Leserwahl





Populäre Artikel
Yandex.Disk ist einer der wenigen Yandex-Dienste, die Desktop-Software enthalten. Und eine seiner wichtigsten Komponenten ist der Algorithmus zum Synchronisieren lokaler Dateien mit ihrer Kopie in der Cloud. Wir mussten es vor kurzem komplett ändern. Konnte die alte Version selbst mehrere zehntausend Dateien kaum verdauen und reagierte zudem nicht schnell genug auf manche "komplexe" Benutzeraktionen, so kommt die neue mit den gleichen Ressourcen mit hunderttausenden Dateien zurecht.
In diesem Beitrag erzähle ich Ihnen, warum es passiert ist: Was wir nicht vorhersehen konnten, als wir die erste Version der Yandex.Disk-Software entwickelt haben, und wie wir eine neue erstellt haben.
Zunächst zur eigentlichen Aufgabe der Synchronisation. Technisch gesehen besteht es darin, den gleichen Satz von Dateien im Yandex.Disk-Ordner auf dem Computer des Benutzers und in der Cloud zu speichern. Das heißt, Benutzeraktionen wie Umbenennen, Löschen, Kopieren, Hinzufügen und Ändern von Dateien sollten automatisch mit der Cloud synchronisiert werden.
Noch komplizierter kann die Situation werden, wenn mehrere Benutzer gleichzeitig mit demselben Konto arbeiten oder einen freigegebenen Ordner haben. Und dies geschieht häufig in Organisationen, die Yandex.Disk verwenden. Stellen Sie sich vor, dass im vorherigen Beispiel in dem Moment, in dem wir vom Backend eine Bestätigung für die erste Umbenennung erhalten haben, ein anderer Benutzer diesen Ordner übernimmt und umbenennt. Auch in diesem Fall können Sie die Aktionen, die der erste Benutzer bereits auf seinem Computer ausgeführt hat, nicht sofort ausführen. Der Ordner, in dem er lokal gearbeitet hat, wird zu diesem Zeitpunkt im Backend bereits anders aufgerufen.
Es kann vorkommen, dass eine Datei auf dem Computer eines Benutzers nicht denselben Namen wie in der Cloud haben kann. Dies kann passieren, wenn der Name ein Zeichen enthält, das vom lokalen Dateisystem nicht verwendet werden kann, oder wenn der Benutzer in einen freigegebenen Ordner eingeladen wird und einen eigenen Ordner mit diesem Namen hat. In solchen Fällen müssen wir lokale Aliase verwenden und ihre Beziehung zu Objekten in der Cloud verfolgen.
In dieser Version des Algorithmus haben wir drei Hauptbäume verwendet: lokal (Local Index), Cloud (Remote Index) und zuletzt synchronisiert (Stable Index). Außerdem wurden zwei weitere Hilfsbäume verwendet, um die Neugenerierung von bereits in der Warteschlange befindlichen Synchronisationsoperationen zu verhindern: Erwarteter entfernter Index und erwarteter lokaler Index. Diese Hilfsbäume speicherten den erwarteten Zustand des lokalen Dateisystems und der Cloud, nachdem alle bereits in die Warteschlange gestellten Synchronisationsvorgänge ausgeführt wurden.
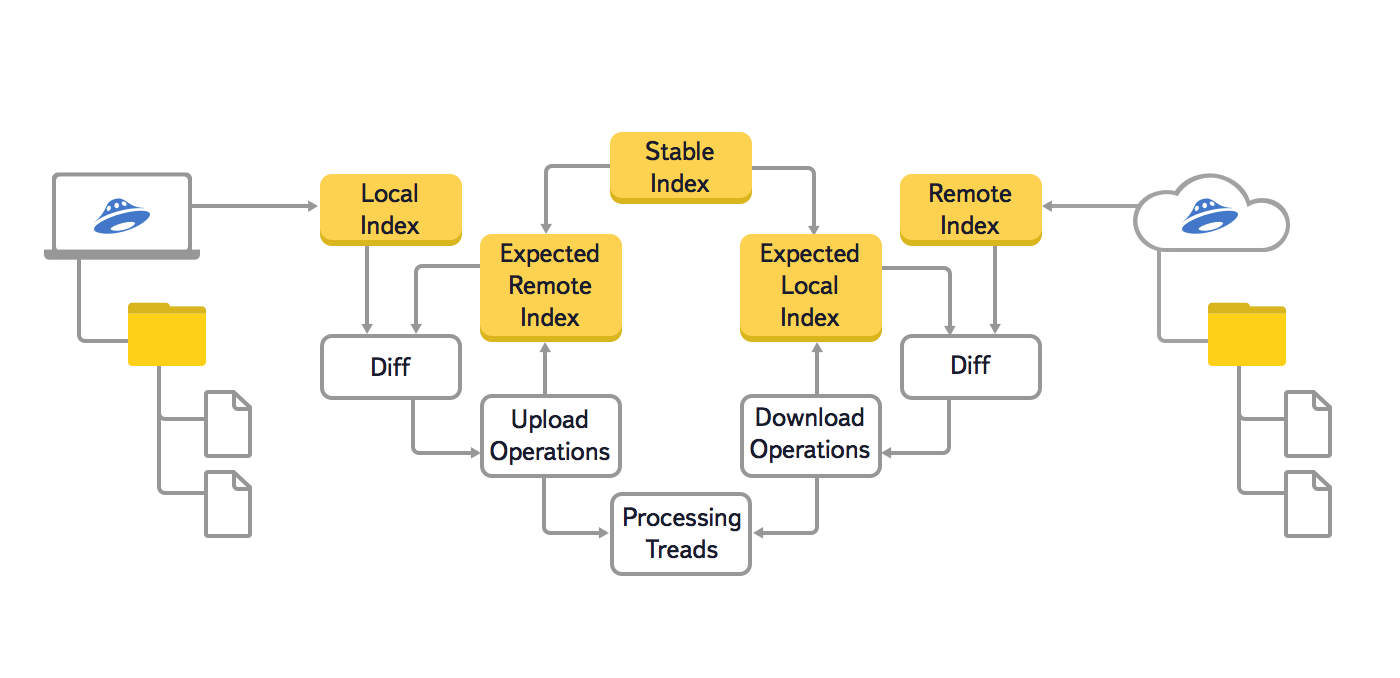
Wir wollten auch die maximale Anzahl von Dateien erhöhen, mit denen ein Benutzer problemlos arbeiten kann. Mehrere Zehntausend oder sogar Hunderttausende von Dateien können beispielsweise ein Fotograf sein, der die Ergebnisse von Fotosessions in Yandex.Disk speichert. Diese Aufgabe wurde besonders dringend, als die Leute die Möglichkeit bekamen, zusätzlichen Speicherplatz auf Yandex.Disk zu kaufen.
In der Entwicklung wollte ich auch etwas ändern. Das Debuggen der alten Version war schwierig, da sich die Zustandsdaten eines Elements in verschiedenen Bäumen befanden.
Zu diesem Zeitpunkt erschien im Backend eine ID von Objekten, mit deren Hilfe das Problem der Bewegungserkennung effizienter gelöst werden konnte - früher haben wir Pfade verwendet.
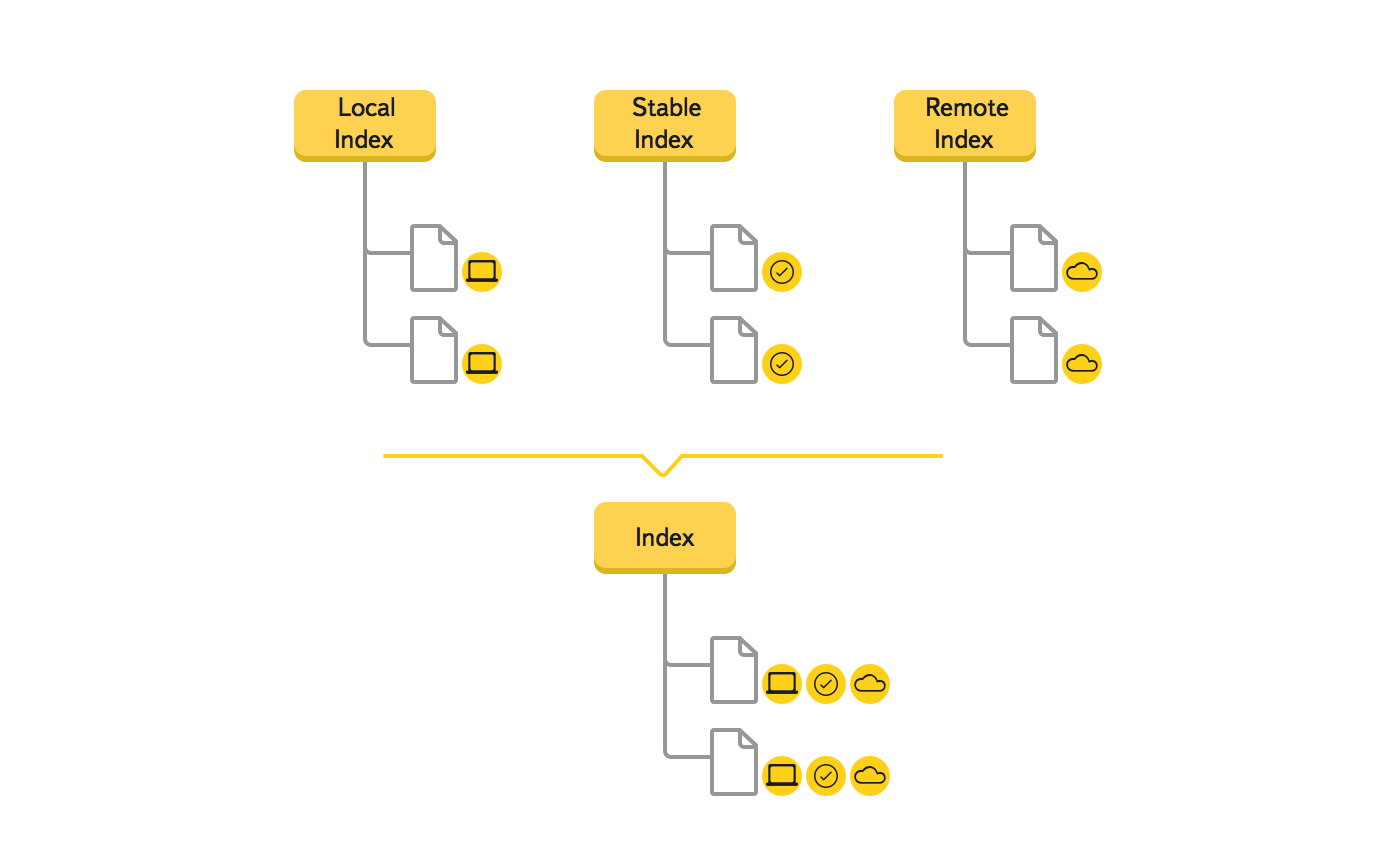
Da wir verstanden haben, dass dies eine große Änderung war, haben wir einen Prototyp erstellt, der die Wirksamkeit der neuen Lösung bestätigt. Sehen wir uns ein Beispiel an, wie sich die Daten im Baum während der Synchronisierung einer neuen Datei ändern.

Yandex.Disk verwendet sha256- und MD5-Digests, um die Dateiintegrität zu überprüfen, geänderte Fragmente zu erkennen und Dateien im Backend zu deduplizieren. Da diese Aufgabe die CPU stark belastet, wurde in der neuen Version die Umsetzung von Digest-Berechnungen deutlich optimiert. Die Geschwindigkeit beim Empfangen eines Dateiauszugs wird ungefähr verdoppelt.
Durch die vorgenommenen Änderungen hat sich die Anzahl der Dateien, die das Programm verarbeiten kann, deutlich erhöht. Die Windows-Version hat 300.000 Dateien und die Mac OS X-Version 900.000 Dateien.
Es ist kein Geheimnis, warum Sie ein Backup benötigen. Zum Beispiel ist es für einen Webentwickler praktisch, Backups zu erstellen, wenn er während des Entwicklungsprozesses unbemerkt einen Fehler macht und nach ein paar Stunden der Fehler "auftaucht" und es absolut keine Zeit mehr gibt um den Fehler zu finden und zu beheben. Natürlich verfügt Vscale über ein Backup-System, das jedoch nur das Kopieren der Daten des gesamten Servers als Ganzes vorsieht. Und die Möglichkeit, aus einer Sicherung wiederherzustellen, ist nur auf dem Server verfügbar, von dem die Kopie erstellt wurde. Diese Fähigkeit erfüllt die Anforderungen eines bedingten Webentwicklers nicht ganz. Inzwischen hat die Welt jedoch einen gut entwickelten "Cloud"-Trend: Cloud-Hosting, Cloud-VPS, Cloud-Speicher und so weiter. In dieser Anleitung zeigen wir Ihnen, wie Sie einen Cloud-Backup-Speicher einrichten. Yandex.Disk wird uns dabei helfen.
Beginnen wir mit der Installation der Schlüsselkomponente - des Clients für Ya.Disk. Da es kein Paket mit dem Ya.Disk-Client in der Standardliste der Repositorys gibt, müssen Sie das Repository manuell hinzufügen, dann den Paketindex aktualisieren und erst dann das Paket mit dem Client installieren. Die Ya.Disk-Website enthält eine Liste der erforderlichen Befehle in einer Zeile:
Echo "deb http://repo.yandex.ru/yandex-disk/deb/stable main"| sudo tee -a /etc/apt/sources.list .d / yandex.list> / dev / null && wget http: //repo.yandex.ru/yandex-disk/YANDEX-DISK-KEY.GPG -O- | sudo apt-key add - && sudo apt-get update && sudo apt-get install -y yandex-diskDer Yandex-Client wurde erfolgreich installiert und Sie können mit der Konfiguration beginnen. Yandex stellte sicher, dass der Client auf ein Minimum mit Konfigurationsdateien arbeitete und fügte die Möglichkeit hinzu, alles mit einem Befehl zu konfigurieren:
Yandex-Festplatten-Setup
Die Arbeitsreihenfolge des obigen Befehls:
Autostart Ya.Disk unbedingt einschalten, und Sie können die restlichen Elemente nach Belieben anpassen. An dieser Stelle kann die Einstellung als abgeschlossen betrachtet werden.
Es gibt viele Befehle, mit denen Sie ein Backup erstellen können. Python oder Perl können dabei helfen, aber es ist am bequemsten, dies mit bash zu tun. Es ist einfach und leicht zu bedienen und interagiert direkt mit der Konsole. Erstellen Sie ein Bash-Skript:
Nano /var/backup.sh
Fügen Sie den folgenden Code darin ein:
SERVER_PATH = "/var/www/html"
cur_date = `Datum +% Y-% m-% d`
filename = "backup -" $ cur_date ".tar.bz2"
tar -cjf $ Dateiname $ SERVER_PATH
if [-f $ Dateiname]; dann
mv $ Dateiname /root/Yandex.Disk/backup/
Yandex-Festplattensynchronisierung
fi
Speichern Sie die Datei mit der Tastenkombination Strg + Aus, bestätigen Sie die Aktion mit der Taste Eintreten und schließe die Datei mit der Tastenkombination Strg + X... Stellen Sie sicher, dass Sie der Datei Berechtigungen zuweisen, damit sie Zugriff auf Systembefehle hat (Ordner erstellen und verschieben, auf Verzeichnisse zugreifen):
CD / Var
chmod -R 755 * backup.sh
Kurz darüber, was das Skript macht:
Sie können mit dem folgenden Befehl überprüfen, ob das Skript funktioniert:
Cd / var && ./backup.sh
Als Ergebnis der Ausführung des Befehls wird das Archiv in den Cloud-Speicher hochgeladen.
Der nächste und letzte Schritt besteht darin, das Skript zum Aufgabenplaner hinzuzufügen. Wird uns mit dieser crontab helfen. Öffnen Sie die Liste der geplanten Aufgaben:
Crontab -e
Fügen Sie ganz am Ende die Zeile hinzu:
0 0 * * * /var/backup.sh
Jetzt führt Crontab das Skript jeden Tag um Mitternacht aus. Damit ist die Konfiguration der automatischen Sicherung abgeschlossen.
Sie haben erfolgreich eine automatische Sicherung Ihres Website-Verzeichnisses eingerichtet. Dies ist ein sehr nützlicher Algorithmus, um zu vermeiden, dass ein Backup verloren geht, wenn es auf dem Server selbst gespeichert wurde. Nach dem gleichen Prinzip können Sie Sicherungskopien von Konfigurationsdateien erstellen. Im Allgemeinen sind Cloud-Technologien gut, weil sie eine hohe Verfügbarkeit und Sicherheit der Speicherung personenbezogener Daten bieten. Die Wahl der Cloud ist eine gute Wahl.
Möglicherweise müssen Sie aus verschiedenen Gründen Backups von Projekten (Sites) auf Yandex.Disk hochladen, zum Beispiel aus Platzmangel auf dem Server (Hosting, VDS, VPS) oder um die Sicherheit beim Speichern von Backups zu erhöhen (falls der Server ist ohne Raid und verlässt das Gebäude).
In dieser Hinsicht habe ich für mich selbst geschrieben und beschlossen, für andere ein kleines Bash-Skript zur Sicherung auf Yandex.Disk zu veröffentlichen. Skriptfunktionen:
- Erstellung von Backup-Projekten auf dem Server (Dateien + MySQL-Datenbanken);
- Autorisierung auf Yandex.Disk als Anwendung (mit einem Token, ein sichererer Weg als die Verwendung eines Benutzernamens und eines Passworts);
- Senden von Backups vom Server an Yandex.Disk;
- Entfernen alter Backups von Yandex.Disk, um Platz zu sparen (konfigurierbare maximale Anzahl gespeicherter Backups);
- Aufzeichnen und Senden eines Protokolls an E-Mail (konfigurierbar).
Um das Skript verwenden zu können, müssen Sie zunächst ein Token von Yandex.Disk abrufen. Lass uns anfangen.
1. Melden Sie sich bei Yandex unter dem Konto an, auf dem wir ein Backup erstellen möchten, gehen Sie zu oauth.yandex.ru und klicken Sie auf "Neue Anwendung registrieren".
2. Geben Sie den Anwendungsnamen ein (z. B. "Backup") und erteilen Sie die erforderlichen Rechte im Abschnitt "Yandex.Disk REST API", nämlich: "Zugriff auf Informationen über die Festplatte" und "Zugriff auf den Anwendungsordner auf Scheibe".
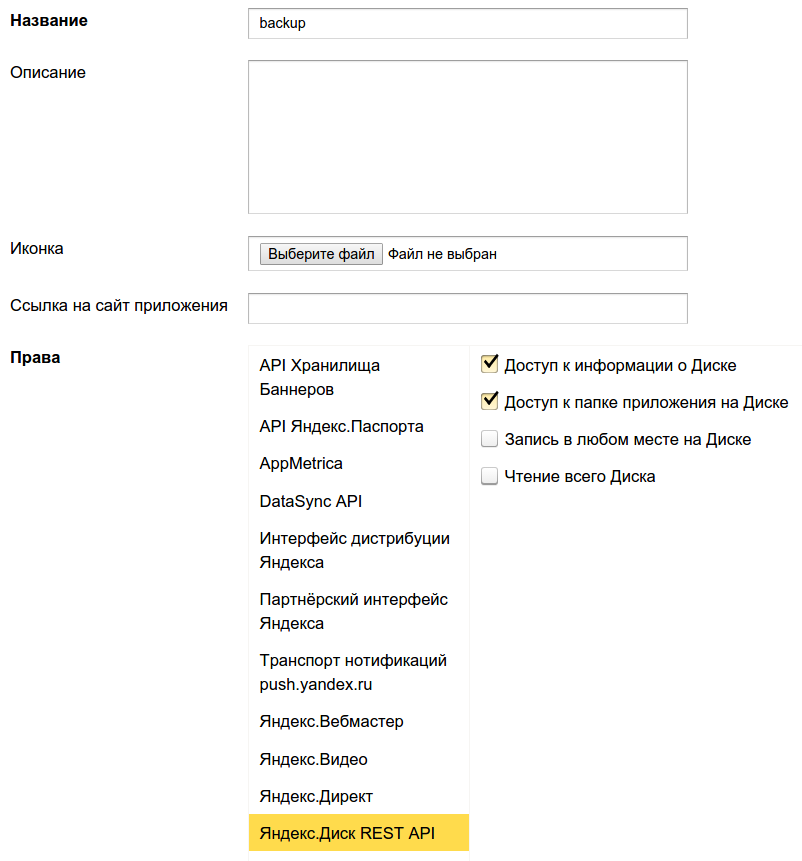
Unten auf derselben Seite unter dem Feld "Callback URL" klicken Sie auf "URL für Entwicklung einreichen" und klicken Sie auf "Speichern":

3. Nach dem Speichern der Bewerbungseinstellungen werden wir auf die Seite mit den Bewerbungsdaten weitergeleitet:
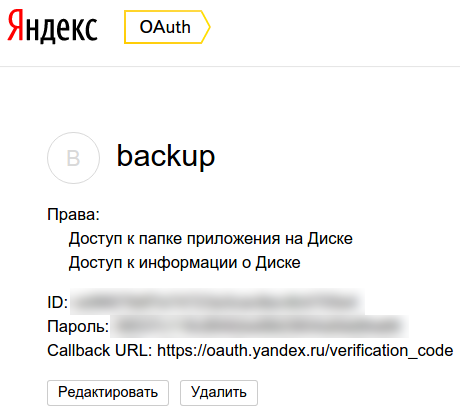
4. Jetzt erhalten wir den Token selbst (wenn Sie möchten, können Sie mehr dazu im Yandex-Handbuch lesen), dafür kopieren wir die ID und ersetzen sie am Ende der URL https://oauth.yandex.ru/ authorize?response_type=token&client_id=, gehen Sie zu der resultierenden Adresse und bestätigen Sie die Erteilung von Berechtigungen für die Anwendung:
![]()
Als Ergebnis wird auf der Seite ein Token angezeigt, der für mindestens 1 Jahr ausgestellt wird. Wenn das Backup-Skript also plötzlich nicht mehr funktioniert, können wir ein neues Token besorgen und es in das Skript einfügen. Sie können die Fähigkeiten der Arbeit mit Yandex.Disk mit dem erhaltenen Token auf einem speziellen Testgelände testen.
Und jetzt das Bash-Skript selbst für ein Backup auf Yandex.Disk:
#! / bin / bash # # Yandex.Disk Backup-Skript v1.0 von Sergey Lukonin (neblog.info) # # # # # # # # # # # SICHERUNGSEINSTELLUNGEN MYSQL # # # # # # # # # # # Server DB MYSQL_SERVER = mysql.some-server.ru # Der Benutzer, unter dem wir die verfügbaren Datenbanken sichern, das MySQL-Root ist normalerweise für alle Datenbanken zugänglich, der einzelne Benutzer hat normalerweise Zugriff auf die Datenbank eines bestimmten Projekts MYSQL_USER = some-user # Datenbankbenutzerpasswort (Passwort vom Server-Root und verwechseln Sie nicht verschiedene von mysql-root) MYSQL_PASSWORD = some-password # # # # # # # # # # ALLGEMEINE EINSTELLUNGEN # # # # # # # # # # # Verzeichnis zur temporären Speicherung von Backups, die nach dem Senden an Yandex gelöscht werden .. Festplatten-Backups (0 - alle Backups behalten): MAX_BACKUPS = "14" # Datum, das in Archivnamen verwendet wird DATE = `date" +% Y-% m-% d " ` # Verzeichnisse für die Archivierung (durch ein Leerzeichen getrennt), die in einem einzigen Archiv abgelegt und an Yandex.Disk gesendet werden DIRS = "/home/www/projects/neblog" # Yandex.Disk-Token (siehe neblog.info für wie um es zu bekommen) TOKEN = "" # Der Name der Log-Datei, gespeichert in deer das in $ BACKUP_DIR LOGFILE = "backup.log" angegebene Verzeichnis # E-Mail, um das Ergebnis der Skriptausführung zu senden. Lassen Sie dieses Feld leer, wenn Sie keine Ergebnisse übermitteln möchten. sendLog = " [E-Mail geschützt] "# Nur Fehler senden (true). Geben Sie false an, wenn Sie Protokolle für alle Ergebnisse der Skriptausführung senden möchten. SendLogErrorsOnly =" false "# # # # # # # # # # ENDE DER EINSTELLUNGEN # # # # # # # # # # # # # # # # # # # # # NICHTS ÄNDERN! # # # # # # # # # # Funktion mailing () (if [! $ SendLog = ""]; then if ["$ sendLogErrorsOnly " == true ]; then if echo "$ 1" | grep -q "error" then echo "$ 2" | mail -s "$ 1" $ sendLog> / dev / null fi else echo "$ 2" | mail -s "$ 1" $ sendLog> / dev / null fi fi) function logger () (echo "[" `date" +% Y-% m-% d% H:% M:% S "` "] File $ BACKUP_DIR: $ 1" >> $ BACKUP_DIR / $ LOGFILE) Funktion parseJson () (lokale Ausgabe regex = "(\" $ 1 \ ": [\"]?) ([^ \ ", \)] +) ( [\"]?) "[[$ 2 = ~ $ regex]] && Ausgabe = $ (BASH_REMATCH) Echo $ Ausgabe) Funktion checkError () (echo $ (parseJson "Fehler" "$ 1")) Funktion getUploadUrl () (json_out = `curl -s -H" Autorisierung: OAuth $ TOKEN "https: //cloud-api.yandex.net: 443 / v1 / disk / resources / upload /? Path = app: / $ backupName & overwrite = true `json _error = $ (checkError "$ json_out") if [[$ json_error! = ""]]; dann Logger "$ PROJECT - Yandex.Disk error: $ json_error" Mailing "$ PROJECT - Yandex.Disk Backup error" "ERROR copy file $ FILENAME. Yandex.Disk error: $ json_error" echo "" else output = $ (parseJson " href "$ json_out) echo $ output fi) Funktion uploadFile (local json_out local uploadUrl local json_error uploadUrl = $ (getUploadUrl) if [[$ uploadUrl! =" "]]; then echo $ UploadUrl json_out =` curl -s -T $ 1 -H "Authorization: OAuth $ TOKEN" $ uploadUrl` json_error = $ (checkError "$ json_out") if [[$ json_error! = ""]]; Then Logger "$ PROJECT - Yandex.Disk error: $ json_error" mailing " $ PROJECT - Yandex.Disk Backup-Fehler "" FEHLER Datei kopieren $ FILENAME. Yandex.Disk Fehler: $ json_error "else logger" $ PROJECT - Kopieren der Datei auf Yandex.Disk erfolgreich "Mailing" $ PROJECT - Yandex.Disk Backup erfolgreich " " SUCCESS Datei kopieren $ FILENAME "fi else echo" Es sind einige Fehler aufgetreten. Überprüfen Sie die Protokolldatei auf Details "fi) function backups_list () (# Suchen Sie nach allen Sicherungsdateien im Anwendungsverzeichnis und zeigen Sie ihre Namen an : curl -s -H "Autorisierung: OAuth $ TOKEN" "https://cloud-api.yandex.net:443/v1/disk/resources?path=app:/&sort=created&limit=100" | tr "()", "\ n" | grep "name [[: graph:]] *.tar.gz" | Schnitt -d: -f 2 | tr -d "" ") function backups_count () (local bkps = $ (backups_list | wc -l) # Wenn wir sowohl Dateien als auch die Datenbank sichern, dann haben wir 2 Dateien pro 1 Backup. Daher ist die Anzahl der Backups = die Anzahl der Dateien / 2: expr $ bkps / 2) Funktion remove_old_backups () (bkps = $ (backups_count) old_bkps = $ ((bkps - MAX_BACKUPS)) if ["$ old_bkps" -gt "0"]; then logger " Entfernen Sie alte Backups von Yandex ... Disk "# Zyklus zum Löschen alter Backups: # Löschen der ersten Datei in der Liste 2 * old_bkps mal für i in` eval echo (1 .. $ ((old_bkps * 2))) `; do curl -X DELETE -s - H" Autorisierung: OAuth $ TOKEN "" https://cloud-api.yandex.net:443/v1/disk/resources?path=app:/$(backups_list | awk "(NR == 1)") & dauerhaft = true " done fi) logger "--- $ PROJECT START BACKUP $ DATE ---" logger "Dumping database Dumps" mkdir $ BACKUP_DIR / $ DATE für i in `mysql -h $ MYSQL_SERVER -u $ MYSQL_USER -p $ MYSQL_PASSWORD -e" Datenbanken anzeigen; "| grep -v information_schema | grep -v Datenbank`; mysqldump ausführen -h $ MYSQL_SERVER -u $ MYSQL_USER -p $ MYSQL_PASSWORD $ i> $ BACKUP_DIR / $ DATE / $ i.sql; done logger" Erstellen Sie ein mysql-Archiv $ BACKUP_DIR / $ DATE-mysql- $ PROJECT.tar.gz "tar -czf $ BACKUP_DIR / $ DATE-mysql- $ PROJECT.tar.gz $ BACKUP_DIR / $ DATE rm -rf $ BACKUP_DIR / $ DATE logger " Erstellen Sie ein Verzeichnisarchiv $ BACKUP_DIR / $ DATE-files- $ PROJECT.tar.gz "tar -czf $ BACKUP_DIR / $ DATE-files- $ PROJECT.tar.gz $ DIRS FILENAME = $ DATE-mysql- $ PROJECT.tar .gz-Logger" Klicken Sie auf Yandex.Disk das mysql-Archiv $ BACKUP_DIR / $ DATE-mysql- $ PROJECT.tar.gz "backupName = $ DATE-mysql- $ PROJECT.tar.gz uploadFile $ BACKUP_DIR / $ DATE-mysql- $ PROJECT.tar. gz FILENAME = $ DATE-files- $ PROJECT.tar.gz Logger "Laden Sie das Archiv auf Yandex.Disk mit $ BACKUP_DIR / $ DATE-files- $ PROJECT.tar.gz" backupName = $ DATE-files- $ PROJECT.tar .gz uploadFile $ BACKUP_DIR / $ DATE-Dateien- $ PROJECT.tar.gz Logger "Archive von der Festplatte löschen" find $ BACKUP_DIR -type f -name "* .gz" -exec rm "()" \; # Entfernen Sie alte Backups von Yandex.Disk (wenn MAX_BACKUPS> 0), wenn [$ MAX_BACKUPS -gt 0]; then remove_old_backups; fi-Logger "Sicherungsskript beenden"
Sie können auch eine fertige Version herunterladen. Das Skript sollte sich auf dem Server befinden, die darin enthaltenen Parameter durch Ihre eigenen ersetzen, das Recht zum Ausführen geben (chmod + x) und es so einstellen, dass es täglich in cron ausgeführt wird. Wenn Sie mehrere solcher Aufgaben ausführen möchten, legen Sie die Zeit zwischen ihrem Start fest (5-10 Minuten).
In der modernen Welt gewinnen Informationen immer mehr an Wert, deren Verlust erhebliche finanzielle Kosten nach sich ziehen kann. Die Site enthält wertvolle Informationen, von denen wir in diesem Artikel eine Sicherungskopie oder nur eine Sicherungskopie am Beispiel von WordPress erstellen und auf eine Yandex-Disk legen. Ich werde die Möglichkeit in Betracht ziehen, den Prozess zu automatisieren, den ich für meine Bedürfnisse erdacht habe und seit langem erfolgreich einsetze.
Wir werden uns in Etappen bewegen. Betrachten wir zunächst nur die Option, die Site- und Datenbankdateien direkt zu sichern. Und dann werden wir die Frage vollständig beantworten, wie Sie ein regelmäßiges Backup Ihrer Website auf WordPress erstellen können.
Hier habe ich das Rad nicht neu erfunden, sondern die Standardmethode zum Archivieren von Dateien verwendet - einen Archiver Teer... Ich werde alle Kommentare und Erklärungen gleich in das Skript schreiben:
#! / bin / sh # Setze die Variablen # Aktuelles Datum im Format 2015-09-29_04-10 date_time = `date +"% Y-% m-% d_% H-% M "` # Wo wir das Backup platzieren bk_dir = "/ mnt / backup / site1.ru "# Verzeichnis eine Ebene höher als die, in der sich die Dateien befinden inf_dir =" / web / Sites / site1.ru / "# Der Name des direkten Verzeichnisses mit den Dateien dir_to_bk =" www "# Archiv erstellen / usr / bin / tar -czvf $ bk_dir / www_ $ date_time.tar.gz -C $ inf_dir $ dir_to_bk
Am Ausgang, nachdem das Skript ausgeführt wurde, haben wir einen Ordner namens www_2015-09-29_04-10.tar.gz, in dem sich ein www-Ordner mit allen Inhalten befindet. Ursprünglich befand sich dieser Ordner unter /web/sites/site1.ru/www. Hier habe ich tar mit dem Parameter angewendet -MIT damit das Archiv nicht den genauen Pfad /web/sites/site1.ru hat, sondern nur den www-Ordner. Für mich ist es einfach bequemer.
Sie können dieses Skript separat verwenden, um Dateiarchive zu erstellen, nicht unbedingt die Site. Wir haben es eingebaut cron und wir bekommen regelmäßige Archivierung.
Lassen Sie uns nun ein Skript für eine Datenbanksicherung erstellen. Auch hier nichts besonderes, ich verwende ein Standardwerkzeug mysqldamp:
#! / bin / sh # Setze die Variablen # Aktuelles Datum im Format 2015-09-29_04-10 date_time = `date +"% Y-% m-% d_% H-% M "` # Wo wir das Backup platzieren bk_dir = "/ mnt / backup / site1.ru "# Datenbankbenutzer Benutzer =" user1 "# Benutzerkennwort Passwort =" pass1 "# Datenbankname für die Sicherung bd_name =" bd1 "# Datenbank entladen / usr / bin / mysqldump -- opt -v - -databases $ bd_name -u $ user -p $ Passwort | /usr/bin/gzip -c> $ bk_dir / mysql_ $ date_time.sql.gz
Am Ausgang haben wir eine Datei mit einem Dump der mysql_2015-09-29_04-10.sql.gz Datenbank. Der Dump wird im Textformat gespeichert, Sie können jeden Editor öffnen und bearbeiten.
Es gibt einen ziemlich bequemen und kostenlosen Dienst Ya ndeks.Disk, den jeder verwenden kann. Es wird nicht viel Speicherplatz kostenlos zur Verfügung gestellt, aber es gibt genug, um eine Site auf WordPress zu sichern. 368 GB stehen mir übrigens mit Hilfe verschiedener Aktionen kostenlos zur Verfügung:
Ich bin ndeks.Disk kann mit webdav verbunden werden. Mein Server ist CentOS 7, ich werde Ihnen sagen, wie Sie ihn darin mounten. Als erstes verbinden wir uns. Dann installiere das Paket davfs2:
# yum -y installiere davfs2
Jetzt versuchen wir, die Festplatte zu mounten:
# mkdir / mnt / yadisk # mount -t davfs https://webdav.yandex.ru / mnt / yadisk / Bitte geben Sie den Benutzernamen ein, um sich beim Server https://webdav.yandex.ru zu authentifizieren, oder drücken Sie die Eingabetaste für keine. Benutzername: Bitte geben Sie das Passwort ein, um den Benutzer zu authentifizieren [E-Mail geschützt] mit dem Server https://webdav.yandex.ru oder drücken Sie die Eingabetaste für keine. Passwort: /sbin/mount.davfs: Warnung: kann "kein Eintrag in mtab schreiben, wird aber trotzdem das Dateisystem mounten
Ich bin index Die Diskette ist im Ordner /mnt/yadisk eingehängt.
Um den Archivierungsprozess zu automatisieren und nicht jedes Mal den Benutzernamen und das Passwort einzugeben, bearbeiten Sie die Datei /etc/davfs2/secrets, indem Sie am Ende eine neue Zeile mit dem Benutzernamen und dem Passwort hinzufügen:
# mcedit / etc / davfs2 / secrets / mnt / yadisk / [E-Mail geschützt] Passwort
Jetzt werden beim Mounten der Festplatte keine Fragen mehr gestellt. Sie können eine Yandex-Festplattenverbindung hinzufügen zu fstab damit es beim Booten automatisch gemountet wird, aber ich finde es überflüssig. Ich verbinde und trenne das Laufwerk im Backup-Skript. Wenn Sie es automatisch mounten möchten, fügen Sie zu fstab hinzu:
Https://webdav.yandex.ru / mnt / yadisk davfs rw, Benutzer, _netdev 0 0
Unabhängig davon haben wir alle Elemente zum Erstellen einer Sicherungskopie der Website zerlegt. Jetzt ist es an der Zeit, all dies an einem Ort zu sammeln. Ich verwende das folgende Site-Backup-Schema:
Mit einem solchen Schema haben wir für alle Fälle immer die 7 neuesten Archive, Wochenarchive des aktuellen Monats und ein Archiv für jeden Monat zur Hand. Ein paar Mal hat mir dieses Schema geholfen, als ich zum Beispiel vor einer Woche etwas aus einem Backup holen musste.
Hier sind 3 vollständige Skripte zum Erstellen einer Sicherungskopie einer WordPress-Site. Dies ist die Engine, die ich am häufigsten verwende, aber in Wirklichkeit können Sie jede Site sichern - Joomla, Drupal, Modx usw. Cms oder ein Framework sind nicht von grundlegender Bedeutung .
Skript für tägliches Website-Backup backup-day.sh:
Tag"# Verzeichnis für das Archiv inf_dir =" / web / Sites / site1.ru / "# Der Name des direkten Verzeichnisses mit Dateien dir_to_bk =" www "# Datenbankbenutzer Benutzer =" user1 "# Benutzerpasswort Passwort =" pass1 "# Datenbankname für Backup bd_name = "bd1" # Yandex.disk mounten mount -t davfs https://webdav.yandex.ru / mnt / yadisk / # Quellarchiv erstellen / usr / bin / tar -czvf $ bk_dir / www_ $ date_time.tar.gz -C $ inf_dir $ dir_to_bk # Dump der Datenbank /usr/bin/mysqldump --opt -v --databases $ bd_name -u $ user -p $ Passwort | /usr/bin /gzip -c> $ bk_dir / mysql_ $ date_time.sql.gz # Archive älter als 7 Tage löschen / usr / bin / find $ bk_dir -type f - Zeit +7
Wöchentliches Site-Backup-Skript backup-week.sh:
#! / bin / sh # Setze die Variablen # Aktuelles Datum im Format 2015-09-29_04-10 date_time = `date +"% Y-% m-% d_% H-% M "` # Wo wir das Backup platzieren bk_dir = "/ mnt / yadisk / site1.ru / Woche"# Verzeichnis für das Archiv inf_dir =" / web / Sites / site1.ru / "# Der Name des direkten Verzeichnisses mit Dateien dir_to_bk =" www "# Datenbankbenutzer Benutzer =" user1 "# Benutzerpasswort Passwort =" pass1 "# Datenbankname für Backup bd_name = "bd1" # Mount Yandex.disk mount -t davfs https://webdav.yandex.ru / mnt / yadisk / # Erstellen Sie ein Quellarchiv / usr / bin / tar -czvf $ bk_dir / www_ $ date_time.tar.gz -C $ inf_dir $ dir_to_bk # Dump der Datenbank /usr/bin/mysqldump --opt -v --databases $ bd_name -u $ user -p $ Passwort | /usr/bin /gzip -c> $ bk_dir / mysql_ $ date_time.sql.gz # Archive älter als 30 Tage löschen / usr / bin / find $ bk_dir -type f -mZeit +30-exec rm() \; # Yandex.Disk deaktivieren umount / mnt / yadisk
Monatliches Website-Backup-Skript Backup-Monat.sh:
#! / bin / sh # Setze die Variablen # Aktuelles Datum im Format 2015-09-29_04-10 date_time = `date +"% Y-% m-% d_% H-% M "` # Wo wir das Backup platzieren bk_dir = "/ mnt / yadisk / site1.ru / Monat"# Verzeichnis für das Archiv inf_dir =" / web / Sites / site1.ru / "# Der Name des direkten Verzeichnisses mit Dateien dir_to_bk =" www "# Datenbankbenutzer Benutzer =" user1 "# Benutzerpasswort Passwort =" pass1 "# Datenbankname für Backup bd_name = "bd1" # Mount Yandex.disk mount -t davfs https://webdav.yandex.ru / mnt / yadisk / # Erstellen Sie ein Quellarchiv / usr / bin / tar -czvf $ bk_dir / www_ $ date_time.tar.gz -C $ inf_dir $ dir_to_bk # Dump der Datenbank /usr/bin/mysqldump --opt -v --databases $ bd_name -u $ user -p $ Passwort | /usr/bin /gzip -c> $ bk_dir / mysql_ $ date_time.sql.gz # Yandex.Disk deaktivieren umount / mnt / yadisk
Vergessen Sie nicht, ein Verzeichnis /mnt/yadisk/site1.ru . zu erstellen auf einer Yandex-Festplatte, und darin befinden sich 3 weitere Ordner: Tag, Woche, Monat:# cd /mnt/yadisk/site1.ru && mkdir Tag Woche Monat
Fügen Sie nun zur Automatisierung diese 3 Dateien zu . hinzu cron:
# mcedit / etc / crontab # Site-Backup auf yandex.disk # täglich um 4:10 Uhr 10 4 * * * root /root/bin/backup-day.sh> / dev / null 2> & 1 # wöchentlich um 4: 20 Uhr Sonntag 20 4 * * 0 root /root/bin/backup-week.sh> / dev / null 2> & 1 # monatlich um 4:30 am 1. des Monats 30 4 1 * * root / root / bin / Backup-Monat .sh> / dev / null 2> & 1
Das war's, unser WordPress wird zuverlässig gesichert. Theoretisch müssen Sie hier eine Benachrichtigung an die E-Mail anhängen, aber ich habe keine Zeit dafür. Und seit mehreren Monaten im Einsatz hatte ich keinen einzigen Ausfall.
Betrachten wir nun die Option, wenn Sie eine Site aus einem Backup wiederherstellen müssen. Dazu benötigen wir beide Archive: Quellen und eine Datenbank. Im Prinzip können Sie es überall entpacken. In Windows werden Archive mit dem kostenlosen 7zip-Archiver geöffnet. Datenbank-Dump im Nur-Text-Format, kann mit Notepad geöffnet, kopiert und in phpmyadmin eingefügt werden.

Es kann also viele Wiederherstellungsoptionen geben, das ist es, was ich an diesem Ansatz mag. Alle Dateien liegen in offener Form vor, Sie können mit ihnen mit allen Mitteln arbeiten.
Hier ist ein Beispiel für das Extrahieren von Dateien aus einem Archiv in der Serverkonsole. Entpacken Sie das www-Verzeichnis aus dem Backup:
# tar -xzvf www_2015-10-01_04-10.tar.gz
Die Dateien werden in den Ordner www extrahiert. Jetzt können sie in den Site-Ordner kopiert werden.
Um die Datenbank wiederherzustellen, gehen wir wie folgt vor. Entpacken Sie zuerst das Archiv:
# gunzip mysql_2015-10-01_04-10.sql.gz
Jetzt füllen wir den Dump in die Datenbank aus:
# mysql --host = localhost --user = user1 --password = pass1 bd1; MariaDB [(keine)]> Quelle mysql_2015-10-01_04-10.sql;
Das war's, die Datenbank wurde wiederhergestellt.
Bitte beachten Sie, dass die Datenbank in der Datenbank mit dem ursprünglichen Namen wiederhergestellt wird und ihren Inhalt ersetzt, falls einer auf dem Server vorhanden ist. Um eine Datenbank in eine andere wiederherzustellen, müssen Sie den Anfang des Dumps bearbeiten und den Namen der Datenbank dort durch einen neuen ersetzen. Wenn die Wiederherstellung auf einem anderen Server stattfindet, spielt es keine Rolle.
Also haben wir die Möglichkeiten zum Erstellen von Site- und Datenbank-Backups am Beispiel der WordPress-Engine untersucht. In diesem Fall wurden nur Standard-Servertools verwendet. Als Beispiel haben wir einen Empfänger verwendet, um Kopien von Index.Disk zu speichern, aber nichts hindert uns daran, es an andere anzupassen. Dies kann eine separate Festplatte oder ein externes Laufwerk sein, ein weiterer Cloud-Speicher, der auf dem Server bereitgestellt werden kann.
Das Schema zum Erstellen eines Backups ermöglicht Ihnen ein fast unbegrenztes Rollback. Sie können die Tiefe der Archive selbst einstellen, indem Sie den Parameter ändern mtime im Skript. Sie können zum Beispiel ein Tagesarchiv nicht 7 Tage speichern, wie ich es tue, sondern 30, wenn Sie einen solchen Bedarf haben. Also versuchen Sie, passen Sie sich an. Wenn Sie Kommentare zur Arbeit, Fehler oder Vorschläge zur Verbesserung der Funktionalität haben, teilen Sie Ihre Gedanken in den Kommentaren mit, ich freue mich darauf.
Liebe Grüße, liebe Leser meines Blogs. Sie haben wahrscheinlich von einem Programm gehört, mit dem Sie Dateien auf dem Yandex-Server speichern können. Wenn nicht, willkommen bei soft.yandex.ru - es ist da.
Also. Vor ein paar Tagen, als ich die Sites durchstöberte, bin ich zu einem Blog gewandert, in dem ein Skript veröffentlicht wurde, mit dem Sie eine Sicherungskopie der Site auf der Yandex-Festplatte speichern können. In diesem Artikel werde ich ausführlich darüber sprechen.
Zuerst müssen Sie die Adresse des MySQL-Servers ändern. In den meisten Fällen ist dies localhost, also habe ich es dort gelassen, wenn es anders ist, ersetzen wir es durch unser eigenes in der Zeile
$dbhost = "localhost"; // MySQL-Serveradresse.
Ersetzen Sie in der Zeile darunter "database_user" durch Ihren Wert für den MySQL-Datenbank-Benutzernamen.
"database_name" ist der Name der MySQL-Datenbank.
Anstelle von "site_dear_hear" fügen wir unseren Pfad zur Site aus dem Stammverzeichnis der Festplatte ein.
Fahren Sie anschließend mit dem Einrichten der Yandex-Festplatte fort:
Alles. Wir speichern die Datei und laden sie auf den Server hoch.
Ich empfehle nicht, es in das Stammverzeichnis der Site hochzuladen, da alle Arten von Robotern es ständig kontaktieren, wodurch sich die Yandex-Festplatte mit unnötigen Kopien von Backups füllt. Es ist besser, einen Ordner zu erstellen, zum Beispiel "a3hd7siq8a7s9xeeewwwerw-0-032-_2", damit niemand außer Ihnen und Crane weiß, wo Sie ihn haben.
Cran ist ein Taskplaner: ein spezielles Programm, mit dem Sie die Ausführung von Skripten planen können, aber ich weiß nicht, wie man es benutzt, daher kann ich hier nicht helfen.
Sie wissen wahrscheinlich bereits, dass ich fünf Websites habe. Natürlich werden Sie es leid, sie separat auszuführen, aber es ist gut, dass im selben Artikel ein zweites Skript veröffentlicht wurde, das alle anderen Skripte nacheinander startet.
Wenn Sie weniger als fünf Websites haben, entfernen Sie einfach die Zeilen, die wie folgt aussehen:
Echo ""; $ antwort = file_get_contents ("http://site5.ru/beckup.php"); echo iconv ("Windows-1251", "utf-8", $-Antwort);
Wenn Sie eine Site in der .рф-Zone haben, müssen Sie vor der Registrierung der Adresse in Panycode übersetzen.
Ich hoffe, dieser Artikel war hilfreich für Sie.
Ich freue mich auf Ihre Kommentare.
| Verwandte Artikel: | |
|
Adblock Plus Add-on für Mozilla Firefox: Werbung blockieren
Adblock Plus ist die weltweit beliebteste Browseranwendung .... Adblock Plus Add-on für Mozilla Firefox: Werbung blockieren
AdBlock Adblocker für Firefox ist die beliebteste Erweiterung in ... Wie hoch ist die Anfragerate und wie finde ich sie?
Wir haben ein neues Buch veröffentlicht, Social Media Content Marketing: Wie ... | |




