de personal, el valor del argumento dependiente será diferente.
La dependencia funcional de los atributos establece únicamente que para cada estado específico de la base de datos, el valor de un atributo se puede utilizar para determinar inequívocamente el valor de otro atributo. Los valores específicos de la parte dependiente pueden ser diferentes en diferentes estados de la base de datos.
La relación está en segunda forma normal(2NF) si está en primera forma normal (1NF) y no hay atributos que no sean clave que dependan de parte de la clave compuesta.
De la definición de 2NF se deduce que si la clave candidata es simple, entonces la relación está automáticamente en segunda forma normal.
Sin embargo, las relaciones reducidas a la segunda forma normal todavía contienen información heterogénea y requieren escritura adicional. código de programa en forma de desencadenantes para el correcto funcionamiento de la base de datos. El siguiente paso para mejorar la calidad de las relaciones es llevarlas a la tercera forma normal.
La relación está en tercera forma normal(ZNF), si está en 2NF y todos los atributos no clave son mutuamente independientes.
Un modelo de datos relacional, que consta de relaciones reducidas a 3NF, es adecuado para el modelo de dominio y requiere sólo aquellos desencadenantes que admitan integridad referencial. Estos desencadenantes son estándar y requieren poco esfuerzo para desarrollarse.
Por lo tanto, el desarrollo de un modelo lógico de una base de datos relacional se puede representar como la definición de relaciones que reflejan los conceptos del área temática y los llevan a la tercera forma normal.
El algoritmo de desarrollo incluye tres etapas.
Etapa I. Reducción a 1NF. Aquí es necesario definir y definir relaciones que reflejen los conceptos del área temática. Todas las relaciones están automáticamente en 1NF.
Etapa II. Reducción a 2NF. Si en algunas relaciones se detecta una dependencia de los atributos de una parte de una clave compleja, entonces deben descomponerse de la siguiente manera: los atributos que dependen de una parte de una clave compleja se colocan en una relación separada junto con esta parte de la clave, y todos los atributos clave permanecen en la relación original.
![]() . La clave es una clave compleja.
. La clave es una clave compleja.
– dependencia de todos los atributos de la clave de relación;
– dependencia de algunos atributos de parte de una clave compleja.
– la parte restante de la relación original;
- nueva actitud.
Etapa III. Reducción a 3NF. Si en algunas relaciones se detecta una dependencia de algunos atributos no clave de otros atributos no clave, entonces se lleva a cabo una descomposición de estas relaciones: atributos no clave que dependen de otros atributos no clave,
formar una relación separada. En la nueva relación, la clave pasa a ser el determinante de la dependencia funcional.
Sea, por ejemplo, la relación inicial –. A- llave.
Entonces las dependencias funcionales tienen la siguiente forma:

Después de descomponer la relación obtenemos:
En la práctica, es bastante raro que se desarrolle un modelo de base de datos lógico utilizando el algoritmo dado. más utilizado varias opciones Diagramas ER respaldados por herramientas CASE adecuadas. Los conceptos básicos de los diagramas ER se establecen en los estándares IDEF1 e IDEF1X. Sin embargo, el algoritmo anterior es útil como ilustración de los problemas que pueden surgir al definir relaciones débilmente normalizadas en las primeras etapas del diseño. Comprender estos problemas es especialmente importante a la hora de realizar modificaciones y mejoras en la base de datos, cuando se introducen nuevas entidades, aparecen nuevas dependencias, etc.
Desarrollo sistemas de información(IS) se trata de crear herramientas de gestión de la información. Los SI reciben información, la procesan de acuerdo con ciertas reglas y entregan el resultado a los consumidores: para imprimir, en una pantalla, en auriculares y transmitir a otros sistemas.
Por lo tanto, para crear un IP de alta calidad, no basta con comprender los procesos comerciales y las necesidades del Cliente. Es importante comprender qué información debe gestionar el sistema. Y para ello es necesario saber qué objetos entran en el área temática del IS diseñado y qué conexiones lógicas existen entre ellos. Para formar tal comprensión, se utilizan modelos lógicos del área temática.
El propósito de construir un modelo lógico es obtener representación grafica estructura lógica del área temática en estudio.
Un modelo lógico de dominio ilustra las entidades y sus relaciones entre sí.
Las entidades describen los objetos que son objeto de la actividad del área temática y los sujetos que realizan actividades dentro del área temática. Las propiedades de objetos y sujetos en el mundo real se describen mediante atributos.
Las relaciones entre entidades se ilustran mediante conexiones. Las reglas y restricciones de las relaciones se describen mediante propiedades de relación. Normalmente, las relaciones definen dependencias entre entidades o la influencia de una entidad sobre otra.
Ejemplo: pedir una pizza
El cliente realiza un pedido de compra de pizza. En general, un cliente puede pedir diferentes cantidades de distintos tipos de pizza. Por tanto, cada pedido incluye artículos. Cada posición indica el tipo de pizza que el cliente quiere recibir, así como su cantidad.

1. El modelo lógico debe mostrar todas las entidades y relaciones que sean importantes para el propósito para el que lo dibujamos.
2. Todos los objetos del modelo (tanto entidades como relaciones) deben tener nombre. La denominación de entidades y relaciones debe hacerse en términos del área temática.
3. Para conexiones se debe indicar la multiplicidad (uno - muchos).
4. Se debe indicar la dirección de lectura para cada conexión.
Ejemplo: se han añadido al modelo los nombres de las conexiones, sus dimensiones y dirección de lectura.

5. Como mínimo, se deben especificar atributos básicos para las entidades.
Ejemplo: se especifican atributos básicos para entidades

<Сущность 1> — <отношение / влияние> — <Сущность 2>.
Leyendo un ejemplo discutido anteriormente: Un cliente realiza un pedido. El pedido incluye posiciones, cada una de las cuales indica qué tipo de pizza y en qué cantidad desea recibir el cliente.
El cliente puede existir sin orden. Sin embargo, no se puede registrar un pedido sin la indicación del cliente. Un cliente puede realizar un número ilimitado de pedidos.
Según el modelo, un pedido puede tener un número infinito de artículos. Es necesario aclarar hasta qué punto esto es correcto.
2. El modelo debe estar estructurado, las entidades deben agruparse según su significado lógico.
3. Es muy recomendable evitar cruces de conexiones.
4. La disposición de los objetos modelo debe ser tal que sea conveniente para su lectura.
Hay una observación: si el modelo es agradable a la vista, lo más probable es que esté fabricado con alta calidad.
Sin respuestas a estas preguntas, desarrollar un modelo pierde todo sentido, ya que estaremos haciendo algo de lo que no esperamos nada en particular. El resultado será correspondiente.
Las respuestas a estas preguntas nos dan los requisitos para el modelo y durante el desarrollo nos permitirán tomar decisiones sobre su desarrollo y juzgar su calidad.
Como regla general, la respuesta a esta pregunta surge de la comprensión de la tarea que enfrenta el analista de negocios.
En la mayoría de los casos, los límites del modelado están determinados por los procesos de negocio en estudio o por un fragmento del espacio de información de la empresa que se incluye en el problema que se está resolviendo.
Desarrollar un modelo lógico es un proceso iterativo. Debe perfeccionarse y detallarse constantemente a medida que se desarrollan el área temática y la tarea en cuestión.
El modelo lógico debe construirse de tal manera que las entidades se llamen sustantivos, las conexiones se llamen verbos, y la lectura del diagrama generaría, aunque de manera torpe, oraciones que describan lo que está sucediendo en el área temática. Si esto se lograba, entonces el modelo salía maravilloso. Si esto no fuera posible, entonces el desarrollador del modelo todavía tiene trabajo por hacer.
Es importante recordar que un modelo lógico no se trata de la estructura de la base de datos, sino de la estructura lógica del área temática de su tarea. Al excluirlo de los atributos que se están desarrollando, se priva de una herramienta eficaz de análisis y diseño que le permite tener en cuenta con mucha precisión aspectos del negocio que no están ilustrados por modelos dinámicos.
Y viceversa: el uso oportuno y competente de un modelo lógico lo convierte en una herramienta muy poderosa en manos de un analista de negocios o de sistemas.
 Serguéi Kalinov
Serguéi Kalinov
Analista de Negocios Líder
| Artículos relacionados: | |
|
Revisión de Xiaomi Mi6: rendimiento potente con cámara dual
Los teléfonos inteligentes Xiaomi se pueden ver cada vez más en manos de la gente común, pero... Cómo eliminar completamente Avast Utility para eliminar Avast de su computadora
El antivirus es fácil de instalar, pero difícil de eliminar, y este artículo le dirá... Diagrama de circuito de fuente de alimentación de 12 V DIY de fuente de alimentación simple
Todos sabemos que las fuentes de alimentación hoy en día son una parte integral... | |