Выбор читателей


Популярные статьи
Яндекс.Диск - один из немногих сервисов Яндекса, частью которого является программное обеспечение для десктопа. И одна из самых важных его составляющих - алгоритм синхронизации локальных файлов с их копией в облаке. Недавно нам пришлось его полностью поменять. Если старая версия с трудом переваривала даже несколько десятков тысяч файлов и к тому же не достаточно быстро реагировала на некоторые «сложные» действия пользователя, то новая, используя те же ресурсы, справляется с сотнями тысяч файлов.
В этом посте я расскажу, почему так получилось: чего мы не смогли предвидеть, когда придумывали первую версию ПО Яндекс.Диска, и как создавали новую.
Прежде всего, о самой задаче синхронизации. Технически говоря, она состоит в том, чтобы в папке Яндекс.Диска на компьютере пользователя и в облаке был один и тот же набор файлов. То есть такие действия пользователя, как переименование, удаление, копирование, добавление и изменение файлов, должны синхронизироваться с облаком автоматически.
Ситуация может стать еще сложнее, если с одним аккаунтом одновременно работают несколько пользователей или у них есть общая папка. А это случается достаточно часто в организациях, использующих Яндекс.Диск. Представьте себе, что в предыдущем примере в тот момент, когда мы получили от бекенда подтверждение первого переименования, другой пользователь берет и переименовывает эту папку еще раз. В этом случае опять нельзя сразу выполнить действия, которые уже совершил первый пользователь у себя на компьютере. Папка, в которой он работал локально, на бекенде в это время уже называется по-другому.
Бывают случаи, когда файл на компьютере пользователя нельзя назвать так же, как он называется в облаке. Это может произойти, если в имени есть символ, который не может использоваться локальной файловой системой, или в том случае, когда пользователя приглашают в общую папку, а у него есть своя папка с таким именем. В таких случаях нам приходится использовать локальные псевдонимы и отслеживать их связь с объектами в облаке.
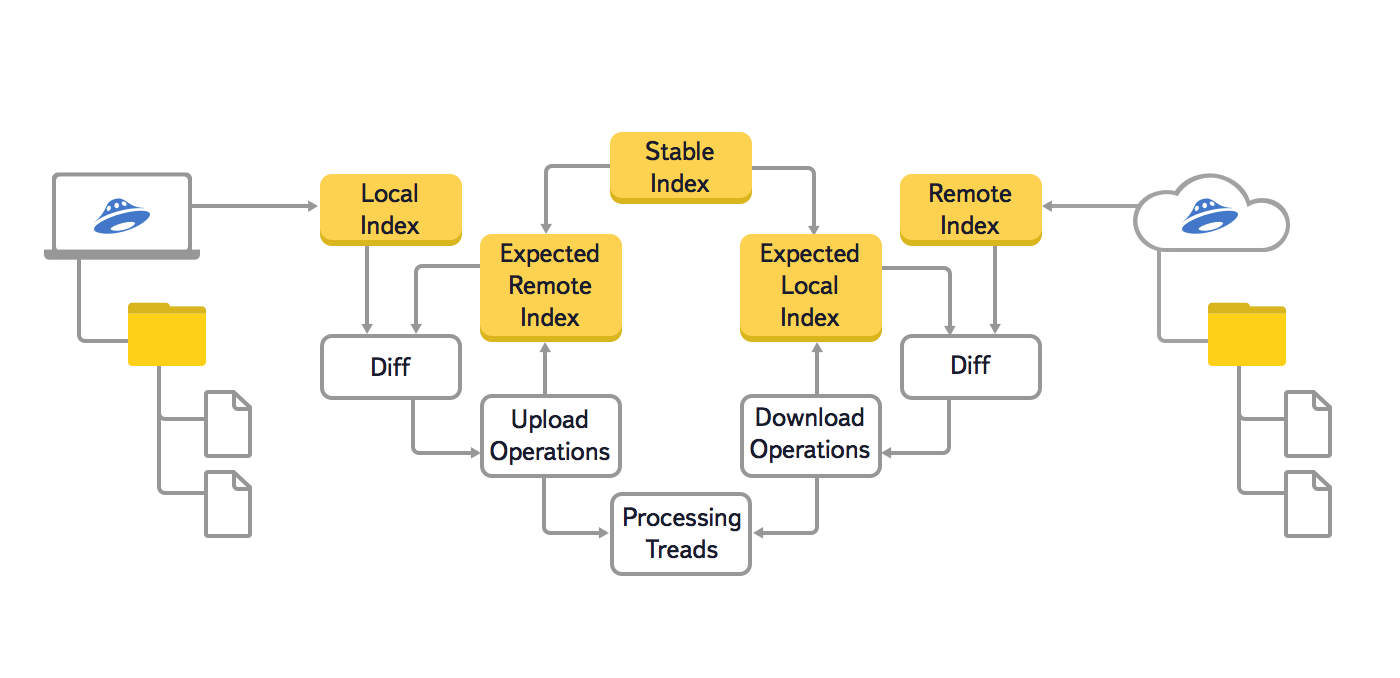
В этой версии алгоритма мы использовали три основных дерева: локальное (Local Index), облачное (Remote Index) и последнее синхронизированное (Stable Index). Кроме этого, чтобы предотвратить повторную генерацию уже поставленных в очередь операций синхронизации, использовались ещё два вспомогательных дерева: локальное ожидаемое и облачное ожидаемое (Expected Remote Index и Expected Local Index). В этих вспомогательных деревьях хранилось ожидаемое состояние локальной файловой системы и облака, после выполнения всех операций синхронизации, которые уже поставлены в очередь.
Также мы хотели увеличить максимальное количество файлов, с которым без проблем может работать пользователь. Несколько десятков и даже сотен тысяч файлов может оказаться, к примеру, у фотографа, который хранит в Яндекс.Диске результаты фотосессий. Эта задача стала особенно актуальной, когда у людей появилась возможность купить дополнительное место на Яндекс.Диске.
В разработке тоже хотелось кое-что поменять. Отладка старой версии вызывала трудности, так как данные о состояниях одного элемента находились в разных деревьях.
К этому времени на бекенде появились id объектов, с помощью которых можно было более эффективно решить задачу обнаружения перемещений - ранее мы использовали пути.
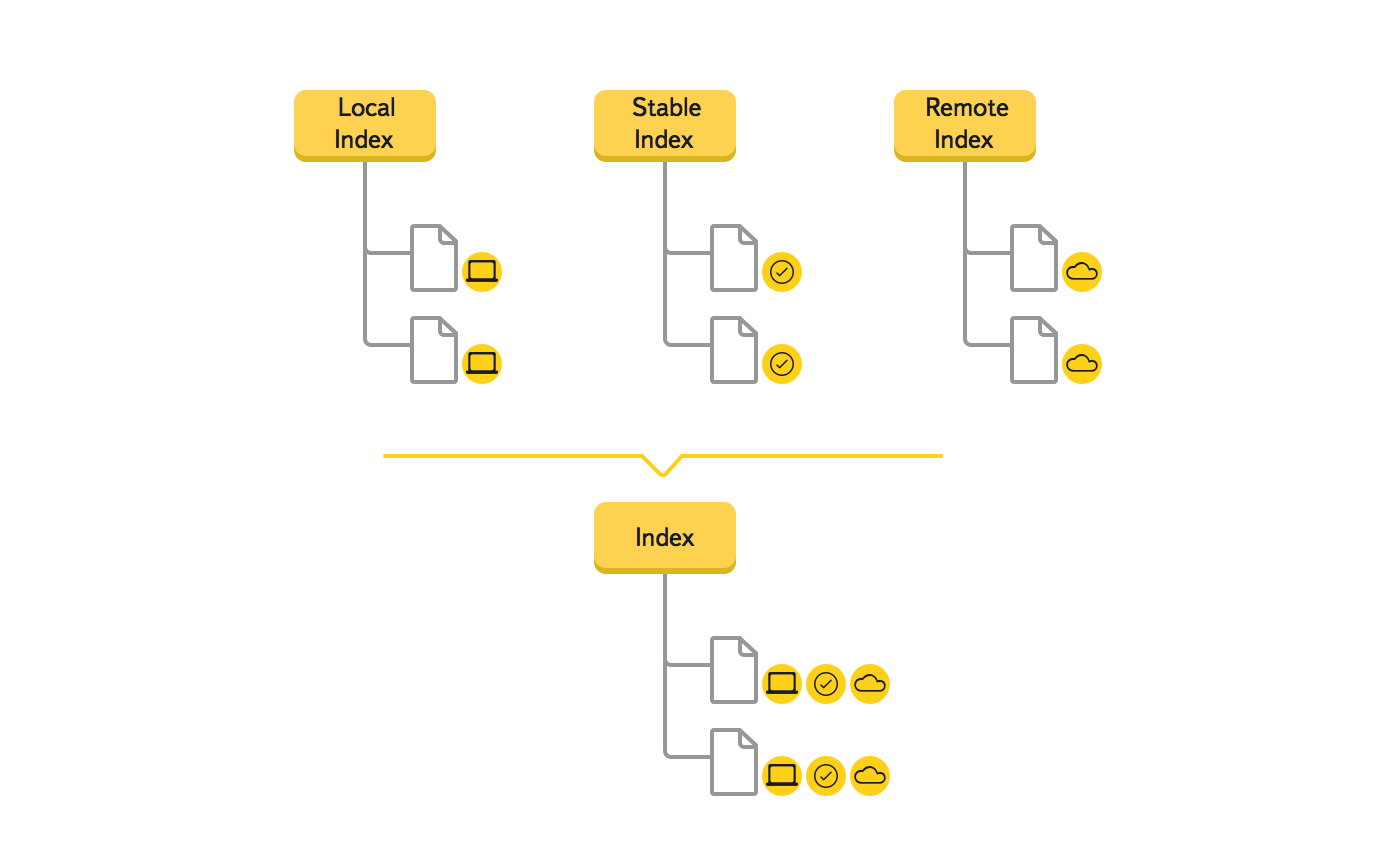
Так как мы понимали, что это серьезное изменение, то создали прототип, подтвердивший эффективность нового решения. Рассмотрим на примере, как меняются данные в дереве во время синхронизации нового файла.

Яндекс.Диск использует дайджесты sha256 и MD5 для проверки целостности файлов, обнаружения изменившихся фрагментов и дедупликации файлов на бекенде. Так как эта задача сильно нагружает CPU, в новой версии реализация расчетов дайджеста была существенно оптимизирована. Скорость получения дайджеста файла увеличена примерно в два раза.
В результате проделанных изменений существенно увеличилось количество файлов, с которым без проблем справляется программа. В версии для Windows – 300 000, а на Mac OS X - 900 000 файлов.
Ни для кого не секрет, для чего нужно производить резервное копирование. Например, веб-разработчику будет удобно делать резервные копии, если в процессе разработки он незаметно для самого себя совершит ошибку, а спустя несколько часов ошибка "всплывёт" на поверхность и на поиски и устранение ошибки времени совсем не осталось. Конечно, у Vscale есть система резервного копирования, но она предусматривает только копирование данных всего сервера целиком. Да и возможность восстановления из резервной копии доступна только на том сервере, из которого и была сделана копия. Такая возможность не совсем удовлетворяет потребности условного веб-разработчика. Однако, сейчас в мире хорошо развилась "облачная" тенденция: облачные хостинг, облачная VPS, облачное хранение данных и так далее. В этом руководстве мы расскажем, как настроить облачное хранение резервных копий. Поможет нам в этом Яндекс.Диск.
Приступим к установке ключевого компонента - клиента для Я.Диска. Поскольку в стандартном списке репозиториев отсутствует пакет с клиентом Я.Диска, придётся добавить репозиторий вручную, после чего обновить индекс пакетов и только потом установить пакет с клиентом. На сайте Я.Диска представлен список нужных команд в одной строке:
echo "deb http://repo.yandex.ru/yandex-disk/deb/ stable main" | sudo tee -a /etc/apt/sources.list .d/yandex.list > /dev/null && wget http://repo.yandex.ru/yandex-disk/YANDEX-DISK-KEY.GPG -O- | sudo apt-key add - && sudo apt-get update && sudo apt-get install -y yandex-diskЯндекс-клиент успешно установлен, и можно приступать к настройке. В Яндексе позаботились о том, чтобы клиент работал с конфигурационными файлами по минимуму и добавили возможность настроить всё одной командой:
Yandex-disk setup
Порядок работы представленной выше команды:
Автозапуск Я.Диска включите обязательно, а остальные пункты можете настраивать по своему усмотрению. На этом настройку можно считать завершённой.
Для того, чтобы создать резервную копию, нужно использовать множество команд. Помочь в этом может python или perl, но удобнее всего это делать при помощи bash. Он прост и удобен в использовании и напрямую взаимодействует с консолью. Создайте bash-скрипт:
Nano /var/backup.sh
Вставьте в него следующий код:
SERVER_PATH="/var/www/html"
cur_date=`date +%Y-%m-%d`
filename="backup-"$cur_date".tar.bz2"
tar -cjf $filename $SERVER_PATH
if [ -f $filename ]; then
mv $filename /root/Yandex.Disk/backup/
yandex-disk sync
fi
Сохраните файл сочетанием клавиш Ctrl+O , подтвердите действие клавишей Enter и закройте файл сочетанием клавиш Ctrl+X . Обязательно назначьте права доступа к файлу, чтобы у него был доступ к системным командам(создание и перемещение папок, доступ к каталогам):
Cd /var
chmod -R 755 * backup.sh
Вкратце о том, что делает скрипт:
Проверить, работает ли скрипт, можно с помощью следующей команды:
Cd /var && ./backup.sh
В результате выполнения команды архив будет загружен в облачное хранилище.
Следующим и завершающим шагом будет добавление скрипта в планировщик задач. Поможет нам в этом crontab. Откройте список запланированных задач:
Crontab -e
В самый конец добавьте строку:
0 0 * * * /var/backup.sh
Теперь Crontab будет запускать скрипт каждый день в полночь. На этом настройка автоматического создания резервной копии завершена.
Вы успешно настроили автоматическое создание резервной копии для директории с вашим веб-сайтом. Это очень полезный алгоритм, позволяющий избежать потерю резервной копии в том случае, если бы она хранилась на самом сервере. По такому же принципу можно делать и резервные копии конфигурационных файлов. В целом облачные технологии хороши тем, что обеспечивают высокую доступность и безопасность хранения личных данных. Выбор в пользу облака - это хороший выбор.
Выкладывать бекапы проектов (сайтов) на Яндекс.Диск может понадобиться по нескольким причинам, например, из-за нехватки места на сервере (хостинге, VDS, VPS) или для повышения безопасности хранения бекапов (на случай, если сервер без рейда и он выйдет из строя).
В связи с этим я написал для себя и решил выложить для других небольшой bash-скрипт для бекапа на Яндекс.Диск. Функции скрипта:
— Создание на сервере бекапа проектов (файлов + баз данных MySQL);
— Авторизация на Яндекс.Диске в качестве приложения (по токену, более безопасный способ, чем использование логина и пароля);
— Отправка бекапов с сервера на Яндекс.Диск;
— Удаление старых бекапов с Яндекс.Диска для экономии места (настраивается максимальное количество хранимых бекапов);
— Запись и отправка лога на e-mail (настраивается).
Для того, чтобы воспользоваться скриптом, необходимо сначала получить токен от Яндекс.Диска. Приступим.
1. Логинимся на Яндексе под аккаунтом, на диск которого будем делать бекап, заходим на oauth.yandex.ru и нажимаем «Зарегистрировать новое приложение».
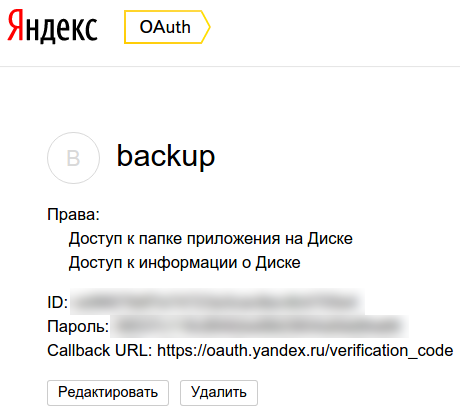
2. Заполняем название приложения (например, «backup») и выдаём нужные права в разделе «Яндекс.Диск REST API», а именно: «Доступ к информации о Диске» и «Доступ к папке приложения на Диске».
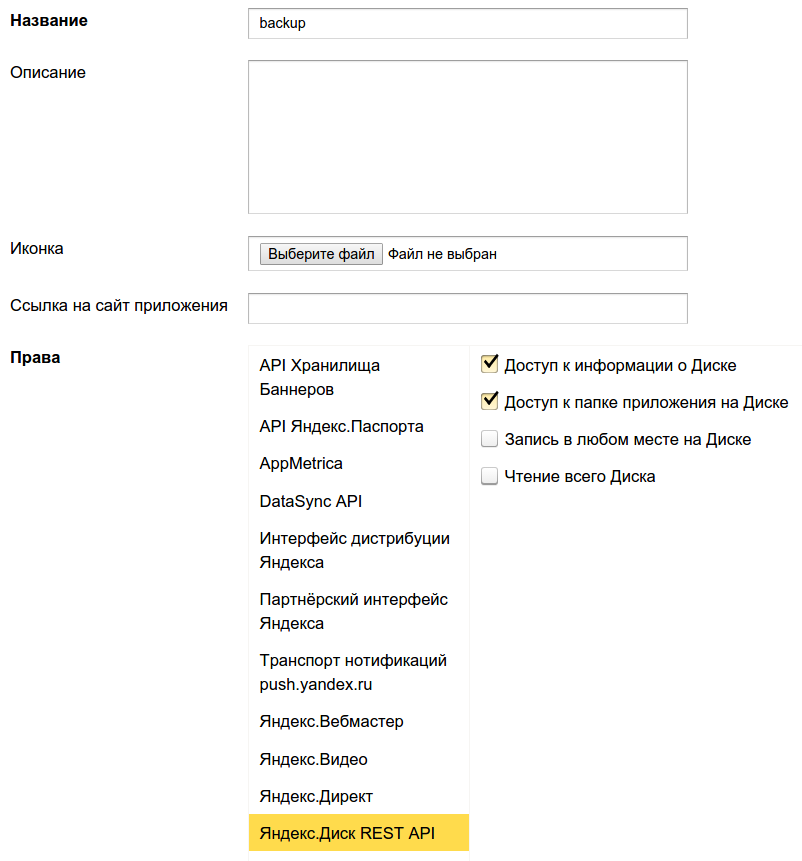
Ниже на той же странице под полем «Callback URL» нажимаем «подставить URL для разработки» и нажимаем «Сохранить»:

3. После сохранения параметров приложения нас перенаправят на страницу с данными о приложении:
4. Теперь получим сам токен (если хотите, можете почитать подробнее об этом в мануале Яндекса), для этого копируем ID, подставляем в конец URL https://oauth.yandex.ru/authorize?response_type=token&client_id= , переходим по получившемуся адресу и подтверждаем выдачу разрешений приложению:
![]()
В итоге на странице будет отображён токен, который выдается не менее, чем на 1 год, поэтому если скрипт бекапа вдруг перестанет работать, мы сможем получить новый токет и подставить его в скрипт. Протестировать возможности работы с Яндекс.Диском, используя полученный токен, можно на специальном полигоне .
А теперь сам bash-скрипт для бекапа на Яндекс.Диск:
#!/bin/bash # # Yandex.Disk backup script v1.0 by Sergey Lukonin (neblog.info) # # # # # # # # # # # НАСТРОЙКИ БЕКАПА MYSQL # # # # # # # # # # # Сервер БД MYSQL_SERVER=mysql.some-server.ru # Юзер, под которым будем делать бекап доступных баз, руту mysql обычно доступны все БД, отдельному пользователю обычно доступна БД конкретного проекта MYSQL_USER=some-user # Пароль пользователя базы данных (Пароль от рута сервера и от рута mysql разные не путайте) MYSQL_PASSWORD=some-password # # # # # # # # # # ОБЩИЕ НАСТРОЙКИ # # # # # # # # # # # Директория для временного хранения бекапов, которые удаляются после отправки на Яндекс..Диске бекапов (0 - хранить все бекапы): MAX_BACKUPS="14" # Дата, используется в именах архивов DATE=`date "+%Y-%m-%d"` # Директории для архивации (указываются через пробел), которые будут помещены в единый архив и отправлены на Яндекс.Диск DIRS="/home/www/projects/neblog" # Yandex.Disk токен (как получить - см. на neblog.info) TOKEN="" # Имя лог-файла, хранится в директории, указанной в $BACKUP_DIR LOGFILE="backup.log" # E-mail для отправки результата выполнения скрипта. Оставьте пустым, если отправлять результаты не требуется. sendLog="[email protected]" # Отправлять только ошибки (true). Укажите false, если нужно отправлять логи при любом результате выполнения скрипта. sendLogErrorsOnly="false" # # # # # # # # # # КОНЕЦ НАСТРОЕК # # # # # # # # # # # # # # # # # # # # # ДАЛЬШЕ НИЧЕГО НЕ МЕНЯЕМ! # # # # # # # # # # function mailing() { if [ ! $sendLog = "" ];then if [ "$sendLogErrorsOnly" == true ]; then if echo "$1" | grep -q "error" then echo "$2" | mail -s "$1" $sendLog > /dev/null fi else echo "$2" | mail -s "$1" $sendLog > /dev/null fi fi } function logger() { echo "["`date "+%Y-%m-%d %H:%M:%S"`"] File $BACKUP_DIR: $1" >> $BACKUP_DIR/$LOGFILE } function parseJson() { local output regex="(\"$1\":[\"]?)([^\",\}]+)([\"]?)" [[ $2 =~ $regex ]] && output=${BASH_REMATCH} echo $output } function checkError() { echo $(parseJson "error" "$1") } function getUploadUrl() { json_out=`curl -s -H "Authorization: OAuth $TOKEN" https://cloud-api.yandex.net:443/v1/disk/resources/upload/?path=app:/$backupName&overwrite=true` json_error=$(checkError "$json_out") if [[ $json_error != "" ]]; then logger "$PROJECT - Yandex.Disk error: $json_error" mailing "$PROJECT - Yandex.Disk backup error" "ERROR copy file $FILENAME. Yandex.Disk error: $json_error" echo "" else output=$(parseJson "href" $json_out) echo $output fi } function uploadFile { local json_out local uploadUrl local json_error uploadUrl=$(getUploadUrl) if [[ $uploadUrl != "" ]]; then echo $UploadUrl json_out=`curl -s -T $1 -H "Authorization: OAuth $TOKEN" $uploadUrl` json_error=$(checkError "$json_out") if [[ $json_error != "" ]]; then logger "$PROJECT - Yandex.Disk error: $json_error" mailing "$PROJECT - Yandex.Disk backup error" "ERROR copy file $FILENAME. Yandex.Disk error: $json_error" else logger "$PROJECT - Copying file to Yandex.Disk success" mailing "$PROJECT - Yandex.Disk backup success" "SUCCESS copy file $FILENAME" fi else echo "Some errors occured. Check log file for detail" fi } function backups_list() { # Ищем в директории приложения все файлы бекапов и выводим их названия: curl -s -H "Authorization: OAuth $TOKEN" "https://cloud-api.yandex.net:443/v1/disk/resources?path=app:/&sort=created&limit=100" | tr "{}," "\n" | grep "name[[:graph:]]*.tar.gz" | cut -d: -f 2 | tr -d """ } function backups_count() { local bkps=$(backups_list | wc -l) # Если мы бекапим и файлы, и БД, то на 1 бекап у нас приходится 2 файла. Поэтому количество бекапов = количество файлов / 2: expr $bkps / 2 } function remove_old_backups() { bkps=$(backups_count) old_bkps=$((bkps - MAX_BACKUPS)) if [ "$old_bkps" -gt "0" ];then logger "Удаляем старые бекапы с Яндекс.Диска" # Цикл удаления старых бекапов: # Выполняем удаление первого в списке файла 2*old_bkps раз for i in `eval echo {1..$((old_bkps * 2))}`; do curl -X DELETE -s -H "Authorization: OAuth $TOKEN" "https://cloud-api.yandex.net:443/v1/disk/resources?path=app:/$(backups_list | awk "(NR == 1)")&permanently=true" done fi } logger "--- $PROJECT START BACKUP $DATE ---" logger "Выгружаем дампы баз" mkdir $BACKUP_DIR/$DATE for i in `mysql -h $MYSQL_SERVER -u $MYSQL_USER -p$MYSQL_PASSWORD -e"show databases;" | grep -v information_schema | grep -v Database`; do mysqldump -h $MYSQL_SERVER -u $MYSQL_USER -p$MYSQL_PASSWORD $i > $BACKUP_DIR/$DATE/$i.sql; done logger "Создаем архив mysql $BACKUP_DIR/$DATE-mysql-$PROJECT.tar.gz" tar -czf $BACKUP_DIR/$DATE-mysql-$PROJECT.tar.gz $BACKUP_DIR/$DATE rm -rf $BACKUP_DIR/$DATE logger "Создаем архив каталогов $BACKUP_DIR/$DATE-files-$PROJECT.tar.gz" tar -czf $BACKUP_DIR/$DATE-files-$PROJECT.tar.gz $DIRS FILENAME=$DATE-mysql-$PROJECT.tar.gz logger "Выгружаем на Яндекс.Диск архив mysql $BACKUP_DIR/$DATE-mysql-$PROJECT.tar.gz" backupName=$DATE-mysql-$PROJECT.tar.gz uploadFile $BACKUP_DIR/$DATE-mysql-$PROJECT.tar.gz FILENAME=$DATE-files-$PROJECT.tar.gz logger "Выгружаем на Яндекс.Диск архив с файлами $BACKUP_DIR/$DATE-files-$PROJECT.tar.gz" backupName=$DATE-files-$PROJECT.tar.gz uploadFile $BACKUP_DIR/$DATE-files-$PROJECT.tar.gz logger "Удаляем архивы с диска" find $BACKUP_DIR -type f -name "*.gz" -exec rm "{}" \; # Удаляем старые бекапы с Яндекс.Диска (если MAX_BACKUPS > 0) if [ $MAX_BACKUPS -gt 0 ];then remove_old_backups; fi logger "Завершение скрипта бекапа"
Также вы можете скачать готовый . Скрипт следует расположить на сервере, заменить в нём параметры на свои, дать права на запуск (chmod +x) и поставить на ежедневное выполнение в cron. Если вы планируете выполнять несколько таких заданий, задайте время между их запуском (5-10 минут).
В современном мире все большую ценность получает информация, потеря которой может обернуться серьезными финансовыми расходами. Сайт является ценной информацией, резервную копию которого, или просто бэкап, мы сделаем в этой статье на примере wordpress и разместим на яндекс диске. Я рассмотрю вариант автоматизации процесса, который придумал для своих нужд и использую достаточно давно и успешно.
Двигаться будем поэтапно. Сначала просто рассмотрим вариант бэкапа непосредственно файлов сайта и базы данных. А затем полностью ответим на вопрос о том как сделать регулярную резервную копию сайта на wordpress .
Тут я не изобретал велосипеда, а воспользовался стандартным способом архивирования файлов — архиватором tar . Все комментарии и пояснения напишу сразу в скрипте:
#!/bin/sh # Задаем переменные # Текущая дата в формате 2015-09-29_04-10 date_time=`date +"%Y-%m-%d_%H-%M"` # Куда размещаем backup bk_dir="/mnt/backup/site1.ru" # Директория на уровень выше той, где лежат файлы inf_dir="/web/sites/site1.ru/" # Название непосредственно директории с файлами dir_to_bk="www" # Создание архива /usr/bin/tar -czvf $bk_dir/www_$date_time.tar.gz -C $inf_dir $dir_to_bk
На выходе после работы скрипта имеем папку с именем www_2015-09-29_04-10.tar.gz , внутри которой будет лежать папка www со всем содержимым. Изначально, эта папка располагалась по адресу /web/sites/site1.ru/www. Здесь я применил tar с параметром -С для того, чтобы в архиве не было точного пути /web/sites/site1.ru, а была только папка www. Мне просто так удобнее.
Можно пользоваться отдельно этим скриптом для создания архивов файлов, не обязательно сайта. Кладем его в cron и получаем регулярную архивацию.
Теперь сделаем скрипт для резервной копии базы данных. Тут тоже ничего особенного, использую стандартное средство mysqldamp :
#!/bin/sh # Задаем переменные # Текущая дата в формате 2015-09-29_04-10 date_time=`date +"%Y-%m-%d_%H-%M"` # Куда размещаем backup bk_dir="/mnt/backup/site1.ru" # Пользователь базы данных user="user1" # Пароль пользователя password="pass1" # Имя базы для бэкапа bd_name="bd1" # Выгружаем базу /usr/bin/mysqldump --opt -v --databases $bd_name -u$user -p$password | /usr/bin/gzip -c > $bk_dir/mysql_$date_time.sql.gz
На выходе имеем файл с дампом базы mysql_2015-09-29_04-10.sql.gz . Дамп хранится в текстовом формате, можно открывать и редактировать любым редактором.
Существует достаточно удобный и бесплатный сервис Я ндекс.Диск, который может использовать любой желающий. Бесплатно дается не так много места, но для бэкапа сайта на wordpress хватит. К слову, у меня с помощью всевозможных акций бесплатно доступно 368 ГБ:
Я ндекс.Диск можно подключить с помощью webdav . У меня в качестве сервера выступает CentOS 7, я расскажу как подмонтировать в ней. Первым делом подключаем . Затем устанавливаем пакет davfs2 :
# yum -y install davfs2
Теперь пробуем подмонтировать диск:
# mkdir /mnt/yadisk # mount -t davfs https://webdav.yandex.ru /mnt/yadisk/ Please enter the username to authenticate with server https://webdav.yandex.ru or hit enter for none. Username: Please enter the password to authenticate user [email protected] with server https://webdav.yandex.ru or hit enter for none. Password: /sbin/mount.davfs: Warning: can"t write entry into mtab, but will mount the file system anyway
Я ндекс.Диск смонтирован в папку /mnt/yadisk.
Чтобы автоматизировать процесс архивации и не вводить каждый раз имя пользователя и пароль, отредактируем файл /etc/davfs2/secrets, добавив в конец новую строку с именем пользователя и паролем:
# mcedit /etc/davfs2/secrets /mnt/yadisk/ [email protected] password
Теперь при монтировании диска никаких вопросов задаваться не будет. Можно добавить подключение яндекс диска в fstab , чтобы он монтировался автоматически при загрузке, но я считаю это лишним. Я подключаю и отключаю диск в скрипте бэкапа. Если же вы хотите его монтировать автоматически, добавьте в fstab:
Https://webdav.yandex.ru /mnt/yadisk davfs rw,user,_netdev 0 0
По отдельности разобрали все элементы создания резервной копии сайта, теперь пришел черед собрать все это в одном месте. Я использую следующую схему бэкапа сайта:
С такой схемой мы всегда имеем под рукой 7 последних архивов, недельные архивы текущего месяца и архив за каждый месяц на всякий случай. Пару раз меня такая схема выручала, когда нужно было что-то достать из бэкапа недельной давности, к примеру.
Привожу 3 полных скрипта по созданию резервной копии сайта wordpress, именно этот движок я чаще всего использую, но реально можно бэкапить любой сайт — joomla, drupal, modx и др. Принципиального значения cms или фреймворк не имеет.
Скрипт ежедневного бэкапа сайта backup-day.sh :
day " # Директория для архива inf_dir="/web/sites/site1.ru/" # Название непосредственно директории с файлами dir_to_bk="www" # Пользователь базы данных user="user1" # Пароль пользователя password="pass1" # Имя базы для бэкапа bd_name="bd1" # Монтируем яндекс.диск mount -t davfs https://webdav.yandex.ru /mnt/yadisk/ # Создание архива исходников /usr/bin/tar -czvf $bk_dir/www_$date_time.tar.gz -C $inf_dir $dir_to_bk # Выгружаем базу данных /usr/bin/mysqldump --opt -v --databases $bd_name -u$user -p$password | /usr/bin/gzip -c > $bk_dir/mysql_$date_time.sql.gz # Удаляем архивы старше 7-ми дней /usr/bin/find $bk_dir -type f -mtime +7
Скрипт еженедельного бэкапа сайта backup-week.sh :
#!/bin/sh # Задаем переменные # Текущая дата в формате 2015-09-29_04-10 date_time=`date +"%Y-%m-%d_%H-%M"` # Куда размещаем backup bk_dir="/mnt/yadisk/site1.ru/weeek " # Директория для архива inf_dir="/web/sites/site1.ru/" # Название непосредственно директории с файлами dir_to_bk="www" # Пользователь базы данных user="user1" # Пароль пользователя password="pass1" # Имя базы для бэкапа bd_name="bd1" # Монтируем яндекс.диск mount -t davfs https://webdav.yandex.ru /mnt/yadisk/ # Создание архива исходников /usr/bin/tar -czvf $bk_dir/www_$date_time.tar.gz -C $inf_dir $dir_to_bk # Выгружаем базу данных /usr/bin/mysqldump --opt -v --databases $bd_name -u$user -p$password | /usr/bin/gzip -c > $bk_dir/mysql_$date_time.sql.gz # Удаляем архивы старше 30-ти дней /usr/bin/find $bk_dir -type f -mtime +30 -exec rm {} \; # Отключаем яндекс.диск umount /mnt/yadisk
Скрипт ежемесячного бэкапа сайта backup-month.sh :
#!/bin/sh # Задаем переменные # Текущая дата в формате 2015-09-29_04-10 date_time=`date +"%Y-%m-%d_%H-%M"` # Куда размещаем backup bk_dir="/mnt/yadisk/site1.ru/month " # Директория для архива inf_dir="/web/sites/site1.ru/" # Название непосредственно директории с файлами dir_to_bk="www" # Пользователь базы данных user="user1" # Пароль пользователя password="pass1" # Имя базы для бэкапа bd_name="bd1" # Монтируем яндекс.диск mount -t davfs https://webdav.yandex.ru /mnt/yadisk/ # Создание архива исходников /usr/bin/tar -czvf $bk_dir/www_$date_time.tar.gz -C $inf_dir $dir_to_bk # Выгружаем базу данных /usr/bin/mysqldump --opt -v --databases $bd_name -u$user -p$password | /usr/bin/gzip -c > $bk_dir/mysql_$date_time.sql.gz # Отключаем яндекс.диск umount /mnt/yadisk
Не забудьте создать директорию /mnt/yadisk/site1.ru на яндекс диске, а в ней еще 3 папки: day, week, month: # cd /mnt/yadisk/site1.ru && mkdir day week month
Теперь для автоматизации добавляем эти 3 файла в cron :
# mcedit /etc/crontab # site backup to yandex.disk # ежедневно в 4:10 10 4 * * * root /root/bin/backup-day.sh >/dev/null 2>&1 # еженедельно в 4:20 в воскресенье 20 4 * * 0 root /root/bin/backup-week.sh >/dev/null 2>&1 # ежемесячно в 4:30 1-го числа месяца 30 4 1 * * root /root/bin/backup-month.sh >/dev/null 2>&1
Все, наш wordpress надежно забэкаплен. По идее, сюда нужно прикрутить оповещение на почту, но у меня всю руки не доходят это сделать. Да и за несколько месяцев использования у меня не было ни одного сбоя.
Теперь рассмотрим вариант, когда вам необходимо восстановить сайт из резервной копии. Для этого нам понадобятся оба архива: исходники и база данных. Разархивировать в принципе можно где угодно. В windows архивы открываются бесплатным архиватором 7zip. Дамп базы данных в обычном текстовом формате, его можно открыть блокнотом, скопировать и вставить в phpmyadmin.

Так что вариантов восстановления может быть много, этим мне и нравится такой подход. Все файлы в открытом виде, с ними можно работать любыми подручными средствами.
Вот пример того, как извлечь файлы из архива в консоли сервера. Разархивируем каталог www из бэкапа:
# tar -xzvf www_2015-10-01_04-10.tar.gz
Файлы извлечены в папку www. Теперь их можно скопировать в папку с сайтом.
Для восстановления базы данных поступаем следующим образом. Сначала распакуем архив:
# gunzip mysql_2015-10-01_04-10.sql.gz
Теперь зальем дамп в базу данных:
# mysql --host=localhost --user=user1 --password=pass1 bd1; MariaDB [(none)]> source mysql_2015-10-01_04-10.sql;
Все, база данных восстановлена.
Необходимо учесть, что база будет восстановлена в базу с оригинальным именем и заменит ее содержимое, если таковая на сервере есть. Чтобы восстановить базу в другую, необходимо отредактировать начало дампа и заменить там название базы на новое. Если восстановление происходит на другом сервере, то это не имеет значения.
Итак, мы рассмотрели варианты создания резервных копий сайта и базы данных на примере движка wordpress. При этом использовали только стандартные средства сервера. В качестве примера мы использовали приемник для хранения копий Я ндекс.Диск, но ничто не мешает адаптировать его под любой другой. Это может быть отдельный жесткий или внешний диск, другое облачное хранилище данных, которое можно подмонтировать к серверу.
Схема создания бэкапа позволяет откатиться практически на неограниченное время назад. Глубину архивов вы можете сами задавать, изменяя параметр mtime в скрипте. Можно хранить, к примеру, ежедневный архив не 7 дней, как делаю я, а 30, если у вас есть такая потребность. Так что пробуйте, адаптируйте под себя. Если есть какие-то замечания по работе, ошибки или предложения по улучшению функционала, делитесь своими мыслями в комментариях, буду рад их услышать.
Приветствую вас, дорогие читатели моего блога. Вы, наверное, слышали о программе, позволяющей хранить файлы на сервере Яндекса. Если нет, добро пожаловать на soft.yandex.ru - она там есть.
Так вот. Несколько дней назад, когда я просматривал сайты, забрёл на блог, на котором был опубликован скрипт, позволяющий сохранять резервную копию сайта на Яндекс диск. В этой статье я подробно расскажу о нём.
Сначала надо изменить адрес mysql сервера. В большинстве случаев это localhost, поэтому я там его и оставил, если же другой, заменяем его на свой в строке
$dbhost = "localhost"; //Адрес MySQL сервера.
В строчке ниже, заменяем "database_user" на своё значение имени пользователя базы данных mysql.
"database_name" - на название базы данных mysql.
Вместо "site_dear_hear" вставляем свой путь к сайту от корня диска.
После этого, переходим к настройке Яндекс диска:
Всё. Сохраняем файл и загружаем на сервер.
Не рекомендую его загружать в корневой каталог сайта, потому что будут постоянно обращаться к нему всякие роботы, из-за чего Яндекс диск будет заполняться лишними копиями бекапов. Лучше создать папку, например "a3hd7siq8a7s9xeeewwwerw-0-032-_2", чтобы никто, кроме вас и cran не знал, где он у вас.
Cran - это планировщик заданий: специальная программа, при помощи которой вы можете ставить запуск скриптов по расписанию, но как им пользоваться не знаю, поэтому здесь помочь не смогу.
Вы, наверное, уже знаете, что у меня пять сайтов. Естественно, запускать их отдельно устанешь, но хорошо, что в той же статье был размещён второй скрипт, который запускает по очереди все остальные скрипты.
Если у вас меньше пяти сайтов, просто удалите строки, имеющие вид:
Echo " "; $response = file_get_contents("http://site5.ru/beckup.php"); echo iconv("Windows-1251", "utf-8", $response);
Если у вас сайт в зоне.рф, вам, перед тем, как прописывать адрес, придётся переводить в Panycode
Надеюсь, что статья вам была полезна.
Жду комментариев.
| Статьи по теме: | |
|
Прошивка планшета Билайн М2 Планшет билайн м2 прошивка 4
После первого появления планшета на рынке компьютерных устройств, не... Партнёрская программа AliExpress: как заработать на ePN в России
Похожие бизнес-идеи: Люди давно научились зарабатывать с помощью... Pillars of Eternity - Системные требования Пилларс оф этернити системные требования
Pillars of Eternity игра которая имеет уже свою историю и начало ее... | |