Elección de los lectores





articulos populares
En artículos anteriores, hemos mencionado repetidamente un fenómeno como un bloque malo (malo o malo), pero hasta ahora no hemos dado una definición exacta de qué es, cuáles son las razones de su aparición, cómo tratarlos y si es necesario. En este artículo, abordaremos las dos primeras preguntas y le daremos algo de tiempo para su propia reflexión y búsqueda de soluciones. La próxima vez hablaremos sobre cómo tratar con ellos.
Entonces, un bloque defectuoso generalmente se entiende como una sección específica del disco, trabajo normal lo cual no está garantizado o es imposible en absoluto. Tales áreas pueden contener información variada, pueden ser datos de usuario o información de servicio (también llamado servo (obviamente del latín servire o inglés serve - serve), en este caso está plagado de consecuencias, cuya gravedad varía en un rango muy amplio), aunque, por supuesto , la mejor opción faltaría algo en esta área (aunque probablemente no tendrá que lidiar con los males en tales áreas). La aparición de dichos sectores puede deberse a varias razones, en un caso dichos sectores pueden restaurarse, en el otro es imposible, en uno es necesario utilizar algunos métodos de tratamiento y reasignación en otro. Pero primero, disipemos algunos mitos bastante comunes.
Mito uno: no hay nada malo en los discos duros modernos. No es cierto, sucede. En general, la tecnología es la misma que hace años, solo mejorada y refinada, pero aún no es ideal (sin embargo, es poco probable que se cree una ideal sobre la base de tecnologías de grabación magnética).
Mito dos: para los discos duros equipados con SMART, esto no es relevante (léase, no puede haber problemas). Tampoco tan: relevante, nada menos que para los discos duros sin SMART (si es que aún existen). El concepto de un sector defectuoso es cercano y querido para ella, debería haber quedado claro en las publicaciones relevantes dedicadas a esta tecnología (enlaces al final). Lo único es que SMART se ha hecho cargo de la mayoría de las preocupaciones sobre dichos sectores que antes se asignaban al usuario. Y a menudo puede suceder que el usuario no sepa nada en absoluto y no se entere de los daños que se producen en su tornillo, a menos, por supuesto, que la situación no sea patológica. Escuché de los usuarios que así es como los vendedores a veces justifican su negativa a garantizar el intercambio de discos duros, en los que "aparecen" los defectos. El vendedor, por supuesto, está equivocado. SMART no es omnipotente, y nadie ha cancelado los males todavía.
Para comprender los males y sus variedades, profundicemos un poco en el método de almacenamiento de información en el disco duro. Aclaremos dos puntos.
1. La unidad en la que el disco duro funciona a bajo nivel es el sector. En el espacio físico en el disco correspondiente al sector, no solo se registran directamente los datos, sino también la información del servicio: campos de identificación y una suma de verificación para ellos, datos y un código de control para ellos, un código de recuperación de errores, etc. (no estandarizado y depende del fabricante y modelos). Según la presencia de campos de identificación, se distinguen dos tipos de registros: con y sin campos de identificación. El primero es viejo y ha perdido terreno a favor del segundo. Más tarde quedará claro por qué estoy celebrando esto. También es importante que existan medios de control de errores (que, como veremos, pueden convertirse en sus fuentes).
2. Cuando se trabajaba con discos duros antiguos, era necesario escribir en el BIOS sus parámetros físicos, que se indicaban en la etiqueta, y para direccionar de manera única un bloque de datos, era necesario indicar el número de cilindro, número de sector en la pista, número de cabeza. Tal trabajo con el disco dependía completamente de sus parámetros físicos. No fue conveniente y ató las manos de los desarrolladores en muchos asuntos. Se requería una salida y se encontró en la traducción de direcciones. El que nos interesa: se decidió abordar los datos en la unidad con un parámetro y asignar la función de determinar la dirección física real correspondiente a este parámetro a controlador duro disco. Esto le dio al terubema libertad y compatibilidad.
Los datos físicos reales de la unidad resultaron no ser importantes. Solo es importante que la cantidad de bloques lógicos especificados por el BIOS no exceda la cantidad real. La creación de dicho traductor también es de gran importancia para los problemas de los sectores defectuosos. Y es por eso. Manejo de sectores defectuosos de antaño unidades de disco duro no fue perfecto, llevado a cabo por medio sistema de archivos. El disco se entregó con una pegatina en la que se indicaban las direcciones de los bloques defectuosos encontrados por el fabricante. El propio usuario ingresó manualmente estos datos en FAT y, por lo tanto, excluyó el acceso a ellos por parte del sistema operativo.
La tecnología de fabricación de planchas era imperfecta entonces e imperfecta ahora. No existen métodos para crear una superficie ideal que no contenga un solo bloque defectuoso, contrariamente a la opinión común de que un disco duro se envía de fábrica sin ellos. Con el crecimiento del volumen de discos, la cantidad de sectores defectuosos crecía al salir de fábrica, y, es claro que solo hasta cierto punto el procedimiento para registrarlos en FAT se podía realizar manualmente, era necesario encontrar un forma de marcar los errores, aunque no se sabe qué sistema de archivos se utilizará. La invención del traductor hizo posible resolver estos problemas. Se asignó un área protegida especial en el disco duro, donde se escribió un traductor, en el que se estableció una correspondencia entre cada bloque lógico de una cadena continua y una dirección física real.
Si de repente se encontraba un bloque defectuoso en la superficie, simplemente se omitía y la dirección del siguiente bloque físico disponible se asignaba a este bloque lógico. El traductor se leyó del disco cuando se encendió. Su creación fue (y es) realizada en fábrica, y es precisamente por eso, y no porque el fabricante utilice algún tipo de súper tecnología, que los nuevos discos no parecen contener bloques defectuosos. Los parámetros físicos estaban ocultos (y variaban demasiado, ya que las firmas tenían carta blanca en la producción de sus propios formatos de bajo nivel, y al usuario no le importaba), los defectos se marcaban en fábrica, la versatilidad aumentaba. Bueno como en un cuento de hadas.
Ahora volvamos a los males y sus variedades. Dependiendo de la naturaleza del origen de todos ellos, se pueden dividir en dos grandes grupos: lógicos y físicos.
Los defectos superficiales pueden estar asociados al desgaste gradual del revestimiento magnético de los discos, las partículas de polvo más pequeñas que se filtraban a través del filtro, cuya energía cinética, acelerada en el interior del accionamiento a velocidades colosales, resulta ser suficiente para dañar la superficie. de los discos (sin embargo, lo más probable es que se desprendan del disco bajo la acción de las fuerzas centrífugas y el filtro interno los retrase, pero es posible que tengan tiempo de estropearse), el resultado del daño mecánico por el impacto, en el que Se pueden eliminar pequeñas partículas de la superficie, que luego, a su vez, también eliminarán otras partículas, y el proceso irá como una avalancha (tales partículas también rodarán de las placas bajo la acción de las fuerzas centrífugas, pero mucho más tiempo y más pesados, ya que serán sostenidos por fuerzas magnéticas. Esto todavía está plagado del hecho de que chocarán con la cabeza que se cierne a una altura muy baja, lo que hará que se caliente y degrade el rendimiento: se producirá una distorsión. señalo, el resultado son errores de lectura), he oído (no tengo tales estadísticas) que fumar en una computadora puede hacer lo mismo, ya que los alquitranes de tabaco pueden penetrar en el filtro de aire del disco duro (que tiene uno), lo que lleva a pegar allí las cabezas a las placas (daños en la superficie y las cabezas), simplemente asentarse en la superficie y, por lo tanto, cambiar el rendimiento, etc.
Dichos sectores resultan inadecuados para la circulación y deben ser excluidos de la circulación. Su restauración no es posible ni en casa ni en condiciones centros de servicio. Será bueno si uno de ellos logra al menos recuperar la información. La velocidad del proceso de este tipo de destrucción superficial es individual. Si el número de males no crece o crece muy poco, entonces no puedes tener miedo serio (aunque hacer respaldo todavía vale la pena) si el crecimiento es rápido, entonces el disco tendrá que ser reemplazado y, además, a toda prisa. Con este tipo de bads, puede reasignar bloques a una superficie de respaldo: tiene sentido en ausencia de progresión. Pero esto no se trata de ahora. Si para hablar de área de los datos. Como ya se señaló, la información de servicio también se almacena en las placas. En el proceso de uso, también puede ser destruido. Esto puede ser mucho más doloroso que una interfaz de usuario normal.
El hecho es que la información del servo se usa activamente en el proceso de trabajo: las marcas del servo estabilizan la velocidad de rotación del disco, sostienen la cabeza sobre un cilindro dado, independientemente de las influencias externas. Las interrupciones menores en la información del servo pueden pasar desapercibidas. Un daño severo al formato del servo puede hacer que una parte del disco o todo el disco sean inaccesibles. Dado que el programa de accionamiento utiliza la información del servo y es fundamental para garantizar el funcionamiento normal y, en general, debido a sus especificaciones, las cosas son mucho más complicadas con él. Algunos discos duros le permiten desactivar las pistas de servo que fallan. Restaurarlos solo es posible en la fábrica utilizando equipos especiales costosos y complejos (estimaremos aproximadamente los costos de dicha reparación de un disco duro sin garantía y comprenderemos que sería correcto llamar a este tipo de fallas incorregibles).
Los males físicos también pueden incluir malos sectores, cuya aparición se debe a un mal funcionamiento de la parte electrónica o mecánica de la unidad, por ejemplo, cabezas rotas, daños mecánicos graves como resultado del impacto: atasco de la bobina o los discos del posicionador, desplazamiento de los discos. Las acciones aquí pueden ser diferentes y dependen de la situación específica, si, por ejemplo, se rompe la cabeza (estos males aparecen porque se intenta acceder a una superficie a la que no se puede acceder) (lo que no significa en absoluto que algo esté mal con superficie)), entonces, por ejemplo, a menudo se puede apagar (o se puede cambiar en las condiciones de los centros de servicio especializados, pero el costo de la operación lo hace pensar seriamente en su conveniencia (en la mayoría de los casos, la respuesta es negativa) ), a menos que, por supuesto, estemos hablando de la necesidad de restaurar información extremadamente valiosa (pero esa es otra conversación)).
En general, este tipo de daño se caracteriza por un carácter catastrófico. Aquellos. como podemos ver, los males físicos no son tratados, solo es posible algún tipo de "mitigación" de su presencia. Con sectores defectuosos lógicos, la situación es más simple. Algunos de ellos son curables. En la mayoría de los casos, debido a errores de registro. Se pueden distinguir las siguientes categorías:
1. El caso más simple: errores del sistema de archivos. El sector está marcado en FAT como malo, pero en realidad no lo es. Anteriormente, algunos virus usaban esta técnica cuando en un pequeño volumen de un disco duro era necesario encontrar un lugar apartado al que no se podía acceder por medios simples. Ahora bien, esta técnica no es relevante, ya que no es difícil esconder un par de megas (o incluso un par de decenas de megas) en las entrañas de Windows. Además, alguien podría gastarle una broma a un usuario desafortunado (existían tales programas). Y, en general, el sistema de archivos es algo frágil, se trata con mucha facilidad y absolutamente sin consecuencias.
2. Defectos lógicos irrecuperables: típicos de discos duros antiguos que utilizan un registro con campos de identificación. Si tiene un disco de este tipo, es posible que los encuentre. Debido al formato incorrecto de la dirección física registrada para este sector, un error de suma de verificación para el mismo, etc. En consecuencia, es imposible dirigirse a él. De hecho, son recuperables, pero en fábrica. Como ya he dicho que ahora se utiliza la tecnología de registro sin campos identificadores, esta variedad puede considerarse irrelevante.
3. Defectos lógicos subsanables. No es tan raro, especialmente en algunos tipos de unidades, el tipo de bloques defectuosos. El origen se debe principalmente a errores de escritura en disco. La lectura de dicho sector falla, ya que el código ECC que contiene generalmente no coincide con los datos, y la escritura suele ser imposible, ya que el espacio que se va a escribir se verifica previamente antes de escribir, y dado que ya se han encontrado problemas con él, escribir a esta zona es rechazada. Aquellos. resulta que el bloque no se puede utilizar, aunque físicamente la superficie que ocupa está en perfecto orden. Los defectos de este tipo a veces pueden ser causados por errores en el firmware del disco duro, pueden ser provocados software o razones técnicas (por ejemplo, un corte de energía y su fluctuación, el cabezal moviéndose a una altura inaceptable durante la grabación, etc.). Pero si es posible hacer coincidir el contenido del sector y su código ECC, dichos bloques pasan sin dejar rastro. Además, este procedimiento no es complicado, y los medios para su implementación están ampliamente disponibles y, en general, son inocuos.
4. La aparición de bloques defectuosos de este tipo en los discos duros se debe a las peculiaridades de la tecnología de producción: nunca hay dos dispositivos absolutamente idénticos, algunos de sus parámetros seguramente serán diferentes. Al preparar los discos duros en la fábrica, se determina un conjunto de parámetros para cada uno que asegura el mejor funcionamiento de esta instancia en particular, los llamados adaptativos. Estos parámetros se guardan, y si de alguna manera resultan dañados misteriosamente, el resultado puede ser una inoperancia total del disco, su funcionamiento inestable o una gran cantidad de sectores defectuosos que aparecen y desaparecen en un lugar u otro. En casa, no se puede hacer nada al respecto, pero todo se puede configurar en la fábrica o en un centro de servicio.
Como puede ver, en casa solo se tratan dos tipos de bloques lógicos defectuosos. Otros, si es necesario, puede intentar reemplazarlos con una copia de seguridad, pero no curarlos. Nada se puede hacer con las terceras casas. Hablaremos sobre cómo y qué hacer en los dos primeros casos la próxima vez.
Continuará
Winchester es uno de los dispositivos menos confiables en una computadora. De hecho, además de la electrónica compleja, contiene partes mecánicas que funcionan continuamente. Con el tiempo se desgastan y comienzan varios problemas, el más común de los cuales es la aparición de bloques BAD. Esto es especialmente cierto para los modelos más antiguos. unidades de disco duro, que todavía se puede utilizar (en particular, en empresas donde las películas, los juegos y otros contenidos "pesados" no se guardan en las computadoras) y que ya están bastante desgastados. Muchos usuarios se sorprenden y no saben qué hacer a continuación. Por eso se escribió este artículo. En él, veremos todas las formas disponibles en el hogar para deshacerse de estos problemas.
Un poco de historia
Malos sectores ( De inglés. - malo malo) está disponible en cualquier disco duro. No importa cuán cuidadosamente estén hechos sus discos, hay varios lugares en cada uno de ellos, cuya escritura o lectura está acompañada de errores. Además, simplemente hay áreas con errores en la superficie que eventualmente pueden convertirse en defectos, lo cual es inaceptable para el usuario. Por lo tanto, después de la fabricación en la fábrica, cada unidad se somete a pruebas exhaustivas, durante las cuales se detectan sectores defectuosos. Se marcan como inutilizables y se ingresan en una tabla especial: lista de defectos.
el primero unidades de disco duro tenía una lista de defectos en forma de una etiqueta de papel, en la que se ingresaban las direcciones de las secciones inestables en la fábrica. Estos dispositivos, que son una copia ligeramente modificada de una disquetera convencional, solo podían funcionar bajo sus parámetros físicos: la cantidad de pistas, sectores y cabezas indicadas en su pasaporte coincidía exactamente con su número real. Al comprar un dispositivo de este tipo, el usuario leyó la etiqueta y él mismo ingresó las direcciones de los sitios eliminados en FAT. Después de eso sistema operativo dejó de notar estos defectos, al igual que no nota los bloques defectuosos en los disquetes si la utilidad Scandisk los eliminó. Probablemente, en aquellos tiempos lejanos, apareció el término "bloque malo": un bloque se llamaba grupo- la unidad mínima de lógica Espacio del disco. A nivel físico, el clúster consta de varios sectores, y si un sector está dañado, el sistema operativo declara inutilizable todo el clúster. No existían otros métodos para ocultar defectos en ese momento. Y cuando aparecieron formas de ocultar ciertos sectores, la gente no inventó nuevos conceptos y aún continúa usando con éxito la palabra "bloquear".

No pasó mucho tiempo antes de que a los fabricantes se les ocurriera algo muy interesante: si el usuario aún marca los bloques defectuosos como innecesarios, razonaron, ¿por qué no marcarlos directamente en la fábrica? Pero, ¿cómo hacer esto si no hay un sistema de archivos en el disco duro y no se sabe cuál será? Fue entonces cuando se les ocurrió algo complicado llamado " traductor": comenzaron a escribir una tabla especial en los "panqueques", que indicaba qué sectores debían ocultarse al usuario y cuáles debían dejarse para él. El traductor se convirtió en una especie de enlace intermedio que conectaba el "drive-head" físico " sistema con la interfaz de la unidad.
Se suponía que, cuando se encendía, el disco duro primero leería sus tablas internas, ocultando las direcciones de los defectos anotados en ellas, y solo entonces permitiría el BIOS, el sistema operativo y los programas de aplicación. Y para que el usuario no sobrescriba accidentalmente el traductor durante el trabajo, se colocó en un área especial del disco que es inaccesible programas regulares. Solo el controlador podía acceder a él. Este evento supuso una verdadera revolución en la construcción de unidades de disco duro y marcó el surgimiento de una nueva generación de unidades, con un área de servicio.
Para que todos los tornillos del mismo modelo, pero con un número diferente de defectos, tuvieran la misma capacidad, se dejaron pistas de repuesto en cada uno de ellos, una reserva especialmente prevista para igualar la capacidad del mismo tipo de unidades al estándar. valor declarado. Comenzó a colocarse al final del disco, cerca de su centro, y también era inaccesible para el usuario. Dichos discos duros no tenían más de un sector defectuoso visible cuando salieron de fábrica. Si aparecieran nuevos defectos durante la operación, el usuario podría hacer que el formateo de bajo nivel sea una utilidad universal desde el BIOS de la placa base e intentar ocultarlos. A veces, como con los disquetes, lo conseguían. Pero si los "espíritus malignos" eran físicos, esto no ayudó: era imposible agregar nuevos defectos a la mesa y reescribir el traductor sin programas especiales. Por lo tanto, los bloques defectuosos en muchos tornillos antiguos (hasta 1995) tenían que ocultarse con el mismo forma anticuada- a través de FAT. Y solo Seagate, Maxtor y Western Digital han lanzado utilidades para ocultar defectos y reemplazarlos de la reserva.
Ha pasado el tiempo y los tornillos han cambiado aún más. En un esfuerzo por aumentar la densidad de grabación, los desarrolladores comenzaron a usar varios trucos no estándar: comenzaron a aplicar etiquetas servo, diseñado para golpear con mayor precisión las cabezas en las pistas. Apareció la tecnología de grabación de sección de zona (ZBR), cuyo significado era un número diferente de sectores en las pistas exterior e interior. El accionamiento del cabezal ha cambiado: en lugar de un motor paso a paso, se ha utilizado un posicionador en forma de bobina móvil. Y los cabezales y los discos han cambiado tanto que cada empresa ha desarrollado su propia estructura de formato de nivel inferior, adaptada únicamente a sus tecnologías. Esto hizo imposible el uso de utilidades universales. formato de bajo nivel debido al hecho de que el traductor de dichos tornillos ha aprendido a ocultar el formato físico de las unidades, traduciéndolo a uno virtual.
La cantidad de cilindros, sectores y cabezales escritos en la caja del disco duro ya no correspondía a sus valores reales, y los intentos de formatear un tornillo de este tipo con utilidades antiguas, por regla general, terminaron en fracaso: su controlador rechazó el comando estándar ATA 50h, o simplemente imitar el formato, llenando el tornillo con ceros. Esto se dejó deliberadamente por compatibilidad con programas más antiguos. Por la misma razón, el procedimiento de formato de bajo nivel se excluyó del BIOS de los modernos placas base. Y para hacer que tales discos duros tuvieran un formato de bajo nivel real, era necesario pasar por alto el traductor, obteniendo acceso directo a las pistas y cabezas físicas. Para ello, comenzaron a utilizar una utilidad tecnológica que lanza un microcódigo especial grabado en la ROM del disco. El comando para llamar a este microcódigo es único para cada modelo y se refiere a comandos tecnológicos que no son divulgados por la empresa. A menudo, dicho formateo no se podía realizar a través de una interfaz IDE estándar: muchos modelos de HDD de los años 90: Conner, Teac, etc., así como todos los Seagates modernos, requieren un conector separado para conectarse al terminal a través de un puerto COM.
En cuanto a las utilidades tecnológicas, nunca se han distribuido ampliamente y no estaban disponibles para el usuario promedio. Para un uso generalizado, se escribieron "programas estúpidos" que realizan un pseudoformateo a través de la interfaz: llenan el disco con ceros para limpiarlo de información. Esto se puede ver incluso en los nombres de estas utilidades, que se pueden encontrar en los sitios web de los fabricantes de discos duros: wdclear, fjerase, relleno cero etc. Naturalmente, no hay comandos tecnológicos en estos programas y, por lo tanto, se pueden aplicar a cualquier disco duro. Tales utilidades a menudo resultan útiles para ayudar a deshacerse de ciertos tipos de BAD, de los que hablaremos un poco más adelante.
¿Por qué los fabricantes actuaron con tanta crueldad, privándonos de la oportunidad de realizar un formateo de bajo nivel adecuado y ocultar los defectos nosotros mismos? Todavía no hay consenso sobre esta pregunta, pero la respuesta oficial de la mayoría de las empresas suena más o menos así: "esta es una operación tan complicada y peligrosa que un usuario común no debería poder realizarla, de lo contrario, muchos discos duros simplemente morirán". Por lo tanto, el formateo de bajo nivel solo se puede realizar en la fábrica o en un centro de servicio autorizado.
Tratemos de averiguar si este es realmente el caso. Y al mismo tiempo, consideremos qué es el formateo real de bajo nivel de los discos duros modernos, ¿es posible hacerlo usted mismo y, lo más importante, lo necesitamos?
Preparación del disco duro en fábrica
Antes de ocultar sectores defectuosos en la fábrica, es muy importante identificar todos los defectos, incluso los más pequeños, así como las áreas inestables que eventualmente pueden convertirse en bloques defectuosos. Después de todo, si esto sucede durante la operación, el usuario puede perder un archivo importante y la reputación de la empresa que lanzó dicha unidad "inacabada" se dañará. Por lo tanto, probar los discos duros antes de ocultar los defectos lleva mucho tiempo, al menos varias horas, y se lleva a cabo de forma tecnológica. Esto se hace para eliminar los retrasos de tiempo que surgen inevitablemente durante la operación del traductor, la transferencia de datos a través de la memoria caché y la lógica de la interfaz. Por lo tanto, en la fábrica, la superficie se escanea solo por parámetros físicos. Por lo general, esto no lo hace un programa externo, sino un módulo especial en la ROM del disco duro, que funciona sin la participación de una interfaz. El resultado final de dicha prueba es la recepción de una lista de defectos, una lista electrónica de áreas inutilizables del espacio del disco. Se lleva al área de servicio del tornillo y se almacena allí durante todo el período de funcionamiento.

Los discos duros modernos tienen dos listas de defectos principales: una se completa en la fábrica durante la fabricación de la unidad y se llama lista P (-primario), y la segunda se llama lista G (de la palabra - creciente), y se repone durante el funcionamiento del tornillo, cuando aparecen nuevos defectos. Además, algunos tornillos también tienen una lista de defectos de servo (las marcas de servo aplicadas a los discos duros a veces también tienen errores), y muchos modelos modernos también contienen una lista de defectos temporales (pendientes). El controlador ingresa en él sectores que son "sospechosos" desde su punto de vista, por ejemplo, aquellos que no fueron leídos la primera vez, o con errores.
Habiendo recibido la lista de defectos, comienzan a ocultar los defectos. Hay varias formas de ocultarlos, cada una de las cuales tiene sus propias características. En teoría, puede simplemente reasignar las direcciones de los sectores defectuosos a una reserva y tomarlos de allí, pero esto provocará una pérdida en el rendimiento del tornillo, ya que cada vez que encuentre un sector marcado como defectuoso, se verá obligado a mover las cabezas a un área de repuesto, que puede estar lejos del defecto. Si hay muchos sectores reasignados, el rendimiento de la unidad disminuirá mucho, ya que la mayor parte del tiempo se gastará en sacudidas inútiles de las cabezas. Además, la velocidad de los tornillos con un número diferente de defectos variará mucho, lo que, por supuesto, es inaceptable en la producción en masa. Este método de ocultar defectos se llama " método de sustitución" o reasignar (De inglés. reconstrucción del mapa del sector).
Debido a las numerosas deficiencias inherentes a la reasignación, este método nunca se usa en la producción industrial de tornillos, pero se usa un algoritmo diferente: después de que se detectan todos los defectos, las direcciones de todos los sectores buenos se vuelven a escribir, de modo que sus números sean en orden. Malos sectores simplemente se ignoran y no participan en trabajos posteriores. El área de repuesto también permanece continua y parte de ella se adjunta al final del área de trabajo, para igualar el volumen. Este método de ocultar defectos es más difícil de implementar que una reasignación, pero el resultado vale la pena el esfuerzo invertido en él: con cualquier cantidad de sectores defectuosos, la unidad no se ralentiza. Este, el segundo tipo principal de defectos de ocultación, se denomina " método de salto de sector". (Hay otros algoritmos para ocultar defectos de fábrica, por ejemplo, al excluir una pista completa o usar un sector de repuesto en cada pista, pero tienen inconvenientes y, por lo tanto, prácticamente no se usan en las unidades modernas).

El proceso de volver a calcular las direcciones mientras se saltan los defectos se denomina "formato interno". Interno: porque todo el proceso se lleva a cabo completamente dentro del disco duro, en direcciones físicas y sin la participación de una interfaz. En este momento, el tornillo está bajo el control del firmware integrado en su ROM, que analiza la lista de defectos y gestiona el formateo. No puede ser interrumpido por comandos externos. Una vez finalizado el formateo, el firmware vuelve a calcular automáticamente el traductor (o lo crea de nuevo) y el tornillo queda listo para usar. Después de eso, él, sin un solo bloque malo, viene de la fábrica al comprador.
Nuevas tecnologías
Ahora está claro por qué las utilidades propietarias no realizan ninguna operación relacionada con el acceso directo al área de servicio. Después de todo, ocultar defectos mediante el formateo es un ciclo de reparación casi completo basado en parámetros externos y asociado con una comprensión clara de cada paso. Y es suficiente hacer algo mal para arruinar el disco. Tomemos un ejemplo simple: un usuario decide hacer un formato de bajo nivel "real" ejecutando una rutina ROM en modo de producción. El proceso generalmente dura de 10 a 60 minutos, pero luego hay una falla de energía o una congelación banal, y el tornillo se queda sin traductor, desde entonces. simplemente no puede volver a crearlo. Esto significa que dicho dispositivo no será adecuado para el trabajo posterior; ni el sistema operativo ni el BIOS simplemente lo verán.

Da miedo incluso imaginar cuántas unidades se pueden matar de esta manera, por simple curiosidad o por error. Especialmente si estas utilidades caen en manos de tontos que ejecutan todo en sus computadoras. Por supuesto, el disco no se deteriora de manera irrevocable y, al reiniciar el formateo, puede devolverlo a la vida. Pero el pensamiento de la mayoría de los usuarios está dispuesto de tal manera que ante los problemas (un cadáver que no se detecta en la BIOS en lugar de un tornillo), muchos entran en pánico, culpando de todo a los fabricantes. Y, naturalmente, no necesitan problemas innecesarios: es mucho más importante hacer que el disco duro funcione durante el período de garantía. Por lo tanto, hace varios años, comenzaron a colocar en las unidades la capacidad de "reparar" las secciones defectuosas por sí mismas: hacer un REMAP. Como se mencionó anteriormente, la reasignación no encontró aplicación en la preparación de unidades de fábrica, pero resultó ser una muy buena solución para ocultar defectos en las condiciones domésticas.
Las ventajas de una reasignación sobre el formateo interno son la ausencia de una transferencia de tornillo al modo tecnológico, la velocidad de ejecución y la seguridad para la unidad. Además, en muchos casos se puede realizar una reasignación sin eliminar el sistema de archivos y sin la destrucción de datos asociada. Esta tecnología se llama reasignación automática de defectos(reasignación automática de defectos), y el propio proceso - reasignar. De este modo reasignar y reasignar- esto es en general lo mismo, aunque el término reasignar generalmente se aplica a un solo sector y reasignar - a todo el disco.
Remap funciona de la siguiente manera: si se produce un error al intentar acceder a un sector, el controlador "inteligente" entiende que este sector está defectuoso y "sobre la marcha" lo marca como MALO. Su dirección se ingresa inmediatamente en la tabla de defectos (lista G). Con muchos tornillos, esto sucede tan rápido que el usuario ni siquiera se da cuenta de que se ha descubierto y ocultado un defecto. Durante el funcionamiento, la unidad compara constantemente las direcciones de los sectores actuales con las direcciones de la tabla y no accede a los sectores defectuosos. En cambio, mueve las cabezas al área libre y lee el sector desde allí. Desafortunadamente, debido al tiempo que lleva el posicionamiento lejano, estos sectores se verán como pequeñas caídas en el gráfico de lectura. Lo mismo será cierto para la grabación.
Si se produce un error durante el funcionamiento normal del sistema operativo, la reasignación automática es extremadamente rara. Esto se debe a que, en la mayoría de los discos duros, la reasignación solo funciona en las escrituras. Y muchos sistemas operativos verifican la integridad del sector antes de escribir, y cuando detecta un error, se niega a escribir en él. Por lo tanto, en la mayoría de los casos, para realizar una reasignación, el tornillo debe ser "solicitar" esto: realizar una sobrescritura forzada de bajo nivel del sector, sin pasar por las funciones estándar del sistema operativo y BIOS. Esto lo hace un programa que puede acceder al disco duro directamente a través de los puertos del controlador IDE. Si ocurre un error durante dicha escritura, el controlador reemplazará automáticamente este sector de la reserva y el BAD desaparecerá.

Este principio es la base para el trabajo de la mayoría de las utilidades del llamado "formateo de bajo nivel" de los fabricantes. Todos ellos, si se desea, pueden usarse para tornillos de otras compañías (si dichos programas se niegan a funcionar con unidades de otras personas, esto se hace por razones de marketing). Y, por supuesto, las funciones de reasignación están presentes en muchos programas universales y gratuitos, cuyas características consideraremos un poco más adelante. Mientras tanto, un poco más de teoría.
El mito más común entre los usuarios es la afirmación de que cada tornillo necesita su propio programa "especial" para ocultar defectos, así como que remap es un formato de bajo nivel. En realidad no lo es. Remap es solo un tipo de registro de información medios estándar y, en la mayoría de los casos, se puede aplicar cualquier herramienta de reasignación a cualquier tornillo. Reasignar no programas externos y el controlador del disco duro. Solo él decide sobre la reasignación de sectores defectuosos. Los programas "extraños" tampoco pueden dañar la unidad, ya que no utilizan comandos tecnológicos y, en modo normal, el tornillo nunca le permitirá hacer nada con él, excepto las operaciones estándar de lectura y escritura. La única diferencia entre las utilidades propietarias es el número de intentos de escribir/leer/verificar para diferentes tornillos. Para que el controlador "crea" que hay un BAD oculto en el sector, basta un ciclo para algunos discos duros y varios para otros.
De nuevo sobre S.M.A.R.T.
Casi todos los discos duros lanzados después del año 95 tienen un sistema para monitorear en tiempo real su condición: S.M.A.R.T. (Tecnología de autosupervisión y generación de informes). Esta tecnología le permite evaluar tales parámetros importantes unidad, como la cantidad de horas trabajadas, la cantidad de errores que ocurrieron durante el proceso de lectura/escritura, y mucho más. Los primeros discos duros equipados con este sistema (por ejemplo, el WD AC21200) tenían un SMART muy imperfecto de cuatro a seis atributos. Pero pronto se desarrolló el estándar SMART-II y, desde sus inicios, la mayoría de las unidades han introducido una característica como el diagnóstico interno y el autocontrol. Esta función se basa en una serie de pruebas internas independientes que se pueden iniciar con comandos ATA estándar y está diseñada para controlar en profundidad el estado de la mecánica de la unidad, la superficie del disco y muchos otros parámetros.
Una vez completadas las pruebas, la unidad debe actualizar las lecturas en todos los atributos SMART, de acuerdo con su estado actual. El tiempo de prueba puede variar desde unos pocos segundos hasta 54 minutos. Puede activar las pruebas SMART, por ejemplo, con el programa MHDD (comando de consola "prueba inteligente"). Después de ejecutar las pruebas, son posibles fenómenos "extraños", muy similares a los que ocurren durante el funcionamiento del desfragmentador: encendido continuo del indicador HDD y el sonido del movimiento intensivo de las cabezas. Esto es normal: el disco duro escanea la superficie para buscar defectos. Solo necesita esperar un momento hasta que termine la autocomprobación y el tornillo se calmará.
Más tarde, apareció la especificación SMART-III, que no solo tiene la función de detectar defectos en la superficie, sino también la capacidad de restaurarlos "sobre la marcha" y muchas otras innovaciones. Una de sus variantes fue el sistema salvavidas de datos utilizado en unidades Western Digital. Su esencia es la siguiente: si no se realizan solicitudes al tornillo, comienza a escanear la superficie por sí solo, identificando sectores inestables y, cuando se detectan, transfiere datos al área de respaldo. Entonces lo hace reasignar. Por lo tanto, los datos se guardan incluso antes de que ocurra el verdadero MAL en este lugar. A diferencia del monitoreo SMART, Data Lifeguard no se puede desactivar mediante comandos externos y siempre está activado. Por lo tanto, los bloques BAD "visibles" casi nunca aparecen en los discos duros modernos de Western Digital.
Para ver el estado SMART de un disco duro, se utilizan programas llamados monitores SMART. Uno de ellos es parte de HddUtil para DOS y se llama smartudm. Este programa funciona con cualquier unidades de disco duro y controladores. Además, viene con documentación detallada que describe todos los atributos. También hay monitores SMART para Windows 9x, como los muy populares SiGuardian y SmartVision, pero es posible que no funcionen en algunos sistemas. Esto se explica por el hecho de que los programas funcionan con el tornillo directamente, a través de puertos, y los controladores de masterización de bus de algunos conjuntos de chips interfieren con esto. Los propietarios de Windows XP deben prestar atención al monitor SmartView www.upsystems.com.ua/: la aplicación funciona correctamente en este sistema incluso en conjuntos de chips VIA.
Existe cierta relación entre los atributos SMART y el estado de la superficie. Consideremos aquellos que están directamente relacionados con bloques defectuosos:
Tipos de defectos y sus causas.
Es hora de resolverlo, pero ¿por qué, de hecho, hay tanta molestia como los males? Para ello, considere la estructura del sector, en la forma en que la electrónica de la hélice lo ve "desde adentro":
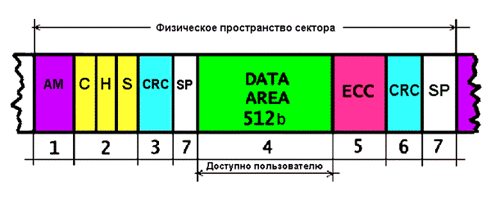
Arroz. 1. Estructura simplificada difícil disco
Como puede ver en la Figura 1, todo es mucho más complicado de lo que parece a primera vista, incluso con la ayuda de un editor de disco. Un sector consta de un encabezado de identificador y un área de datos. El comienzo del sector está marcado con un byte especial: el marcador de dirección (1). Sirve para informar al controlador que el sector está bajo la cabeza. A esto le siguen celdas que contienen una dirección de sector única en formato CHS (2) y su suma de verificación, para verificar la integridad de la dirección registrada (3). Se colocan 512 bytes de datos de usuario en un campo separado (4), al que, al escribir, se agregan varias decenas de bytes de información redundante para corregir errores de lectura mediante un código ECC (5). Junto a los datos se colocan 4 bytes de la suma de verificación cíclica (CRC) de los datos, que sirve para verificar la integridad de los datos del usuario e informar al sistema de corrección de errores si se viola (6). Para una operación más confiable del sector durante las fluctuaciones en la velocidad de rotación, hay espacios de bytes (7). Algunos discos duros tienen un byte adicional después de AM; en él, el sector está marcado como MALO.
La estructura del formato de bajo nivel varía mucho entre diferentes modelos unidades, y está determinado por el tipo de controlador utilizado, su firmware y el ingenio de los desarrolladores.
Mientras no se rompa la estructura del formato, el disco duro funciona correctamente, cumpliendo claramente sus funciones: almacenar información. Pero vale la pena interferir con las fuerzas del mal, y dependiendo del tipo de destrucción, aparecen como sectores MALOS de diversa gravedad.
Los defectos se pueden dividir en dos grandes grupos: físicos y lógicos. Consideremos cada uno de sus tipos en detalle.
Defectos Físicos
Defectos superficiales. Ocurren cuando el revestimiento magnético dentro del espacio del sector se daña mecánicamente, por ejemplo, debido a rayones causados por el polvo, panqueques envejecidos o manipulación descuidada. disco duro. Dicho sector debe marcarse como inutilizable y excluido de la circulación.
Errores de servo. Todos los accionamientos modernos utilizan un sistema llamado (bobina de voz) para mover las cabezas, que, a diferencia del motor paso a paso de los tornillos antiguos, no tiene ningún movimiento discreto. Para golpear con precisión las cabezas en las pistas de los tornillos, un sistema con retroalimentación, que son guiados por servomarcas magnéticas especiales impresas en el disco. Hay marcas de servo en cada lado de cada disco. Están ubicados uniformemente a lo largo de todas las pistas y estrictamente radialmente, como los rayos de una rueda, formando un formato de servo. No pertenece al formato de nivel inferior y no se muestra en la figura, pero absolutamente todos los discos duros modernos lo tienen y juega un papel importante. De acuerdo con las marcas de servo, la velocidad de rotación del motor se estabiliza y la cabeza se mantiene en una pista determinada, independientemente de las influencias externas y la deformación térmica de los elementos.
Sin embargo, durante el funcionamiento del tornillo, algunos servos pueden destruirse. Si hay demasiadas marcas de servo muertas, comenzarán a ocurrir fallas en este lugar al acceder a la pista de información: la cabeza, en lugar de tomar la posición que necesita y leer los datos, comenzará a moverse de un lado a otro. Parecerá un MALO gordo y especialmente arrogante, o incluso un grupo de ellos. Su presencia a menudo va acompañada de golpes de cabeza, congelación del disco y la incapacidad de repararlo con utilidades convencionales. La eliminación de tales defectos solo es posible con programas especiales, desactivando pistas defectuosas y, a veces, toda la superficie del disco. Para estos fines, algunas unidades tienen una lista de servos defectuosos que almacena información sobre marcas de servos defectuosos. A diferencia de las listas P y G, la lista de defectos de servo no es utilizada por el traductor, sino por todo el firmware de la hélice. El acceso a sectores con etiquetas de servo defectuosas está bloqueado incluso por parámetros físicos, lo que permite evitar golpes e interrupciones al acceder a ellos. El disco duro no puede restaurar el formato del servo por sí solo, esto se hace solo en la fábrica.
Sectores defectuosos de hardware. Ocurrir debido a un mal funcionamiento de la mecánica o electrónica del variador. Dichos problemas incluyen: rotura de cabezales, desplazamiento de discos o eje doblado como resultado de un impacto, polvo en el área de contención, así como varios fallos en el funcionamiento de la electrónica. Los errores de este tipo suelen ser catastróficos y no pueden ser corregidos por software.
Defectos lógicos
Estos errores no se producen por daños en la superficie, sino por violaciones de la lógica del sector. Se pueden dividir en corregibles e incorregibles. Los defectos lógicos tienen las mismas manifestaciones externas que los físicos, y solo pueden distinguirse indirectamente, según los resultados de varias pruebas.
Defectos lógicos corregibles (soft-bads): Aparece cuando la suma de verificación del sector no coincide con la suma de verificación de los datos escritos en él. Por ejemplo, debido a una interferencia o falla de energía durante la grabación, cuando el tornillo ya escribió datos en el sector, pero no tuvo tiempo de escribir la suma de verificación (Fig. 1). La lectura posterior de dicho sector "no escrito" fallará: el disco duro primero leerá el campo de datos, luego calculará su suma de verificación y comparará lo recibido con lo escrito. Si no coinciden, el controlador de la unidad decidirá que se ha producido un error y realizará varios intentos para volver a leer el sector. Si esto tampoco ayuda (y no ayudará, ya que la suma de verificación es obviamente incorrecta), entonces él, usando la redundancia de código, intentará corregir el error, y si esto no funciona, el tornillo dará un error. dispositivo externo. Desde el sistema operativo, se verá como MALO. Algunas unidades de disco duro tenían una mayor tendencia a formar fallas blandas debido a errores en el firmware: bajo ciertas condiciones, las sumas de verificación se calculaban incorrectamente; en otros se debió a defectos mecánicos.
El sistema operativo o el BIOS no pueden reparar el defecto lógico por sí solos, porque antes de escribir en el sector, verifican su integridad, se encuentran con un error y se niegan a escribir. Al mismo tiempo, el controlador de tornillo tampoco puede corregir este error: intenta en vano leer este sector en el segundo, en el tercer intento, y cuando esto falla, trata de ayudarse con todas sus fuerzas, ajustando el canal de lectura. y el sistema servo sobre la marcha. Al mismo tiempo, se escucha un traqueteo desgarrador. Este chirrido no es producido por "cabezas en la superficie", como muchos solían pensar, sino solo por la bobina del posicionador, debido a la forma específica de la corriente que fluye a través de ella, y es absolutamente seguro. La dirección del sector no leído ingresa a la lista de defectos temporales, cambiando el valor del atributo Sector Pendiente Actual en SMART, y se almacena en ella. La reasignación no se produce al leer.
Y solo la reescritura forzada de bajo nivel de este sector por un programa especial que pasa por alto el BIOS conduce al recálculo automático y la reescritura de la suma de verificación, es decir, el bloque BAD desaparece sin dejar rastro. Puede reescribirlo con un editor de disco que puede funcionar con un tornillo directamente a través de los puertos, pero generalmente "reescriben" todo el disco, llenando sus sectores con ceros. Los fabricantes de unidades distribuyen gratuitamente las utilidades que hacen esto y, a menudo, se denominan erróneamente "formateadores de bajo nivel". De hecho, se trata de simples "anuladores", lo que no les impide en lo más mínimo sacar el tornillo de los males: si la grabación es exitosa, los males blandos desaparecen, y si la grabación es fallida, el mal se considera físico, y se produce una reasignación automática.
Errores lógicos incorregibles. Estos son errores en el formato interno del disco duro, que tienen el mismo efecto que los defectos superficiales. Ocurren cuando los cabezales de sector se destruyen, por ejemplo, por la acción de un fuerte campo magnético sobre el tornillo. Pero a diferencia de los defectos físicos, pueden corregirse mediante software. Y se llaman irrecuperables solo porque para arreglarlos, es necesario hacer el formato de bajo nivel "correcto", que usuarios ordinarios difícil debido a la falta de servicios públicos especializados. Por lo tanto, en la vida cotidiana, dicho sector se apaga de la misma manera que uno físico, con la ayuda de una reasignación. Todo está actualmente gran cantidad Los tornillos se fabrican con tecnología ID-less (sectores sin cabezales), por lo que este tipo de error ya no es tan relevante.
Males "adaptativos". A pesar de que las hélices son dispositivos muy precisos, durante su producción en masa, inevitablemente se produce una variación en los parámetros de la mecánica, los componentes de radio, los revestimientos magnéticos y las cabezas. Esto no interfería con las unidades antiguas, pero para los tornillos modernos con su enorme densidad de grabación, las más mínimas desviaciones en el tamaño de las piezas o en las amplitudes de la señal pueden provocar un deterioro de las propiedades del producto, la aparición de errores, hasta un pérdida total de su rendimiento. Por lo tanto, todas las unidades modernas se someten a un ajuste individual durante la fabricación, durante el cual se seleccionan los parámetros de las señales eléctricas que hacen que el dispositivo funcione mejor. Esta configuración la realiza el programa ROM durante el escaneo tecnológico de la superficie. En este caso, se generan los llamados adaptativos: variables que contienen información sobre las características de un HDA en particular. Los adaptativos se almacenan en placas en el área de servicio y, a veces, en la memoria flash en la placa del controlador.
Si durante el funcionamiento del tornillo, los adaptadores se destruyen (esto puede ocurrir como resultado de errores en el tornillo mismo, electricidad estática o debido a una fuente de alimentación de baja calidad), entonces las consecuencias pueden ser impredecibles: de un montón banal de males a la completa inoperancia del dispositivo, con una negativa a ir a la preparación en la interfaz. Los males "adaptativos" se diferencian de los habituales en que son "flotantes": hoy lo son, pero mañana pueden desaparecer y aparecer en un lugar completamente diferente. Reasignar un tornillo de este tipo es inútil: los defectos fantasma aparecerán una y otra vez. ¡Y al mismo tiempo, la superficie del disco puede estar en perfectas condiciones! Los problemas adaptativos se tratan ejecutando selfscan, un programa de prueba interno similar al que se usa en la fábrica cuando se fabrican hélices. En este caso, se crean nuevos adaptativos y el tornillo vuelve a estado normal. Esto se hace en las condiciones de los centros de servicio de marca.
Defectos emergentes
Estas son áreas de la superficie en las que aún no se ha formado un defecto pronunciado, pero ya se notan problemas con la velocidad de lectura. Esto se debe al hecho de que el controlador no lee el sector la primera vez, y el tornillo se ve obligado a dar varias vueltas al disco, tratando de leerlo sin errores. Si aún logra leer los datos, entonces el tornillo no le dirá nada al sistema operativo, y el error pasará desapercibido hasta que aparezca un bloque BAD real en este lugar. Como regla, inmediatamente resulta que fue en este lugar donde se almacenó un archivo muy importante, en una sola copia, y ya no se puede guardar. Por lo tanto, los discos deben probarse periódicamente. Esto se puede hacer con Scandisk o Norton Disk Doctor en modo de prueba de superficie, pero es mejor con una utilidad especial que funciona independientemente del sistema de archivos y puede detectar sectores defectuosos emergentes midiendo el tiempo de lectura de cada sector.
Práctica
Cada empresa que produce discos duros suele desarrollar software especial para el diagnóstico y mantenimiento de sus unidades, publicándolo en la Web para uso gratuito. A veces, estas utilidades ya contienen un sistema operativo (generalmente una de las variedades de DOS), como Sea Tool de Seagate o Drive Fitness Test de IBM (ahora Hitachi). Y a veces es solo un archivo ejecutable que necesita ejecutar desde DOS usted mismo, como Maxtor (ya propiedad de Seagate) o Fujitsu. Dicho software le permite probar la unidad en busca de errores y, si es posible, corregirlos. Entre los métodos de corrección, a menudo puede encontrar las funciones de limpiar el disco (rellenarlo con ceros y destruir toda la información), así como ocultar defectos utilizando el método de reasignación. Pero no consideraremos las utilidades propietarias; como aprendimos, estos programas hacen cosas bastante estándar: escribir ceros y verificar la superficie. Por lo tanto, prestemos atención a algunos programas alternativos muy buenos.
Entonces, tenemos una cosita tan divertida como "mal duro". O queremos asegurarnos de "sorpresas" y comprobarlo mientras está funcionando. Para ello, en primer lugar, el programa MHDD. Cualquiera que tenga tornillos antiguos de hasta 8,4 GB, especialmente los antiguos Western Digital, se recomienda tener un programa DOS en el hogar.
En primer lugar, debe preparar el software de diagnóstico y crear disco de inicio con MS-DOS. puede donar disquete de arranque Windows 9x eliminando todos los archivos excepto io.sys, msdos.sys y command.com. En el espacio liberado escribimos el archivo ejecutable del programa MHDD: mhdd2743.exe y el archivo de configuración mhdd.cfg. Como todavía hay mucho espacio libre en el disquete, escribimos el monitor SMART smartudm.exe y algún administrador de archivos, por ejemplo, Volkov Commander. Lo necesitará para ver el contenido de los informes de funcionamiento del programa. Para mayor comodidad, todos los archivos se colocan en el directorio raíz del disquete. Alternativamente, no puede crear un disquete en absoluto o usarlo solo para iniciar DOS, y ejecutar todos los programas directamente desde el disco duro principal conectando el tornillo para verificarlo en otro canal. No necesita grabar programas en un CD para ejecutarlos desde allí; el disco debe estar abierto para escribir, ya que los programas crearán registros de operación en él y, si fallan, simplemente fallarán. Después de leer detenidamente la descripción de MHDD y SMARTUDM, puede proceder a la ejecución. Primero, veamos la información SMART de nuestro disco (en el futuro, esto tendrá que hacerse más de una vez).
Arrancamos desde nuestro disquete y, si el tornillo investigado cuelga del canal IDE principal, escribimos línea de comando: a:smartudm, y si está en el secundario - a:smartudm 1. Si hay más de dos discos duros en el sistema, entonces el número puede ser mayor que 1. Veremos una tabla que caracteriza el estado del disco (Fig. . 2).
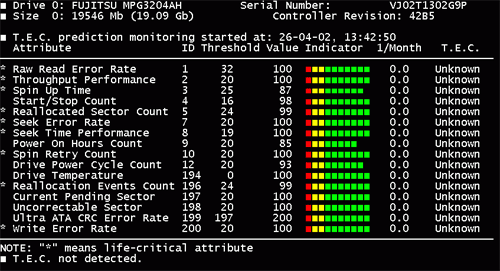
Figura 2. Gráfico de estado SMART del disco duro para una evaluación rápida de su estado
Cada línea de la tabla es uno de los parámetros del estado actual del tornillo. Frente a cada uno de ellos, en la columna "Indicador", hay una escala dividida en tres zonas de colores. A medida que la unidad se desgasta, la longitud de los indicadores disminuye, ya que cada vez más cuadrados verdes en su lado derecho se apagan. Sigue siendo amarillo y rojo. Cuando desaparecen todos los cuadrados verdes de cualquier indicador, significa que el tornillo ha agotado su recurso o está averiado. Al mismo tiempo, se recomienda guardar los datos importantes, ya que en cualquier momento el tornillo puede morir por completo. Si solo queda un cuadrado rojo, el tornillo ya se encuentra en un estado de emergencia y no es adecuado para el almacenamiento posterior de archivos.
La inscripción "T.E.C. no detectado" significa que el estado actual del tornillo está en perfecto orden. Si este no es el caso, se emitirá una advertencia, resaltada en rojo. Al mirar la tabla de colores, puede evaluar rápidamente qué atributo SMART en particular causó tal insatisfacción con el programa. Cuando un número grande badov probablemente será el primero (Tasa de error de lectura sin procesar). Pero esta información es aproximada, y necesitamos los valores absolutos de los atributos, entonces hacemos clic y vemos algo como esto (Fig. 3):

Fig. 3. Estado avanzado del disco duro SMART (valores de atributos exactos)
Este modo de monitor SMART es el principal y lo usaremos para monitorear el estado de la unidad en cualquier otra acción. Por ejemplo, al observar el valor del atributo 5 (Recuento de sectores reasignados), veremos el contenido de la lista de defectos personalizados y podremos juzgar si los defectos se ocultaron correctamente. Cuando se presiona la tecla, el registro SMART actual se guarda en un archivo. Presionando la tecla puede salir del programa en DOS. El controlador actualiza algunos atributos sobre la marcha, varias veces por minuto, por lo que para obtener el resultado más confiable, se debe probar el tornillo, lo cual haremos ahora.
Salimos del monitor SMART y ejecutamos el programa MHDD ingresando el nombre de su archivo ejecutable en la línea de comando. Después de cargar, debe presionar inmediatamente la combinación de teclas: el programa escaneará el bus y mostrará una lista de unidades conectadas al sistema. Seleccione el que desea comprobar escribiendo en la consola el numero deseado del 1 al 10 (Fig. 4). Luego presione para inicializar el tornillo seleccionado.
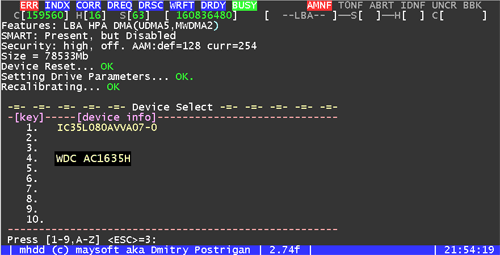
Figura 4. Inicialización de la hélice de comando
Después de estos pasos, la unidad mostrará información sobre su volumen, el modo DMA máximo admitido y mucho más. El programa MHDD ve los tornillos como un todo, sin ningún interés en su partición y tipo de sistemas de archivos. Verá todos los tornillos IDE, ya sea que estén definidos en el BIOS o no. Incluso si la placa base no admite unidades de gran capacidad, el programa aún las verá a plena capacidad, siempre que las unidades de disco duro estén funcionando. Si esto ocurre, puede proceder a comprobar la superficie.
Para hacer esto, presione y configure el parámetro en la línea superior del menú que aparece (el valor predeterminado es CHS). El cambio entre los modos CHS y LBA se realiza con la barra espaciadora. Luego presione una segunda vez. Aparecerán rectángulos grises en la pantalla. Esto tomará de 10 a 30 minutos y es absolutamente seguro para la información almacenada en el disco, ya que solo lee sectores. Esto es lo que el autor del programa escribió sobre este modo en la documentación del mismo:
"Al realizar una prueba de superficie, aparecerá una ventana a la derecha. La primera línea de esta ventana mostrará la velocidad de superficie actual. La última línea mostrará dos valores porcentuales. El primer valor muestra el porcentaje de la prueba actual completada en el intervalo especificado, y el segundo muestra qué tan lejos llegaron las cabezas 0 cilindro y el último. En el proceso de prueba de la superficie, un cuadrado es igual a 255 sectores (cuando se prueba en modo LBA), o el número de sectores en el Línea de parámetros HDD (generalmente 63 - cuando se prueba en modo CHS). La unidad tardó más tiempo en leer este bloque de sectores. Si aparecen cuadrados de colores, significa que la unidad no encajaba en el período de tiempo asignado para que trabajo. Los cuadrados de colores indican un estado anormal de la superficie (pero sin defectos todavía). Cuanto más bajo sea el color en el menú, más tiempo tardará la unidad en leer esta sección difícil de leer. El color rojo es una señal de que casi se ha formado un bloque MALO en este lugar. Aparece un signo de interrogación cuando se ha excedido el tiempo máximo de espera. Es decir, cuando aparece [?], podemos suponer que la unidad "cuelga" en este lugar y claramente hay un defecto grave en la superficie o una unidad de cabeza magnética (MHG) está defectuosa. Cualquier cosa debajo del signo de interrogación es un bloque MALO. Si aparecen durante las pruebas, entonces hay defectos físicos en la superficie".
En presencia de bloques MALOS, los iconos [x] suelen aparecer en lugar de cuadrados, obviamente simbolizando cruces. Si la superficie está en orden y sin cuadrados de colores, y todos los atributos SMART están en la zona verde, puedes respirar libremente: el tornillo sigue funcionando.
Si MHDD mostró que hay defectos en la superficie y el tornillo se "congela" o emite sonidos de raspado, entonces hay problemas. Pero no pensemos en lo malo de inmediato: después de todo, los malos pueden ser lógicos (malos suaves), por lo que primero organizaremos una "limpieza de cerebro" para el disco: realizaremos una escritura de ceros de bajo nivel en todos los sectores. (¡Atención! En este caso, toda la información será destruida, por lo que copiaremos los datos importantes a otro disco). El programa MHDD tiene dos comandos para poner a cero los discos: borrar y borrar. Usaremos el primero ya que es más rápido.
Inicializamos el tornillo presionando la tecla (es recomendable hacer este procedimiento antes de cualquier acción), e ingresamos el comando ERASE en la consola. Tenga mucho cuidado al elegir una unidad, de lo contrario, puede arruinar por error su tornillo de trabajo: los datos se pierden irremediablemente, ¡e incluso el FSB no los restaurará! El procedimiento de limpieza es bastante lento, tarda varias decenas de minutos. Pero en el futuro, después de haber descubierto un poco con el programa, puede borrar el disco de forma selectiva ingresando el número de sector de inicio y finalización antes de comenzar el procedimiento. Esto es muy conveniente si los malos están más cerca del final del disco y su comienzo es impecable.
Después de la limpieza, comenzamos de nuevo la prueba de la superficie (pulsando dos veces o con el comando SCAN de la consola). Al mismo tiempo, el controlador de la hélice debe recalcular los atributos SMART vitales, lo que hará que su estado SMART sea más confiable. Si no hay más averías, el tornillo se puede considerar reparado. Salimos de MHDD, iniciamos nuestro monitor SMART y observamos el valor del atributo Recuento de sectores reasignados. Si no aumentó después de la limpieza y los defectos desaparecieron, entonces eran lógicos. Si aumentó, eran físicos y el controlador reasignó con éxito estos sectores. Si, por el contrario, los males persisten y el valor del atributo Raw Read Error Rate ha bajado catastróficamente, todo es mucho más complicado y el tornillo está seriamente dañado. Intentaremos tratarlo más, para hacer una reasignación.
Es posible que ya haya notado que cuando presiona la tecla una vez en MHDD, aparece un menú que contiene opciones de escaneo adicionales (Fig. 5)
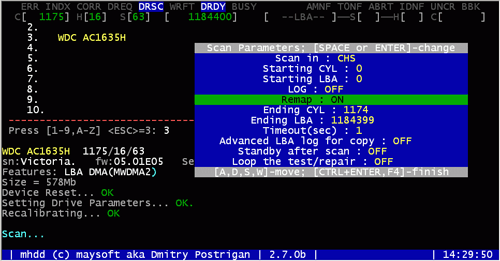
Figura 5. Configuración de escaneo y reasignación
Entre estos parámetros hay una función de reasignación. Por defecto está deshabilitado, pero colocando el cursor sobre él y presionando la barra espaciadora, puedes habilitarlo (Remap: ON). En este modo, MHDD intentará curar el sector defectuoso, mostrándole al controlador de todas las formas posibles que hay un BAD allí y que debe ocultarse. Al mismo tiempo, aparece un cuadrado azul o una inscripción junto a cada sector oculto con éxito. Después de eliminar todos los problemas, debe volver a ejecutar la prueba de superficie, salir de MHDD y volver a iniciar el monitor SMART, asegurándose de que el valor del Recuento de sectores reasignados haya aumentado. Esto significa que la reasignación fue exitosa, sin errores, y los defectos fueron efectivamente reemplazados de la reserva.
Si por alguna razón no quieres perder información de un disco duro dañado, por ejemplo, no hay dónde guardarla, no te desesperes. Puedes intentar no reinicio completo y vaya directamente a la reasignación usando MHDD. La información del tornillo no se borra, excepto, quizás, la que estaba en los propios malos (pero aún no se puede devolver). Al encontrar fallas, el programa les aplicará las mismas medidas que al poner a cero: un registro de bajo nivel y, por lo tanto, incluso si las fallas resultan ser lógicas, lo más probable es que puedan corregirse. El resultado exacto depende de la implementación del firmware del modelo de unidad en particular. Pero si esto no ayuda, y los defectos no desaparecen, aún habrá que hacer un reinicio, por si acaso. En algunos casos, solo el uso del comando "aerase" puede ayudar (reinicia el tornillo usando un algoritmo diferente, pero funciona más lentamente).
El programa MHDD se complementa y mejora constantemente. Por lo tanto, visitando su sitio web oficial, puedes descargar su última versión.
Puede suceder que incluso después de todas las operaciones realizadas, los problemas permanezcan y SMART muestre que la reasignación no está ocurriendo. Puede haber varias razones:
Pero no se apresure a tirar ese disco. Si está relativamente actualizado y no tiene una lista de defectos desbordante (el atributo 5 es normal), todavía hay esperanza de una reasignación. Solo necesita intentar aplicarle otro programa que tenga más ciclos de escritura en el sector defectuoso. Dichos programas incluyen HDD Utility para DOS. Funciona un poco diferente a MHDD: separa las funciones de verificación de superficie y reasignación, y la reasignación se realiza según el protocolo creado durante el escaneo. Por lo tanto, primero comenzamos la verificación pasando por la cadena: - -, y luego vamos al punto - - (Fig. 6). Antes de eso, es recomendable familiarizarse con la descripción de este programa, ya que es muy detallada y está escrita en ruso. Desventajas de la utilidad Hdd: malentendido de las unidades con una capacidad de más de 8.4 GB y negativa a trabajar con algunos modelos (este último se debe a la limitación versión gratuita). Pero esto no es tan importante: los tornillos "difíciles de quitar" generalmente tienen una capacidad pequeña; por lo general, estos son varios modelos Western Digital con una capacidad de 0.65-6.4 GB. Para tornillos grandes, puede usar el programa HddSpeed v.2.4, también tiene funciones de reasignación (Intentar reparar/reasignar defectos encontrados) y Descripción rusa(Figura 6).
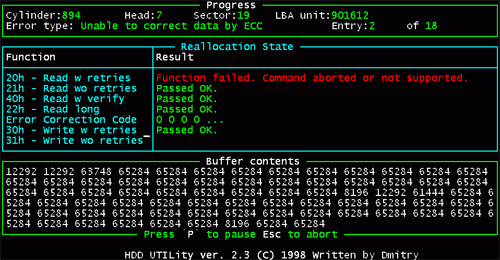
Figura 6. Utilidad de disco duro. El proceso de ocultar sectores defectuosos
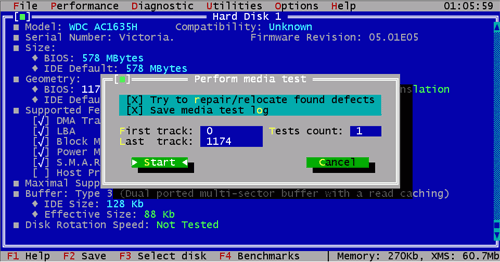
Arroz. 7: reasignar con HddSpeed
Es imposible evaluar el estado real del variador según el gráfico obtenido a través de su interfaz. Esto se explica por el hecho de que inevitablemente ocurren retrasos durante el funcionamiento de la interfaz, ya que el controlador de tornillo, además de transmitir datos, realiza muchas otras operaciones: conversión de direcciones físicas a LBA, gestión de defectos, registro de registros SMART internos, verificación de datos y cálculo de sus checksums, gestión de la estrategia de almacenamiento en caché, calibración térmica, etc. Por lo tanto, este método es adecuado solo para una evaluación aproximada del tornillo, la detección de errores graves y se usa solo en la vida cotidiana. Esto lo entienden bien los autores de los programas de prueba, señalando la imposibilidad de utilizar sus resultados como prueba alguna. Las pruebas bajo DOS puro se consideran las más fiables. En entornos multitarea, la situación es peor, ya que cualquier proceso en segundo plano distorsiona los intervalos de tiempo, lo que impide evaluar correctamente el estado del disco.
Métodos alternativos de ocultación de defectos
Como se mencionó anteriormente, la reasignación tiene un inconveniente, que se manifiesta en forma de tirones con la cabeza hacia el área de reserva. En este caso, el tornillo puede hacer clic durante la operación y las caídas serán visibles en el gráfico. Esto puede hacer que sea muy difícil, por ejemplo, trabajar con transmisión de video. Esto es especialmente pronunciado cuando los reasignaciones se ubican al comienzo del disco: en este caso, las cabezas recorren el camino máximo y los retrasos en su movimiento son muy grandes. Por lo tanto, en algunos casos, una reasignación puede no ser apropiada, pero en su lugar La mejor decision los defectos se ocultarán mediante el sistema de archivos. Por ejemplo, el formato habitual de alto nivel format.com, Scandisk o Norton Disk Doctor. Solo necesita decidir este paso inmediatamente después de verificar la superficie, sin intentar reasignar el tornillo. De lo contrario, si tiene éxito, será imposible devolver los malos y limpiar la tabla de defectos. La reasignación es un procedimiento único, y si el controlador de tornillo transfirió direcciones de sector a la reserva, será imposible devolverlas.
Otra alternativa a la reasignación es cortar el espacio al final del disco utilizando la tecnología HPA (Área protegida del host), que está disponible en todos los tornillos modernos. En este caso, el tornillo se determinará en el BIOS en un volumen más pequeño, y todos los problemas, si se encuentran al final, permanecerán "por la borda" y se volverán invisibles. Este método debe aplicarse a las unidades que tienen muchas fallas al final del disco (desafortunadamente, esto es raro). En cualquier momento, el tornillo puede volver a su capacidad máxima y, en consecuencia, los malos también. Esto se puede hacer con el programa MHDD ( comandos de consola HPA y NHPA). Si el tornillo es viejo y no es compatible con HPA, entonces puede crear una partición lógica separada, y no solo al final, sino también en cualquier otro lugar del disco, y organizarlo para que haya un gran grupo de elementos defectuosos. . Esto lo hace el programa Fdisk. Esta sección se puede puntuar archivos basura, o no puede formatearlo en absoluto, asignándole el estado "non-dos" (entonces se volverá invisible para el sistema).
Pero la mayoría La mejor manera elimine los defectos del tornillo, especialmente si hay muchos, o si no se pueden reasignar: reparación de banco por un especialista calificado. Con la ayuda de equipos y utilidades especiales, puede realizar un ciclo de reparación completo, similar al que pasa el tornillo en la fábrica: formateo de bajo nivel correcto, limpieza del tornillo de reasignaciones, restauración servicio de información, y mucho más. Después de tal reparación, la hélice será indistinguible de una nueva, tendrá un programa fluido y, lo que es más importante, dicha hélice tendrá un margen de seguridad durante varios años.
Contrariamente a la creencia popular, la reasignación y el formateo de bajo nivel no son una solución única para todos. Si el tornillo tiene un mal funcionamiento grave del hardware, estas acciones no solo no curarán al paciente, sino que también pueden dañarlo y acabar con él por completo. Por ejemplo, si el tornillo golpea monótonamente sus cabezas cuando está encendido y no quiere ser detectado en el BIOS, o golpea al copiar archivos, no lo atormente. herramientas de software no ayudarán. Este comportamiento generalmente se asocia con una rotura física de las cabezas, servos destruidos o un mal funcionamiento del controlador. Dicho tornillo no necesita formateo, sino reparación por parte de un especialista competente.
Características, fallas y prevención.
No todos los tornillos se deterioran debido a un manejo descuidado. A veces, la causa de sus fallas son los errores cometidos por los propios desarrolladores. Algunos de ellos tienen consecuencias irreparables, ya que pueden dañar físicamente la superficie magnética. Este fue el caso, por ejemplo, en 1996 con los discos duros Quantum ST. Debido a un error en el microcódigo, estos tornillos desatascaron las cabezas un poco antes de que las tortitas ganaran la velocidad deseada. Como resultado, las cabezas arañaron la superficie, lo que provocó una gran cantidad de bloques defectuosos y una falla rápida de la unidad. Pero esto no sucedió durante el funcionamiento normal, sino solo cuando el tornillo salió del modo de suspensión, por lo que para muchos esta falla pasó desapercibida. Y solo después de la reorganización del sistema operativo, si olvidó apagar el "bajo consumo de energía", el tornillo comenzó a desmoronarse. Esta enfermedad estaba tan extendida que popularmente se la llamó "despertador de la abuela", por el característico sonido metálico que hacía la hélice cuando "se tiraban los cascos". Después de cada "despertar", el tornillo recibió una nueva porción de defectos, y los intentos de hacer una reasignación ayudaron solo mientras hubiera suficiente espacio en la tabla de defectos. Por lo tanto, para salvar los tornillos supervivientes, Quantum lanzó un parche. Desafortunadamente, ya era demasiado tarde: casi todas las hélices de esta serie se apagaron en menos de un año.

Los discos duros Old Western Digital tenían problemas similares en 1995, pero tenían defectos al final del disco. A menudo hay una falla de este tipo: el tornillo simplemente deja de detectarse en el BIOS. La razón es un error del programador que escribió el firmware, como resultado de lo cual el tornillo estropea el área de servicio: debido al desbordamiento de los registros de errores internos, las áreas adyacentes se sobrescriben, sin las cuales el HDD se niega a funcionar. Como regla general, esto está precedido por algún tipo de falla, por ejemplo, la aparición de bloques MALOS o el overclocking fallido del bus. Esto es exactamente lo que sucedió con la serie IBM DTLA: el error acechaba en SMART y, si estaba encendido, el tornillo moría. Seagate, Fujitsu y muchos otros han tenido problemas similares. Por lo tanto, debe monitorear el lanzamiento de actualizaciones para su disco duro y "cambiarlas" regularmente. A diferencia del firmware. BIOS de la placa base tableros, esto debe hacerse: si la compañía lanzó el firmware, entonces esto no es un accidente: tal vez se encontró un error grave, cuya eliminación lo salvará de problemas en el futuro.
Todavía hay un rumor entre muchos usuarios de que algunos tornillos mueren debido a un formateo de bajo nivel "incorrecto", por ejemplo, por un programa integrado en el BIOS de las placas base. Hasta ahora, no hemos podido encontrar suficiente evidencia de esto, pero había un modelo de un tornillo con un agujero en el microcódigo que podría provocar un efecto similar. Este es un Fujitsu de la serie TAU (alrededor de 1996), que maneja incorrectamente el comando 50h ATA: es con él que el BIOS realiza el formateo universal, y este comando está incluido en muchos programas a la HddSpeed. Por lo tanto, no debes tentar a la suerte formateando estos tornillos con utilidades poco conocidas o desde la BIOS.
Muchos tornillos antiguos, cuando se formateaban incorrectamente, adquirían un programa de lectura irregular. Puede solucionarlo reiniciando el disco en MHDD.
Otro tipo de software que solo se puede usar de los fabricantes son los interruptores de modo DMA: los cambios entre UDMA33/66/100 son un cambio en parte del microcódigo del tornillo, por lo que intentar usar la utilidad de otra persona puede provocar daños en el firmware y por lo tanto, a fallas con consecuencias impredecibles.
Eso es todo. Esperamos que este material te haya ayudado. Pero recuerde: cualquier número de bloques MALOS en un tornillo es motivo de reclamación de garantía. Y la imposibilidad de retirarlos sin degradar las características del disco es motivo para cambiar el dispositivo. Y si logra convencer al vendedor de esto, considere que la ocultación de los sectores MALOS fue 100% exitosa. Simplemente no se olvide de la prevención y es posible que no necesite ocultar nada.
Ejecutamos nuestro programa y vemos la siguiente ventana:
Seleccionamos en el menú "regeneración" (recuperación) el elemento "iniciar proceso en Windows" (iniciar el proceso en Windows). Para comenzar a escanear en busca de sectores defectuosos o bloques defectuosos, primero debemos "explicar" al programa qué es exactamente lo que queremos hacer.
En la siguiente ventana, debemos seleccionar el disco duro para escanear. En nuestro caso, es uno, selecciónelo y presione la inscripción "iniciar proceso".

Continuamos. En la siguiente ventana, se nos pedirá que especifiquemos la opción para escanear el disco. Le aconsejo que seleccione inmediatamente la primera opción "escanear y reparar" (escanear y restaurar). Simplemente ingrese el número "1" desde el teclado, como se muestra en la captura de pantalla.

Y en la última ventana antes del escaneo real de sectores defectuosos, se nos "pregunta" ¿desde qué sector comenzar a escanear? Te aconsejo que dejes el número "0". Esto asegurará que se escanee todo el disco.

Presione la tecla "Enter" y comience a buscar bloques defectuosos. Veremos todo el proceso usando el ejemplo de un disco que contiene sectores defectuosos. Preste atención a la captura de pantalla a continuación, en ella vemos el progreso del escaneo ( raya blanca) y en él: tres sectores defectuosos encontrados por el programa.

Analicemos esta captura de pantalla con más detalle: en la parte superior derecha, vemos el tiempo transcurrido desde el inicio del escaneo de bloques defectuosos y el tiempo restante hasta que se completa el proceso. Cuando se encuentran sectores defectuosos en el disco, el programa los marca con la letra "B" en inglés e inmediatamente intenta "curarlos". Si tiene éxito, aparece la letra "R" en lugar de la letra "B", lo que indica la "recuperación" exitosa del bloque defectuoso. En la esquina inferior izquierda, vemos estadísticas sobre los megabytes escaneados, así como el número de sectores defectuosos "B" y "R" "curados".
Al finalizar el escaneo, veremos la siguiente ventana:

Los tres sectores defectuosos encontrados por el programa se indican aquí, ya la derecha, las estadísticas que ya nos son familiares, que dicen que todos los bloques defectuosos encontrados han sido eliminados.
También tenga en cuenta el hecho de que si se detectan sectores defectuosos, es muy recomendable (inmediatamente o después de unos días) comenzar de nuevo el procedimiento de verificación. El hecho es que (con un defecto grave en el disco) pueden reaparecer bloques defectuosos y su número solo puede aumentar.

Esto es exactamente lo que nos "dicen" las siguientes inscripciones en la captura de pantalla anterior: "aparecen 4 nuevos sectores defectuosos" y "aparecen 18 sectores defectuosos" estas son las áreas defectuosas que reaparecieron en el disco duro y se detectaron durante el nuevo escaneo. Tal disco aún puede usarse con mucho éxito durante algún tiempo como uno adicional y puede almacenar información variada (no muy necesaria) y archivos temporales en él. Pero así es como un medio de almacenamiento confiable o... disco del sistema seguro que no nos conviene!
En realidad, le describí todo el proceso de prueba simple :) La lógica misma de lo que sucede "detrás de escena" del trabajo de cualquier programa para restaurar sectores defectuosos, la analizamos en el artículo anterior, que se llama "".
Además de lo dicho, me gustaría señalar uno más muy característica útil programas " Regenerador de disco duro". ella puede grabarla imagen de arranque a un disco compacto.
¿Por qué es necesario? Imagine una situación: tiene problemas con su disco duro (¡Dios no lo quiera! :)) y el sistema operativo simplemente no arranca debido a esto. ¿Cómo ejecutamos nuestro programa para que busque sectores defectuosos del disco duro? En este caso, la función de crear una versión de arranque del programa viene en nuestra ayuda.
Exploremos esta posibilidad. Al principio, después de iniciar el programa, en el menú "regeneración", seleccione el elemento "crear CD / DVD de arranque" (crear un CD o DVD de arranque).

En la siguiente ventana, seleccione nuestro dispositivo de grabación instalado en el sistema.

Presione el botón "Aceptar", inserte un disco en blanco en el dispositivo y vaya a la última ventana justo antes de grabar el disco. Aquí se nos ofrece elegir la velocidad de grabación. Seleccione y presione el botón "Grabar CD" (grabar un CD).
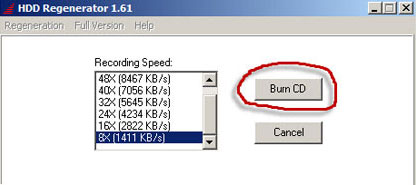
Después del final de la grabación, tomamos nuestro (ahora disco de arranque) con el programa HDD Regrenerator, lo insertamos en la computadora en la que queremos verificar si hay sectores defectuosos. Lo configuramos para que arranque desde CD y vemos un menú en el que el programa nos muestra los discos duros del ordenador que ha encontrado.

Como puede ver, tenemos dos de ellos. Seleccionamos (por ejemplo) la segunda (introducimos el número "2" del teclado) y pulsamos "enter". A continuación, vemos la siguiente ventana.

Tiene varias opciones para escanear el disco duro en busca de sectores defectuosos:
Introduce el número "2" del teclado (selecciona la segunda opción). Vemos tal ventana.

Aquí indicamos que escanearemos inmediatamente con la restauración de sectores defectuosos. Presionamos el número "1", luego - "ingresar" y luego comenzará el proceso de prueba que ya nos es familiar.
También tenga en cuenta el siguiente punto: la fuente de alimentación de mala calidad (fallas causadas) o el uso de varios adaptadores puede hacer que el programa de recuperación señale la detección de una gran cantidad de sectores defectuosos.
Hubo tales casos en mi práctica. El disco duro SATA se conectó a través de un adaptador molex a sata:

El programa de diagnóstico encontró muchos bloques defectuosos, pero tan pronto como instalamos el apropiado (que tenía conectores de alimentación Sata), el problema desapareció. Así que recuerda firmemente: cualquier adaptador es un mal necesario y, si puedes prescindir de él, ¡deshazte de él inmediatamente!
Eso es todo lo que quería contarles hoy sobre cómo encontrar y reparar sectores defectuosos en un disco. Al final del artículo, según lo acordado, doy un enlace al programa en sí "". Descargar, usar.
HDAT2 es una utilidad de servicio que le permite identificar y "curar" sectores defectuosos disco duro(están malo-sectores). "Curar" significa "reemplazar" los sectores defectuosos por otros sanos del área de reserva del disco duro.
Presione Entrar.
Escriba en línea hdat2 y presione Entrar:

Use las flechas hacia arriba y hacia abajo del teclado para seleccionar el disco en el que desea verificar si hay sectores defectuosos (sectores MALOS, conocidos popularmente como "malos") y presione Entrar:
Seleccione el menú de prueba del dispositivo y presione Entrar: (aquí es donde ingresa al menú de prueba del dispositivo)
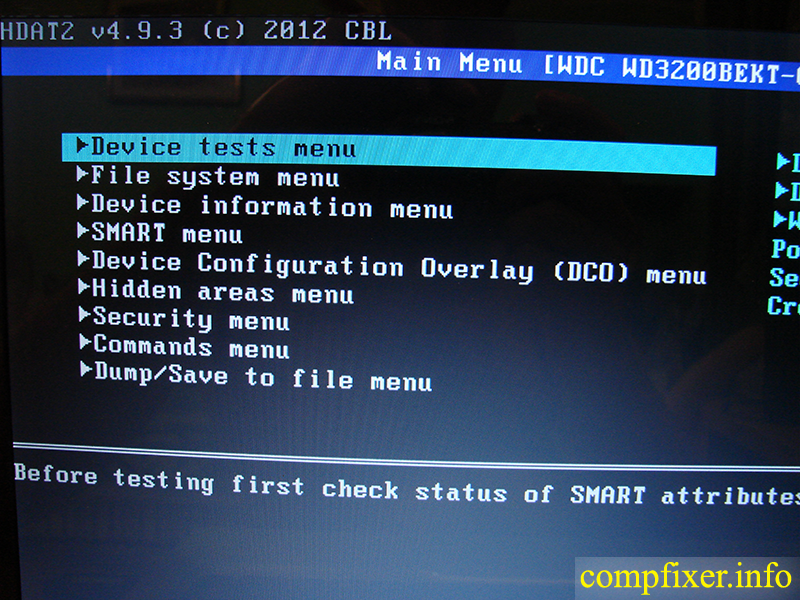
Si desea que el programa encuentre e intente "curar" (reemplazar) los sectores defectuosos, seleccione Detectar y corregir… (Adecuado si la garantía de disco duro Caducado)
Si desea que el programa simplemente le informe sobre la presencia o ausencia de sectores MALOS, pero no los corrija, seleccione Menú Detectar sectores defectuosos.
¡Importante! Realmente necesitará esta opción si desea asegurarse de que haya "malos" y presentar un reclamo al vendedor sin curarlos. Debe dejar los "malos" como están, de modo que esto le sirva como argumento cuando solicite un disco duro de reemplazo.

Si ha elegido "tratar" los sectores defectuosos, verá el siguiente menú. Se recomienda seleccionar el primer elemento en él.

Después de presionar la tecla Enter, se iniciará una prueba de disco. Puede durar varias horas, dependiendo de su capacidad y el método de "tratamiento" de "malos".
Diré esto: en la mitad de los casos, los sectores defectuosos aparecen en la cantidad de 1-3 piezas y después de la "curación" por el programa HDAT2 no se hacen sentir. Continúas usando el disco duro y todo está bien.
Si, después de curar los "malos", aparecen nuevos de forma regular y sistemática, esto significa que el disco se está "pelando". En este caso, recomiendo comprar un reemplazo lo antes posible, de lo contrario, tarde o temprano perderá toda la información.
¡Atención! Si inició el programa a través de " Menú Detectar sectores defectuosos", y programa encontrado Malos sectores, y decidiste curarlos, tendrás que reiniciar el programa nuevamente a través de " Menú Detectar y corregir sectores defectuosos» > « Arreglar con Verificar/Escribir/Verificar»
Se comprueba un disco duro de 640 GB durante aproximadamente 1 hora y 50 minutos
Tomará aproximadamente 6 horas verificar un disco duro de 2 TB
| Artículos relacionados: | |
|
¡Complemento de Akismet para proteger wordpress del spam!
Tiempo de lectura: 7 min Akismet es uno de los plugins que debería... Qué dominio está mejor indexado por los motores de búsqueda
Los principales motores de búsqueda de Internet de habla rusa son Yandex ... Anclajes - crear marcadores Anclar otra página
Un ancla es un marcador con un nombre único en una ubicación específica... | |




